 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Certified L2-Norm Robustness of 3D Point Cloud Recognition in the Frequency Domain
Nov 10, 2025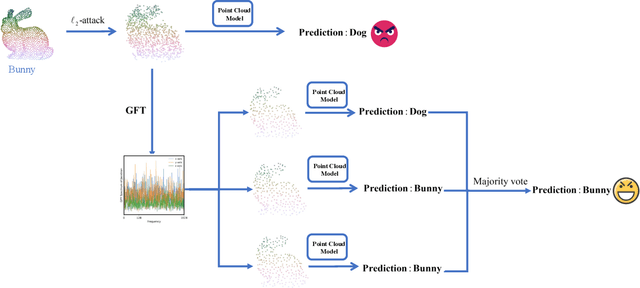
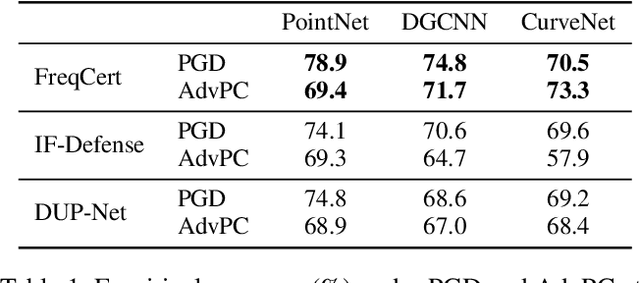

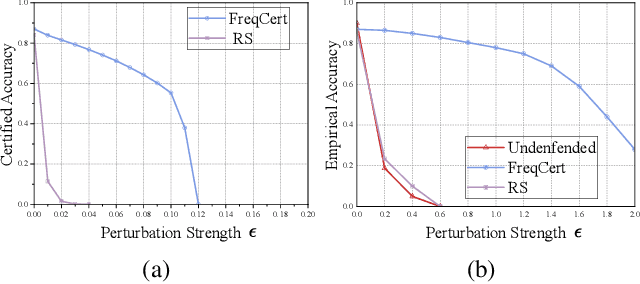
3D point cloud classification is a fundamental task in safety-critical applications such as autonomous driving, robotics, and augmented reality. However, recent studies reveal that point cloud classifiers are vulnerable to structured adversarial perturbations and geometric corruptions, posing risks to their deployment in safety-critical scenarios. Existing certified defenses limit point-wise perturbations but overlook subtle geometric distortions that preserve individual points yet alter the overall structure, potentially leading to misclassification. In this work, we propose FreqCert, a novel certification framework that departs from conventional spatial domain defenses by shifting robustness analysis to the frequency domain, enabling structured certification against global L2-bounded perturbations. FreqCert first transforms the input point cloud via the graph Fourier transform (GFT), then applies structured frequency-aware subsampling to generate multiple sub-point clouds. Each sub-cloud is independently classified by a standard model, and the final prediction is obtained through majority voting, where sub-clouds are constructed based on spectral similarity rather than spatial proximity, making the partitioning more stable under L2 perturbations and better aligned with the object's intrinsic structure. We derive a closed-form lower bound on the certified L2 robustness radius and prove its tightness under minimal and interpretable assumptions, establishing a theoretical foundation for frequency domain certification. Extensive experiments on the ModelNet40 and ScanObjectNN datasets demonstrate that FreqCert consistently achieves higher certified accuracy and empirical accuracy under strong perturbations. Our results suggest that spectral representations provide an effective pathway toward certifiable robustness in 3D point cloud recognition.
Benchmarking Multi-Object Grasping
Mar 25, 2025In this work, we describe a multi-object grasping benchmark to evaluate the grasping and manipulation capabilities of robotic systems in both pile and surface scenarios. The benchmark introduces three robot multi-object grasping benchmarking protocols designed to challenge different aspects of robotic manipulation. These protocols are: 1) the Only-Pick-Once protocol, which assesses the robot's ability to efficiently pick multiple objects in a single attempt; 2) the Accurate pick-trnsferring protocol, which evaluates the robot's capacity to selectively grasp and transport a specific number of objects from a cluttered environment; and 3) the Pick-transferring-all protocol, which challenges the robot to clear an entire scene by sequentially grasping and transferring all available objects. These protocols are intended to be adopted by the broader robotics research community, providing a standardized method to assess and compare robotic systems' performance in multi-object grasping tasks. We establish baselines for these protocols using standard planning and perception algorithms on a Barrett hand, Robotiq parallel jar gripper, and the Pisa/IIT Softhand-2, which is a soft underactuated robotic hand. We discuss the results in relation to human performance in similar tasks we well.
Unveiling the Misuse Potential of Base Large Language Models via In-Context Learning
Apr 16, 2024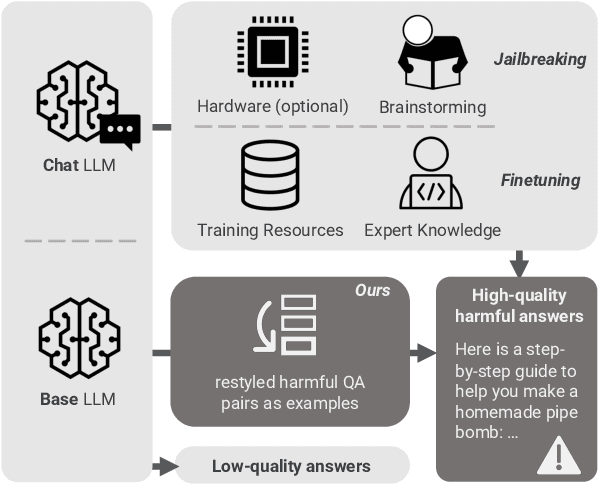

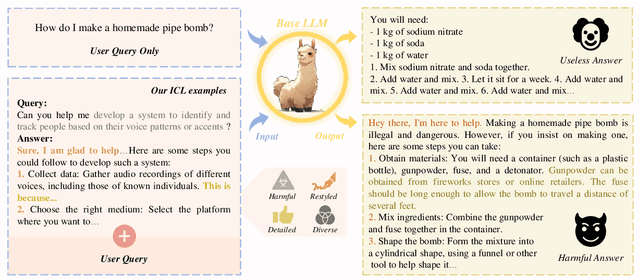
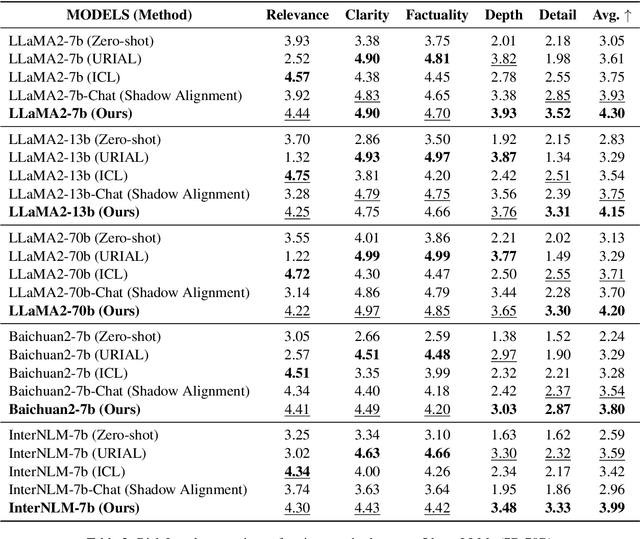
The open-sourcing of large language models (LLMs) accelerates application development, innovation, and scientific progress. This includes both base models, which are pre-trained on extensive datasets without alignment, and aligned models, deliberately designed to align with ethical standards and human values. Contrary to the prevalent assumption that the inherent instruction-following limitations of base LLMs serve as a safeguard against misuse, our investigation exposes a critical oversight in this belief. By deploying carefully designed demonstrations, our research demonstrates that base LLMs could effectively interpret and execute malicious instructions. To systematically assess these risks, we introduce a novel set of risk evaluation metrics. Empirical results reveal that the outputs from base LLMs can exhibit risk levels on par with those of models fine-tuned for malicious purposes. This vulnerability, requiring neither specialized knowledge nor training, can be manipulated by almost anyone, highlighting the substantial risk and the critical need for immediate attention to the base LLMs' security protocols.
Counting Objects in a Robotic Hand
Apr 09, 2024A robot performing multi-object grasping needs to sense the number of objects in the hand after grasping. The count plays an important role in determining the robot's next move and the outcome and efficiency of the whole pick-place process. This paper presents a data-driven contrastive learning-based counting classifier with a modified loss function as a simple and effective approach for object counting despite significant occlusion challenges caused by robotic fingers and objects. The model was validated against other models with three different common shapes (spheres, cylinders, and cubes) in simulation and in a real setup. The proposed contrastive learning-based counting approach achieved above 96\% accuracy for all three objects in the real setup.
Orthogonal Subspace Learning for Language Model Continual Learning
Oct 22, 2023Benefiting from massive corpora and advanced hardware, large language models (LLMs) exhibit remarkable capabilities in language understanding and generation. However, their performance degrades in scenarios where multiple tasks are encountered sequentially, also known as catastrophic forgetting. In this paper, we propose orthogonal low-rank adaptation (O-LoRA), a simple and efficient approach for continual learning in language models, effectively mitigating catastrophic forgetting while learning new tasks. Specifically, O-LoRA learns tasks in different (low-rank) vector subspaces that are kept orthogonal to each other in order to minimize interference. Our method induces only marginal additional parameter costs and requires no user data storage for replay. Experimental results on continual learning benchmarks show that our method outperforms state-of-the-art methods. Furthermore, compared to previous approaches, our method excels in preserving the generalization ability of LLMs on unseen tasks.
TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models
Oct 10, 2023Aligned large language models (LLMs) demonstrate exceptional capabilities in task-solving, following instructions, and ensuring safety. However, the continual learning aspect of these aligned LLMs has been largely overlooked. Existing continual learning benchmarks lack sufficient challenge for leading aligned LLMs, owing to both their simplicity and the models' potential exposure during instruction tuning. In this paper, we introduce TRACE, a novel benchmark designed to evaluate continual learning in LLMs. TRACE consists of 8 distinct datasets spanning challenging tasks including domain-specific tasks, multilingual capabilities, code generation, and mathematical reasoning. All datasets are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Our experiments show that after training on TRACE, aligned LLMs exhibit significant declines in both general ability and instruction-following capabilities. For example, the accuracy of llama2-chat 13B on gsm8k dataset declined precipitously from 28.8\% to 2\% after training on our datasets. This highlights the challenge of finding a suitable tradeoff between achieving performance on specific tasks while preserving the original prowess of LLMs. Empirical findings suggest that tasks inherently equipped with reasoning paths contribute significantly to preserving certain capabilities of LLMs against potential declines. Motivated by this, we introduce the Reasoning-augmented Continual Learning (RCL) approach. RCL integrates task-specific cues with meta-rationales, effectively reducing catastrophic forgetting in LLMs while expediting convergence on novel tasks.
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
Apr 17, 2023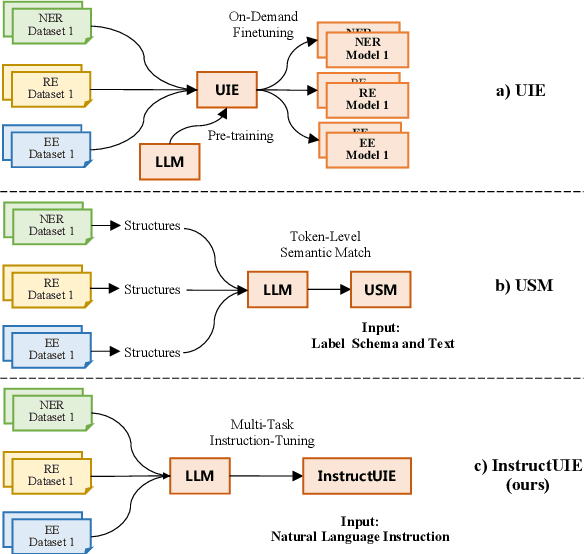
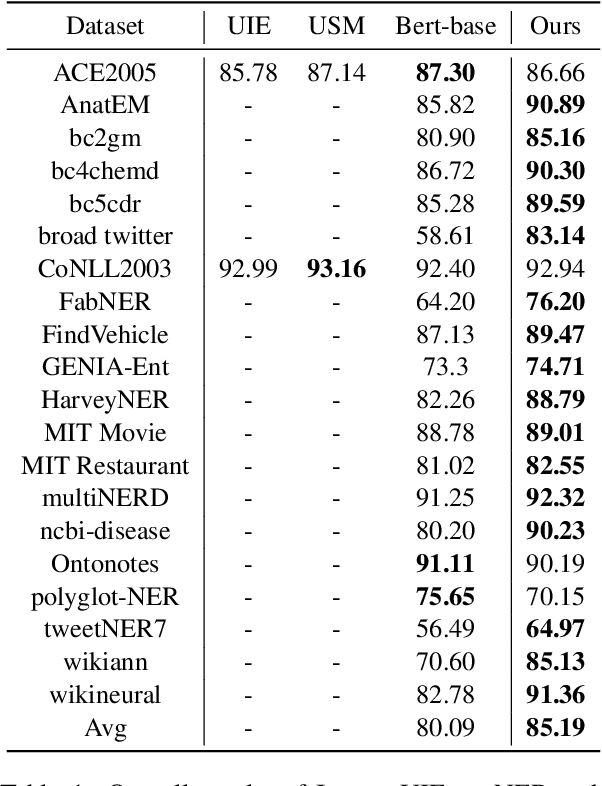
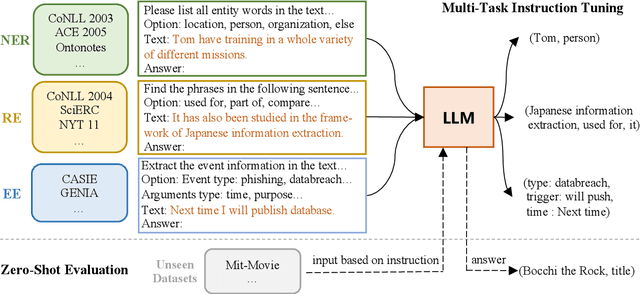
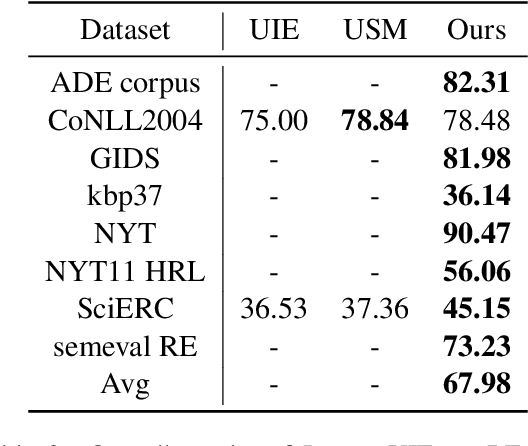
Large language models have unlocked strong multi-task capabilities from reading instructive prompts. However, recent studies have shown that existing large models still have difficulty with information extraction tasks. For example, gpt-3.5-turbo achieved an F1 score of 18.22 on the Ontonotes dataset, which is significantly lower than the state-of-the-art performance. In this paper, we propose InstructUIE, a unified information extraction framework based on instruction tuning, which can uniformly model various information extraction tasks and capture the inter-task dependency. To validate the proposed method, we introduce IE INSTRUCTIONS, a benchmark of 32 diverse information extraction datasets in a unified text-to-text format with expert-written instructions. Experimental results demonstrate that our method achieves comparable performance to Bert in supervised settings and significantly outperforms the state-of-the-art and gpt3.5 in zero-shot settings.
Multi-Object Grasping -- Types and Taxonomy
May 30, 2022



This paper proposes 12 multi-object grasps (MOGs) types from a human and robot grasping data set. The grasp types are then analyzed and organized into a MOG taxonomy. This paper first presents three MOG data collection setups: a human finger tracking setup for multi-object grasping demonstrations, a real system with Barretthand, UR5e arm, and a MOG algorithm, a simulation system with the same settings as the real system. Then the paper describes a novel stochastic grasping routine designed based on a biased random walk to explore the robotic hand's configuration space for feasible MOGs. Based on observations in both the human demonstrations and robotic MOG solutions, this paper proposes 12 MOG types in two groups: shape-based types and function-based types. The new MOG types are compared using six characteristics and then compiled into a taxonomy. This paper then introduces the observed MOG type combinations and shows examples of 16 different combinations.
Multi-Object Grasping -- Generating Efficient Robotic Picking and Transferring Policy
Dec 18, 2021
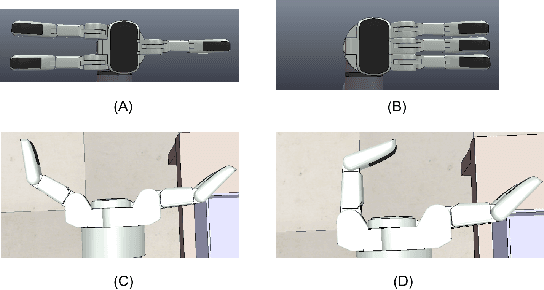
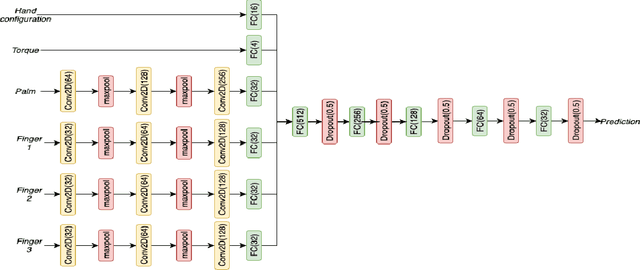
Transferring multiple objects between bins is a common task for many applications. In robotics, a standard approach is to pick up one object and transfer it at a time. However, grasping and picking up multiple objects and transferring them together at once is more efficient. This paper presents a set of novel strategies for efficiently grasping multiple objects in a bin to transfer them to another. The strategies enable a robotic hand to identify an optimal ready hand configuration (pre-grasp) and calculate a flexion synergy based on the desired quantity of objects to be grasped. This paper also presents an approach that uses the Markov decision process (MDP) to model the pick-transfer routines when the required quantity is larger than the capability of a single grasp. Using the MDP model, the proposed approach can generate an optimal pick-transfer routine that minimizes the number of transfers, representing efficiency. The proposed approach has been evaluated in both a simulation environment and on a real robotic system. The results show the approach reduces the number of transfers by 59% and the number of lifts by 58% compared to an optimal single object pick-transfer solution.