 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTF-Lane: Traffic Flow Module for Robust Lane Perception
Feb 01, 2026Autonomous driving systems require robust lane perception capabilities, yet existing vision-based detection methods suffer significant performance degradation when visual sensors provide insufficient cues, such as in occluded or lane-missing scenarios. While some approaches incorporate high-definition maps as supplementary information, these solutions face challenges of high subscription costs and limited real-time performance. To address these limitations, we explore an innovative information source: traffic flow, which offers real-time capabilities without additional costs. This paper proposes a TrafficFlow-aware Lane perception Module (TFM) that effectively extracts real-time traffic flow features and seamlessly integrates them with existing lane perception algorithms. This solution originated from real-world autonomous driving conditions and was subsequently validated on open-source algorithms and datasets. Extensive experiments on four mainstream models and two public datasets (Nuscenes and OpenLaneV2) using standard evaluation metrics show that TFM consistently improves performance, achieving up to +4.1% mAP gain on the Nuscenes dataset.
LSRIF: Logic-Structured Reinforcement Learning for Instruction Following
Jan 10, 2026Instruction-following is critical for large language models, but real-world instructions often contain logical structures such as sequential dependencies and conditional branching. Existing methods typically construct datasets with parallel constraints and optimize average rewards, ignoring logical dependencies and yielding noisy signals. We propose a logic-structured training framework LSRIF that explicitly models instruction logic. We first construct a dataset LSRInstruct with constraint structures such as parallel, sequential, and conditional types, and then design structure-aware rewarding method LSRIF including average aggregation for parallel structures, failure-penalty propagation for sequential structures, and selective rewards for conditional branches. Experiments show LSRIF brings significant improvements in instruction-following (in-domain and out-of-domain) and general reasoning. Analysis reveals that learning with explicit logic structures brings parameter updates in attention layers and sharpens token-level attention to constraints and logical operators.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Inverse-Q*: Token Level Reinforcement Learning for Aligning Large Language Models Without Preference Data
Aug 27, 2024Reinforcement Learning from Human Feedback (RLHF) has proven effective in aligning large language models with human intentions, yet it often relies on complex methodologies like Proximal Policy Optimization (PPO) that require extensive hyper-parameter tuning and present challenges in sample efficiency and stability. In this paper, we introduce Inverse-Q*, an innovative framework that transcends traditional RL methods by optimizing token-level reinforcement learning without the need for additional reward or value models. Inverse-Q* leverages direct preference optimization techniques but extends them by estimating the conditionally optimal policy directly from the model's responses, facilitating more granular and flexible policy shaping. Our approach reduces reliance on human annotation and external supervision, making it especially suitable for low-resource settings. We present extensive experimental results demonstrating that Inverse-Q* not only matches but potentially exceeds the effectiveness of PPO in terms of convergence speed and the alignment of model responses with human preferences. Our findings suggest that Inverse-Q* offers a practical and robust alternative to conventional RLHF approaches, paving the way for more efficient and adaptable model training approaches.
EasyJailbreak: A Unified Framework for Jailbreaking Large Language Models
Mar 18, 2024



Jailbreak attacks are crucial for identifying and mitigating the security vulnerabilities of Large Language Models (LLMs). They are designed to bypass safeguards and elicit prohibited outputs. However, due to significant differences among various jailbreak methods, there is no standard implementation framework available for the community, which limits comprehensive security evaluations. This paper introduces EasyJailbreak, a unified framework simplifying the construction and evaluation of jailbreak attacks against LLMs. It builds jailbreak attacks using four components: Selector, Mutator, Constraint, and Evaluator. This modular framework enables researchers to easily construct attacks from combinations of novel and existing components. So far, EasyJailbreak supports 11 distinct jailbreak methods and facilitates the security validation of a broad spectrum of LLMs. Our validation across 10 distinct LLMs reveals a significant vulnerability, with an average breach probability of 60% under various jailbreaking attacks. Notably, even advanced models like GPT-3.5-Turbo and GPT-4 exhibit average Attack Success Rates (ASR) of 57% and 33%, respectively. We have released a wealth of resources for researchers, including a web platform, PyPI published package, screencast video, and experimental outputs.
RoCoIns: Enhancing Robustness of Large Language Models through Code-Style Instructions
Feb 26, 2024Large Language Models (LLMs) have showcased remarkable capabilities in following human instructions. However, recent studies have raised concerns about the robustness of LLMs when prompted with instructions combining textual adversarial samples. In this paper, drawing inspiration from recent works that LLMs are sensitive to the design of the instructions, we utilize instructions in code style, which are more structural and less ambiguous, to replace typically natural language instructions. Through this conversion, we provide LLMs with more precise instructions and strengthen the robustness of LLMs. Moreover, under few-shot scenarios, we propose a novel method to compose in-context demonstrations using both clean and adversarial samples (\textit{adversarial context method}) to further boost the robustness of the LLMs. Experiments on eight robustness datasets show that our method consistently outperforms prompting LLMs with natural language instructions. For example, with gpt-3.5-turbo, our method achieves an improvement of 5.68\% in test set accuracy and a reduction of 5.66 points in Attack Success Rate (ASR).
Orthogonal Subspace Learning for Language Model Continual Learning
Oct 22, 2023Benefiting from massive corpora and advanced hardware, large language models (LLMs) exhibit remarkable capabilities in language understanding and generation. However, their performance degrades in scenarios where multiple tasks are encountered sequentially, also known as catastrophic forgetting. In this paper, we propose orthogonal low-rank adaptation (O-LoRA), a simple and efficient approach for continual learning in language models, effectively mitigating catastrophic forgetting while learning new tasks. Specifically, O-LoRA learns tasks in different (low-rank) vector subspaces that are kept orthogonal to each other in order to minimize interference. Our method induces only marginal additional parameter costs and requires no user data storage for replay. Experimental results on continual learning benchmarks show that our method outperforms state-of-the-art methods. Furthermore, compared to previous approaches, our method excels in preserving the generalization ability of LLMs on unseen tasks.
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
Apr 17, 2023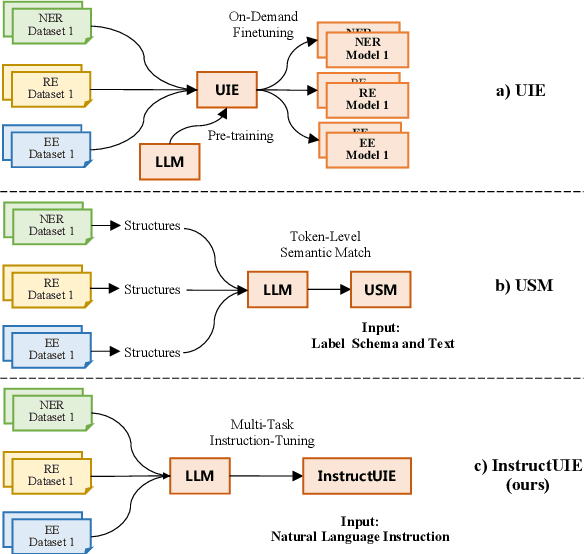
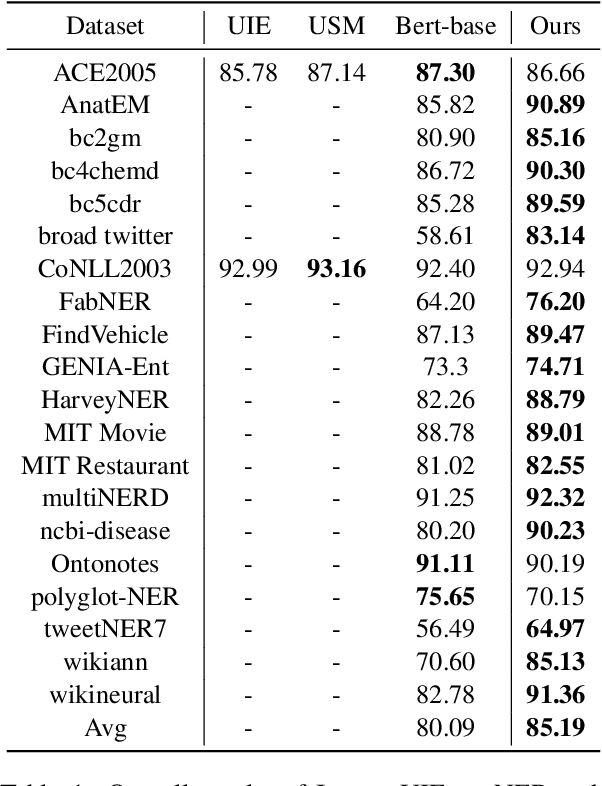
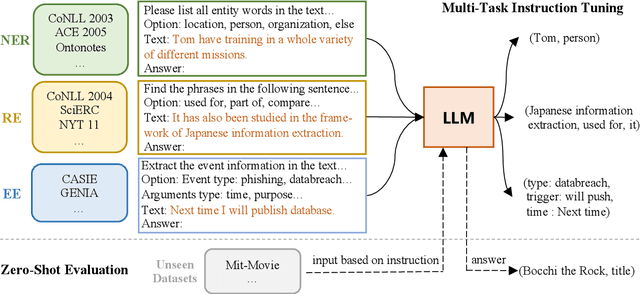
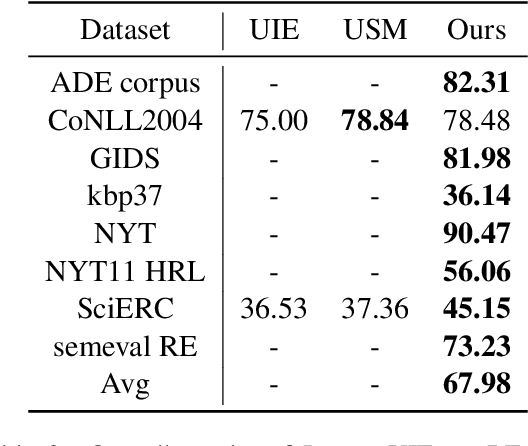
Large language models have unlocked strong multi-task capabilities from reading instructive prompts. However, recent studies have shown that existing large models still have difficulty with information extraction tasks. For example, gpt-3.5-turbo achieved an F1 score of 18.22 on the Ontonotes dataset, which is significantly lower than the state-of-the-art performance. In this paper, we propose InstructUIE, a unified information extraction framework based on instruction tuning, which can uniformly model various information extraction tasks and capture the inter-task dependency. To validate the proposed method, we introduce IE INSTRUCTIONS, a benchmark of 32 diverse information extraction datasets in a unified text-to-text format with expert-written instructions. Experimental results demonstrate that our method achieves comparable performance to Bert in supervised settings and significantly outperforms the state-of-the-art and gpt3.5 in zero-shot settings.