 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-AutoDP: Automatic Data Processing via LLM Agents for Model Fine-tuning
Jan 28, 2026Large Language Models (LLMs) can be fine-tuned on domain-specific data to enhance their performance in specialized fields. However, such data often contains numerous low-quality samples, necessitating effective data processing (DP). In practice, DP strategies are typically developed through iterative manual analysis and trial-and-error adjustment. These processes inevitably incur high labor costs and may lead to privacy issues in high-privacy domains like healthcare due to direct human access to sensitive data. Thus, achieving automated data processing without exposing the raw data has become a critical challenge. To address this challenge, we propose LLM-AutoDP, a novel framework that leverages LLMs as agents to automatically generate and optimize data processing strategies. Our method generates multiple candidate strategies and iteratively refines them using feedback signals and comparative evaluations. This iterative in-context learning mechanism enables the agent to converge toward high-quality processing pipelines without requiring direct human intervention or access to the underlying data. To further accelerate strategy search, we introduce three key techniques: Distribution Preserving Sampling, which reduces data volume while maintaining distributional integrity; Processing Target Selection, which uses a binary classifier to identify low-quality samples for focused processing; Cache-and-Reuse Mechanism}, which minimizes redundant computations by reusing prior processing results. Results show that models trained on data processed by our framework achieve over 80% win rates against models trained on unprocessed data. Compared to AutoML baselines based on LLM agents, LLM-AutoDP achieves approximately a 65% win rate. Moreover, our acceleration techniques reduce the total searching time by up to 10 times, demonstrating both effectiveness and efficiency.
GradPruner: Gradient-Guided Layer Pruning Enabling Efficient Fine-Tuning and Inference for LLMs
Jan 27, 2026Fine-tuning Large Language Models (LLMs) with downstream data is often considered time-consuming and expensive. Structured pruning methods are primarily employed to improve the inference efficiency of pre-trained models. Meanwhile, they often require additional time and memory for training, knowledge distillation, structure search, and other strategies, making efficient model fine-tuning challenging to achieve. To simultaneously enhance the training and inference efficiency of downstream task fine-tuning, we introduce GradPruner, which can prune layers of LLMs guided by gradients in the early stages of fine-tuning. GradPruner uses the cumulative gradients of each parameter during the initial phase of fine-tuning to compute the Initial Gradient Information Accumulation Matrix (IGIA-Matrix) to assess the importance of layers and perform pruning. We sparsify the pruned layers based on the IGIA-Matrix and merge them with the remaining layers. Only elements with the same sign are merged to reduce interference from sign variations. We conducted extensive experiments on two LLMs across eight downstream datasets. Including medical, financial, and general benchmark tasks. The results demonstrate that GradPruner has achieved a parameter reduction of 40% with only a 0.99% decrease in accuracy. Our code is publicly available.
Prefix Probing: Lightweight Harmful Content Detection for Large Language Models
Dec 18, 2025Large language models often face a three-way trade-off among detection accuracy, inference latency, and deployment cost when used in real-world safety-sensitive applications. This paper introduces Prefix Probing, a black-box harmful content detection method that compares the conditional log-probabilities of "agreement/execution" versus "refusal/safety" opening prefixes and leverages prefix caching to reduce detection overhead to near first-token latency. During inference, the method requires only a single log-probability computation over the probe prefixes to produce a harmfulness score and apply a threshold, without invoking any additional models or multi-stage inference. To further enhance the discriminative power of the prefixes, we design an efficient prefix construction algorithm that automatically discovers highly informative prefixes, substantially improving detection performance. Extensive experiments demonstrate that Prefix Probing achieves detection effectiveness comparable to mainstream external safety models while incurring only minimal computational cost and requiring no extra model deployment, highlighting its strong practicality and efficiency.
AnchorSync: Global Consistency Optimization for Long Video Editing
Aug 20, 2025Editing long videos remains a challenging task due to the need for maintaining both global consistency and temporal coherence across thousands of frames. Existing methods often suffer from structural drift or temporal artifacts, particularly in minute-long sequences. We introduce AnchorSync, a novel diffusion-based framework that enables high-quality, long-term video editing by decoupling the task into sparse anchor frame editing and smooth intermediate frame interpolation. Our approach enforces structural consistency through a progressive denoising process and preserves temporal dynamics via multimodal guidance. Extensive experiments show that AnchorSync produces coherent, high-fidelity edits, surpassing prior methods in visual quality and temporal stability.
VeFIA: An Efficient Inference Auditing Framework for Vertical Federated Collaborative Software
Jul 03, 2025



Vertical Federated Learning (VFL) is a distributed AI software deployment mechanism for cross-silo collaboration without accessing participants' data. However, existing VFL work lacks a mechanism to audit the execution correctness of the inference software of the data party. To address this problem, we design a Vertical Federated Inference Auditing (VeFIA) framework. VeFIA helps the task party to audit whether the data party's inference software is executed as expected during large-scale inference without leaking the data privacy of the data party or introducing additional latency to the inference system. The core of VeFIA is that the task party can use the inference results from a framework with Trusted Execution Environments (TEE) and the coordinator to validate the correctness of the data party's computation results. VeFIA guarantees that, as long as the abnormal inference exceeds 5.4%, the task party can detect execution anomalies in the inference software with a probability of 99.99%, without incurring any additional online inference latency. VeFIA's random sampling validation achieves 100% positive predictive value, negative predictive value, and true positive rate in detecting abnormal inference. To the best of our knowledge, this is the first paper to discuss the correctness of inference software execution in VFL.
Losing is for Cherishing: Data Valuation Based on Machine Unlearning and Shapley Value
May 22, 2025The proliferation of large models has intensified the need for efficient data valuation methods to quantify the contribution of individual data providers. Traditional approaches, such as game-theory-based Shapley value and influence-function-based techniques, face prohibitive computational costs or require access to full data and model training details, making them hardly achieve partial data valuation. To address this, we propose Unlearning Shapley, a novel framework that leverages machine unlearning to estimate data values efficiently. By unlearning target data from a pretrained model and measuring performance shifts on a reachable test set, our method computes Shapley values via Monte Carlo sampling, avoiding retraining and eliminating dependence on full data. Crucially, Unlearning Shapley supports both full and partial data valuation, making it scalable for large models (e.g., LLMs) and practical for data markets. Experiments on benchmark datasets and large-scale text corpora demonstrate that our approach matches the accuracy of state-of-the-art methods while reducing computational overhead by orders of magnitude. Further analysis confirms a strong correlation between estimated values and the true impact of data subsets, validating its reliability in real-world scenarios. This work bridges the gap between data valuation theory and practical deployment, offering a scalable, privacy-compliant solution for modern AI ecosystems.
PRIV-QA: Privacy-Preserving Question Answering for Cloud Large Language Models
Feb 19, 2025The rapid development of large language models (LLMs) is redefining the landscape of human-computer interaction, and their integration into various user-service applications is becoming increasingly prevalent. However, transmitting user data to cloud-based LLMs presents significant risks of data breaches and unauthorized access to personal identification information. In this paper, we propose a privacy preservation pipeline for protecting privacy and sensitive information during interactions between users and LLMs in practical LLM usage scenarios. We construct SensitiveQA, the first privacy open-ended question-answering dataset. It comprises 57k interactions in Chinese and English, encompassing a diverse range of user-sensitive information within the conversations. Our proposed solution employs a multi-stage strategy aimed at preemptively securing user information while simultaneously preserving the response quality of cloud-based LLMs. Experimental validation underscores our method's efficacy in balancing privacy protection with maintaining robust interaction quality. The code and dataset are available at https://github.com/ligw1998/PRIV-QA.
Privacy Evaluation Benchmarks for NLP Models
Sep 25, 2024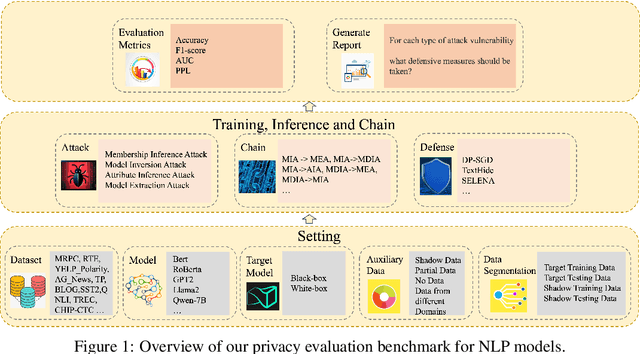
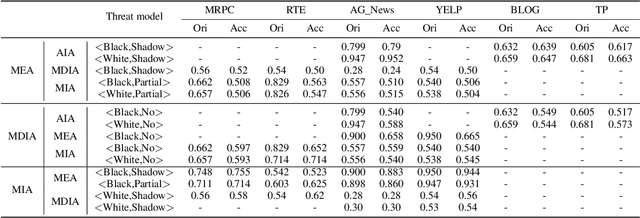
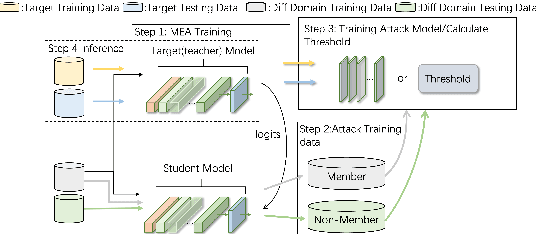
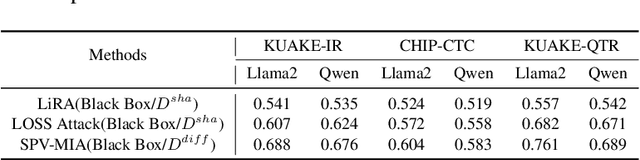
By inducing privacy attacks on NLP models, attackers can obtain sensitive information such as training data and model parameters, etc. Although researchers have studied, in-depth, several kinds of attacks in NLP models, they are non-systematic analyses. It lacks a comprehensive understanding of the impact caused by the attacks. For example, we must consider which scenarios can apply to which attacks, what the common factors are that affect the performance of different attacks, the nature of the relationships between different attacks, and the influence of various datasets and models on the effectiveness of the attacks, etc. Therefore, we need a benchmark to holistically assess the privacy risks faced by NLP models. In this paper, we present a privacy attack and defense evaluation benchmark in the field of NLP, which includes the conventional/small models and large language models (LLMs). This benchmark supports a variety of models, datasets, and protocols, along with standardized modules for comprehensive evaluation of attacks and defense strategies. Based on the above framework, we present a study on the association between auxiliary data from different domains and the strength of privacy attacks. And we provide an improved attack method in this scenario with the help of Knowledge Distillation (KD). Furthermore, we propose a chained framework for privacy attacks. Allowing a practitioner to chain multiple attacks to achieve a higher-level attack objective. Based on this, we provide some defense and enhanced attack strategies. The code for reproducing the results can be found at https://github.com/user2311717757/nlp_doctor.
Information Leakage from Embedding in Large Language Models
May 22, 2024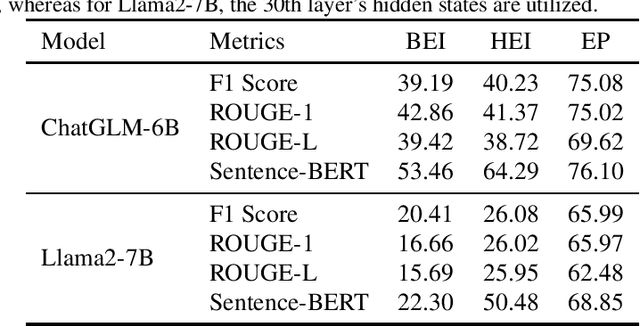
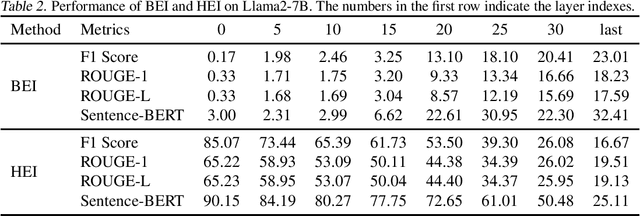
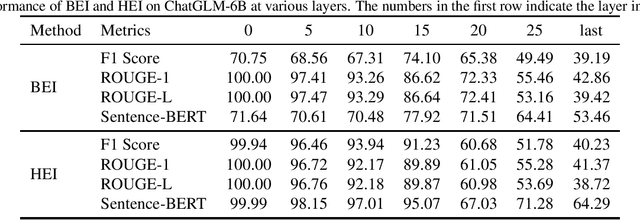
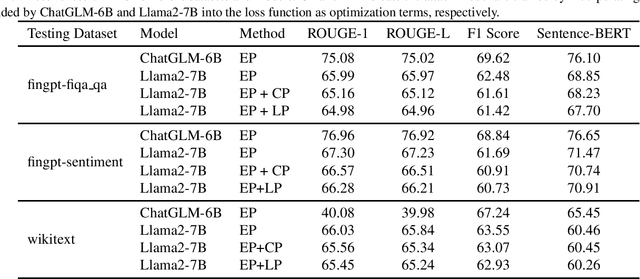
The widespread adoption of large language models (LLMs) has raised concerns regarding data privacy. This study aims to investigate the potential for privacy invasion through input reconstruction attacks, in which a malicious model provider could potentially recover user inputs from embeddings. We first propose two base methods to reconstruct original texts from a model's hidden states. We find that these two methods are effective in attacking the embeddings from shallow layers, but their effectiveness decreases when attacking embeddings from deeper layers. To address this issue, we then present Embed Parrot, a Transformer-based method, to reconstruct input from embeddings in deep layers. Our analysis reveals that Embed Parrot effectively reconstructs original inputs from the hidden states of ChatGLM-6B and Llama2-7B, showcasing stable performance across various token lengths and data distributions. To mitigate the risk of privacy breaches, we introduce a defense mechanism to deter exploitation of the embedding reconstruction process. Our findings emphasize the importance of safeguarding user privacy in distributed learning systems and contribute valuable insights to enhance the security protocols within such environments.
Ditto: Quantization-aware Secure Inference of Transformers upon MPC
May 09, 2024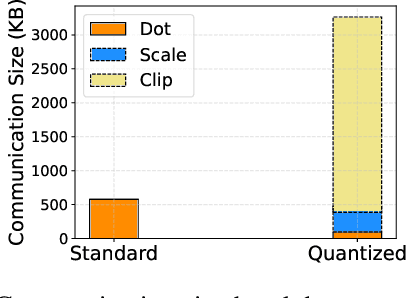
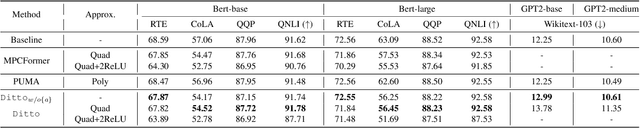
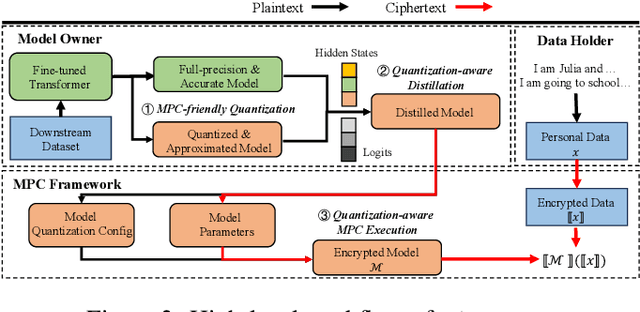
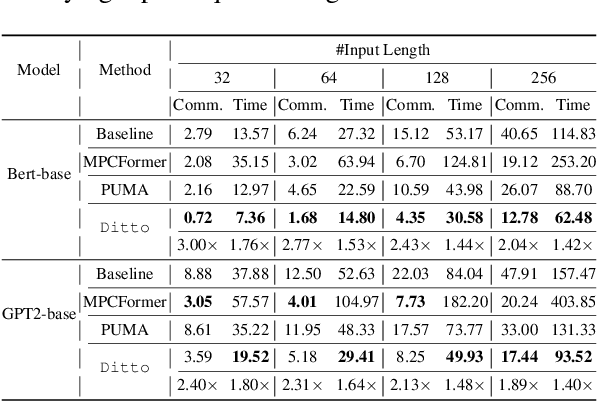
Due to the rising privacy concerns on sensitive client data and trained models like Transformers, secure multi-party computation (MPC) techniques are employed to enable secure inference despite attendant overhead. Existing works attempt to reduce the overhead using more MPC-friendly non-linear function approximations. However, the integration of quantization widely used in plaintext inference into the MPC domain remains unclear. To bridge this gap, we propose the framework named Ditto to enable more efficient quantization-aware secure Transformer inference. Concretely, we first incorporate an MPC-friendly quantization into Transformer inference and employ a quantization-aware distillation procedure to maintain the model utility. Then, we propose novel MPC primitives to support the type conversions that are essential in quantization and implement the quantization-aware MPC execution of secure quantized inference. This approach significantly decreases both computation and communication overhead, leading to improvements in overall efficiency. We conduct extensive experiments on Bert and GPT2 models to evaluate the performance of Ditto. The results demonstrate that Ditto is about $3.14\sim 4.40\times$ faster than MPCFormer (ICLR 2023) and $1.44\sim 2.35\times$ faster than the state-of-the-art work PUMA with negligible utility degradation.