 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVGGT: Multimodal Visual Geometry Grounded Transformer for Multiview 3D Referring Expression Segmentation
Jan 13, 2026Most existing 3D referring expression segmentation (3DRES) methods rely on dense, high-quality point clouds, while real-world agents such as robots and mobile phones operate with only a few sparse RGB views and strict latency constraints. We introduce Multi-view 3D Referring Expression Segmentation (MV-3DRES), where the model must recover scene structure and segment the referred object directly from sparse multi-view images. Traditional two-stage pipelines, which first reconstruct a point cloud and then perform segmentation, often yield low-quality geometry, produce coarse or degraded target regions, and run slowly. We propose the Multimodal Visual Geometry Grounded Transformer (MVGGT), an efficient end-to-end framework that integrates language information into sparse-view geometric reasoning through a dual-branch design. Training in this setting exposes a critical optimization barrier, termed Foreground Gradient Dilution (FGD), where sparse 3D signals lead to weak supervision. To resolve this, we introduce Per-view No-target Suppression Optimization (PVSO), which provides stronger and more balanced gradients across views, enabling stable and efficient learning. To support consistent evaluation, we build MVRefer, a benchmark that defines standardized settings and metrics for MV-3DRES. Experiments show that MVGGT establishes the first strong baseline and achieves both high accuracy and fast inference, outperforming existing alternatives. Code and models are publicly available at https://mvggt.github.io.
DocFusion: A Unified Framework for Document Parsing Tasks
Dec 17, 2024



Document parsing is essential for analyzing complex document structures and extracting fine-grained information, supporting numerous downstream applications. However, existing methods often require integrating multiple independent models to handle various parsing tasks, leading to high complexity and maintenance overhead. To address this, we propose DocFusion, a lightweight generative model with only 0.28B parameters. It unifies task representations and achieves collaborative training through an improved objective function. Experiments reveal and leverage the mutually beneficial interaction among recognition tasks, and integrating recognition data significantly enhances detection performance. The final results demonstrate that DocFusion achieves state-of-the-art (SOTA) performance across four key tasks.
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
Apr 17, 2023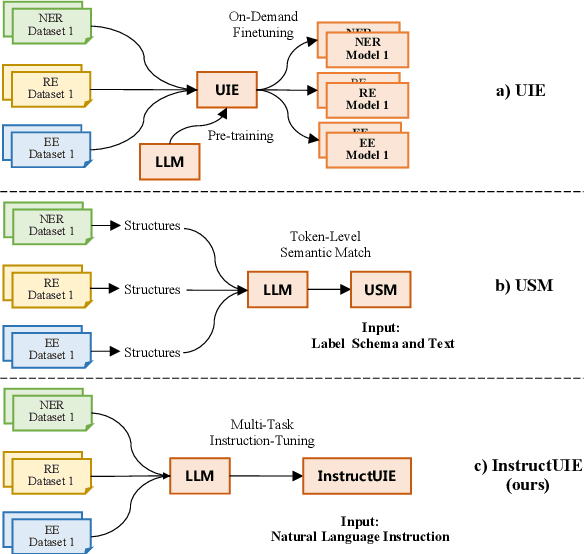
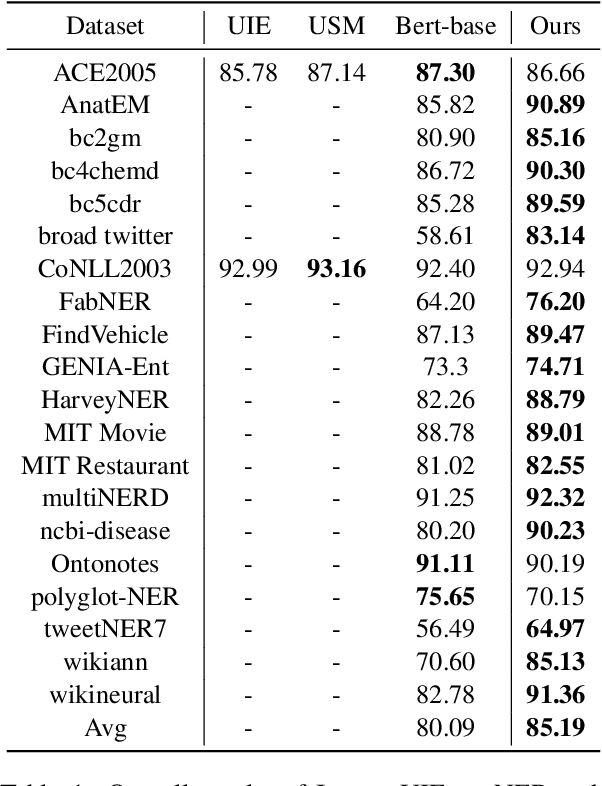
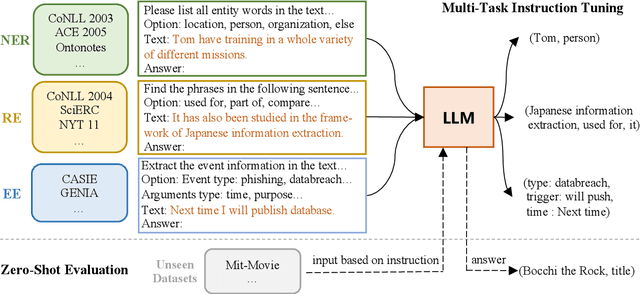
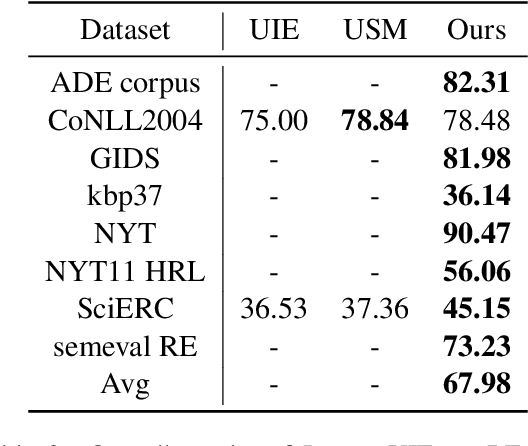
Large language models have unlocked strong multi-task capabilities from reading instructive prompts. However, recent studies have shown that existing large models still have difficulty with information extraction tasks. For example, gpt-3.5-turbo achieved an F1 score of 18.22 on the Ontonotes dataset, which is significantly lower than the state-of-the-art performance. In this paper, we propose InstructUIE, a unified information extraction framework based on instruction tuning, which can uniformly model various information extraction tasks and capture the inter-task dependency. To validate the proposed method, we introduce IE INSTRUCTIONS, a benchmark of 32 diverse information extraction datasets in a unified text-to-text format with expert-written instructions. Experimental results demonstrate that our method achieves comparable performance to Bert in supervised settings and significantly outperforms the state-of-the-art and gpt3.5 in zero-shot settings.