 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix Probing: Lightweight Harmful Content Detection for Large Language Models
Dec 18, 2025Large language models often face a three-way trade-off among detection accuracy, inference latency, and deployment cost when used in real-world safety-sensitive applications. This paper introduces Prefix Probing, a black-box harmful content detection method that compares the conditional log-probabilities of "agreement/execution" versus "refusal/safety" opening prefixes and leverages prefix caching to reduce detection overhead to near first-token latency. During inference, the method requires only a single log-probability computation over the probe prefixes to produce a harmfulness score and apply a threshold, without invoking any additional models or multi-stage inference. To further enhance the discriminative power of the prefixes, we design an efficient prefix construction algorithm that automatically discovers highly informative prefixes, substantially improving detection performance. Extensive experiments demonstrate that Prefix Probing achieves detection effectiveness comparable to mainstream external safety models while incurring only minimal computational cost and requiring no extra model deployment, highlighting its strong practicality and efficiency.
PRIV-QA: Privacy-Preserving Question Answering for Cloud Large Language Models
Feb 19, 2025The rapid development of large language models (LLMs) is redefining the landscape of human-computer interaction, and their integration into various user-service applications is becoming increasingly prevalent. However, transmitting user data to cloud-based LLMs presents significant risks of data breaches and unauthorized access to personal identification information. In this paper, we propose a privacy preservation pipeline for protecting privacy and sensitive information during interactions between users and LLMs in practical LLM usage scenarios. We construct SensitiveQA, the first privacy open-ended question-answering dataset. It comprises 57k interactions in Chinese and English, encompassing a diverse range of user-sensitive information within the conversations. Our proposed solution employs a multi-stage strategy aimed at preemptively securing user information while simultaneously preserving the response quality of cloud-based LLMs. Experimental validation underscores our method's efficacy in balancing privacy protection with maintaining robust interaction quality. The code and dataset are available at https://github.com/ligw1998/PRIV-QA.
CodeChameleon: Personalized Encryption Framework for Jailbreaking Large Language Models
Feb 26, 2024



Adversarial misuse, particularly through `jailbreaking' that circumvents a model's safety and ethical protocols, poses a significant challenge for Large Language Models (LLMs). This paper delves into the mechanisms behind such successful attacks, introducing a hypothesis for the safety mechanism of aligned LLMs: intent security recognition followed by response generation. Grounded in this hypothesis, we propose CodeChameleon, a novel jailbreak framework based on personalized encryption tactics. To elude the intent security recognition phase, we reformulate tasks into a code completion format, enabling users to encrypt queries using personalized encryption functions. To guarantee response generation functionality, we embed a decryption function within the instructions, which allows the LLM to decrypt and execute the encrypted queries successfully. We conduct extensive experiments on 7 LLMs, achieving state-of-the-art average Attack Success Rate (ASR). Remarkably, our method achieves an 86.6\% ASR on GPT-4-1106.
RoCoIns: Enhancing Robustness of Large Language Models through Code-Style Instructions
Feb 26, 2024Large Language Models (LLMs) have showcased remarkable capabilities in following human instructions. However, recent studies have raised concerns about the robustness of LLMs when prompted with instructions combining textual adversarial samples. In this paper, drawing inspiration from recent works that LLMs are sensitive to the design of the instructions, we utilize instructions in code style, which are more structural and less ambiguous, to replace typically natural language instructions. Through this conversion, we provide LLMs with more precise instructions and strengthen the robustness of LLMs. Moreover, under few-shot scenarios, we propose a novel method to compose in-context demonstrations using both clean and adversarial samples (\textit{adversarial context method}) to further boost the robustness of the LLMs. Experiments on eight robustness datasets show that our method consistently outperforms prompting LLMs with natural language instructions. For example, with gpt-3.5-turbo, our method achieves an improvement of 5.68\% in test set accuracy and a reduction of 5.66 points in Attack Success Rate (ASR).
GumbelSoft: Diversified Language Model Watermarking via the GumbelMax-trick
Feb 25, 2024Large language models (LLMs) excellently generate human-like text, but also raise concerns about misuse in fake news and academic dishonesty. Decoding-based watermark, particularly the GumbelMax-trick-based watermark(GM watermark), is a standout solution for safeguarding machine-generated texts due to its notable detectability. However, GM watermark encounters a major challenge with generation diversity, always yielding identical outputs for the same prompt, negatively impacting generation diversity and user experience. To overcome this limitation, we propose a new type of GM watermark, the Logits-Addition watermark, and its three variants, specifically designed to enhance diversity. Among these, the GumbelSoft watermark (a softmax variant of the Logits-Addition watermark) demonstrates superior performance in high diversity settings, with its AUROC score outperforming those of the two alternative variants by 0.1 to 0.3 and surpassing other decoding-based watermarking methods by a minimum of 0.1.
TRACE: A Comprehensive Benchmark for Continual Learning in Large Language Models
Oct 10, 2023Aligned large language models (LLMs) demonstrate exceptional capabilities in task-solving, following instructions, and ensuring safety. However, the continual learning aspect of these aligned LLMs has been largely overlooked. Existing continual learning benchmarks lack sufficient challenge for leading aligned LLMs, owing to both their simplicity and the models' potential exposure during instruction tuning. In this paper, we introduce TRACE, a novel benchmark designed to evaluate continual learning in LLMs. TRACE consists of 8 distinct datasets spanning challenging tasks including domain-specific tasks, multilingual capabilities, code generation, and mathematical reasoning. All datasets are standardized into a unified format, allowing for effortless automatic evaluation of LLMs. Our experiments show that after training on TRACE, aligned LLMs exhibit significant declines in both general ability and instruction-following capabilities. For example, the accuracy of llama2-chat 13B on gsm8k dataset declined precipitously from 28.8\% to 2\% after training on our datasets. This highlights the challenge of finding a suitable tradeoff between achieving performance on specific tasks while preserving the original prowess of LLMs. Empirical findings suggest that tasks inherently equipped with reasoning paths contribute significantly to preserving certain capabilities of LLMs against potential declines. Motivated by this, we introduce the Reasoning-augmented Continual Learning (RCL) approach. RCL integrates task-specific cues with meta-rationales, effectively reducing catastrophic forgetting in LLMs while expediting convergence on novel tasks.
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction
Apr 17, 2023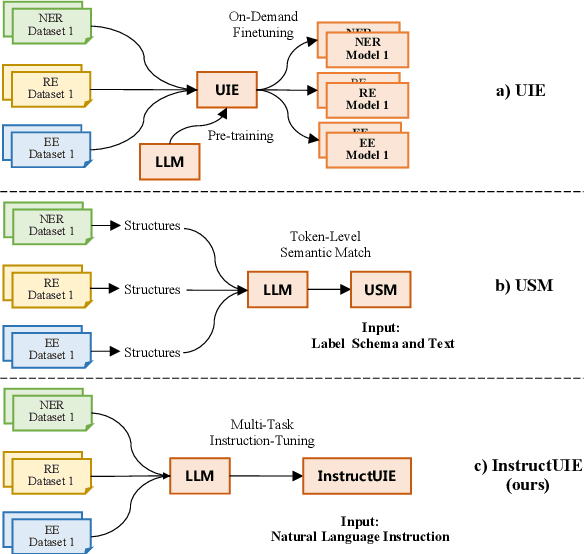
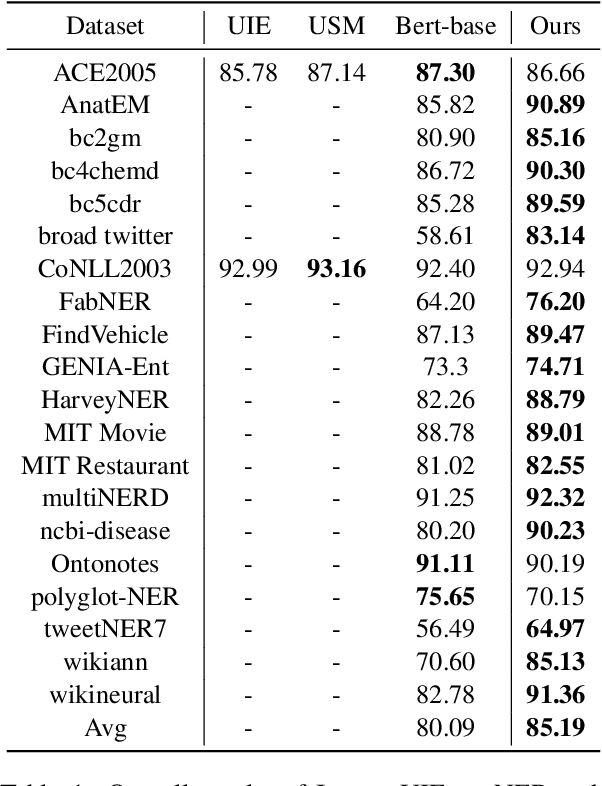
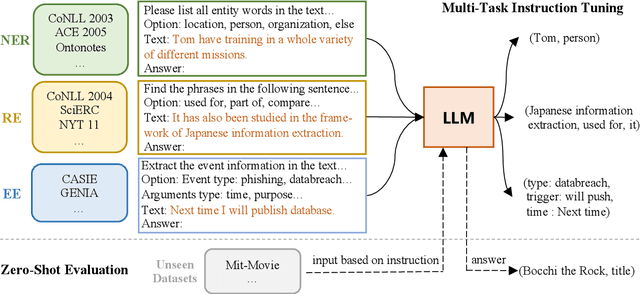
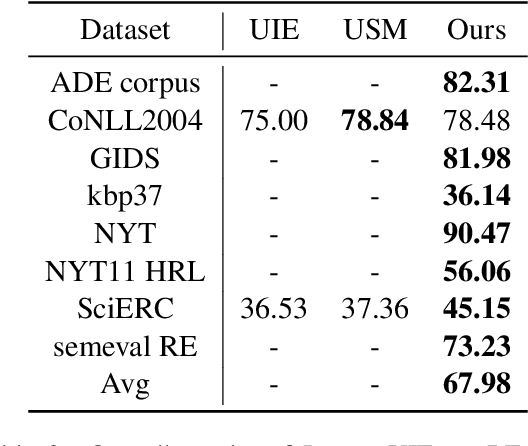
Large language models have unlocked strong multi-task capabilities from reading instructive prompts. However, recent studies have shown that existing large models still have difficulty with information extraction tasks. For example, gpt-3.5-turbo achieved an F1 score of 18.22 on the Ontonotes dataset, which is significantly lower than the state-of-the-art performance. In this paper, we propose InstructUIE, a unified information extraction framework based on instruction tuning, which can uniformly model various information extraction tasks and capture the inter-task dependency. To validate the proposed method, we introduce IE INSTRUCTIONS, a benchmark of 32 diverse information extraction datasets in a unified text-to-text format with expert-written instructions. Experimental results demonstrate that our method achieves comparable performance to Bert in supervised settings and significantly outperforms the state-of-the-art and gpt3.5 in zero-shot settings.