 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIV-QA: Privacy-Preserving Question Answering for Cloud Large Language Models
Feb 19, 2025The rapid development of large language models (LLMs) is redefining the landscape of human-computer interaction, and their integration into various user-service applications is becoming increasingly prevalent. However, transmitting user data to cloud-based LLMs presents significant risks of data breaches and unauthorized access to personal identification information. In this paper, we propose a privacy preservation pipeline for protecting privacy and sensitive information during interactions between users and LLMs in practical LLM usage scenarios. We construct SensitiveQA, the first privacy open-ended question-answering dataset. It comprises 57k interactions in Chinese and English, encompassing a diverse range of user-sensitive information within the conversations. Our proposed solution employs a multi-stage strategy aimed at preemptively securing user information while simultaneously preserving the response quality of cloud-based LLMs. Experimental validation underscores our method's efficacy in balancing privacy protection with maintaining robust interaction quality. The code and dataset are available at https://github.com/ligw1998/PRIV-QA.
Learning Efficient Convolutional Networks through Network Slimming
Aug 22, 2017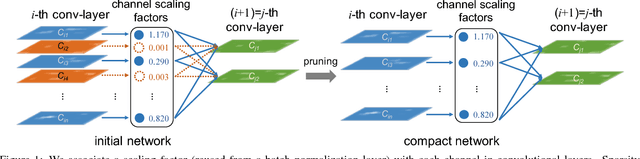
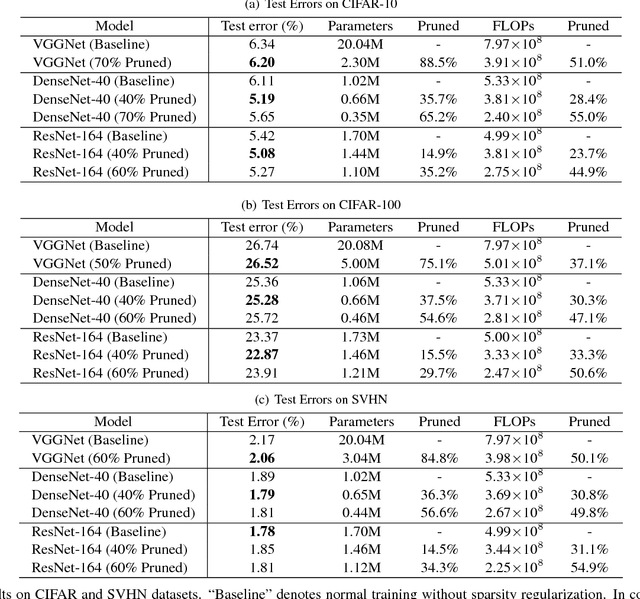

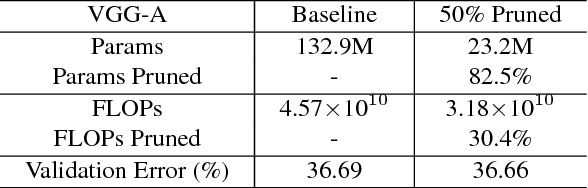
The deployment of deep convolutional neural networks (CNNs) in many real world applications is largely hindered by their high computational cost. In this paper, we propose a novel learning scheme for CNNs to simultaneously 1) reduce the model size; 2) decrease the run-time memory footprint; and 3) lower the number of computing operations, without compromising accuracy. This is achieved by enforcing channel-level sparsity in the network in a simple but effective way. Different from many existing approaches, the proposed method directly applies to modern CNN architectures, introduces minimum overhead to the training process, and requires no special software/hardware accelerators for the resulting models. We call our approach network slimming, which takes wide and large networks as input models, but during training insignificant channels are automatically identified and pruned afterwards, yielding thin and compact models with comparable accuracy. We empirically demonstrate the effectiveness of our approach with several state-of-the-art CNN models, including VGGNet, ResNet and DenseNet, on various image classification datasets. For VGGNet, a multi-pass version of network slimming gives a 20x reduction in model size and a 5x reduction in computing operations.