 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Shrinkage Bias in LLM FP4 Pretraining: Geometric Origin, Systemic Impact, and UFP4 Recipe
Jun 18, 2026FP4 training promises substantial reductions in memory and computation cost for LLM pretraining, yet current FP4 hardware paths and recipes, including NVIDIA Blackwell/Rubin-class systems and AMD MI350-series GPUs, remain centered on E2M1 data elements. In this study, we identify a fundamental limitation of that choice: non-uniform formats such as E2M1 inherently suffer from Shrinkage Bias, a systematic negative rounding error caused by the geometric asymmetry of their representable bins. We show that this bias accumulates multiplicatively across layers and is amplified by the Random Hadamard Transform (RHT), providing a unified explanation for the training instability observed in existing E2M1-based FP4 recipes. In contrast, uniform grids (E1M2/INT4) bypass this grid-geometry error and better convert the improved bucket utilization from RHT into higher quantization quality. Based on this finding, we propose UFP4, a uniform 4-bit training recipe that applies RHT to all three training GEMMs while restricting stochastic rounding to dY alone. On Dense 1.5B, MoE 7.9B, and MoE 124B long-run pretraining, UFP4 consistently achieves lower BF16-relative loss degradation than strong E2M1-based baselines, supported by scaling-law analysis and ablation studies. Our results suggest that future accelerators should support E1M2/INT4-style uniform 4-bit grids as first-class training primitives alongside E2M1.
A Fast, Performant, Secure Distributed Training Framework For Large Language Model
Jan 19, 2024



The distributed (federated) LLM is an important method for co-training the domain-specific LLM using siloed data. However, maliciously stealing model parameters and data from the server or client side has become an urgent problem to be solved. In this paper, we propose a secure distributed LLM based on model slicing. In this case, we deploy the Trusted Execution Environment (TEE) on both the client and server side, and put the fine-tuned structure (LoRA or embedding of P-tuning v2) into the TEE. Then, secure communication is executed in the TEE and general environments through lightweight encryption. In order to further reduce the equipment cost as well as increase the model performance and accuracy, we propose a split fine-tuning scheme. In particular, we split the LLM by layers and place the latter layers in a server-side TEE (the client does not need a TEE). We then combine the proposed Sparsification Parameter Fine-tuning (SPF) with the LoRA part to improve the accuracy of the downstream task. Numerous experiments have shown that our method guarantees accuracy while maintaining security.
S3ML: A Secure Serving System for Machine Learning Inference
Oct 13, 2020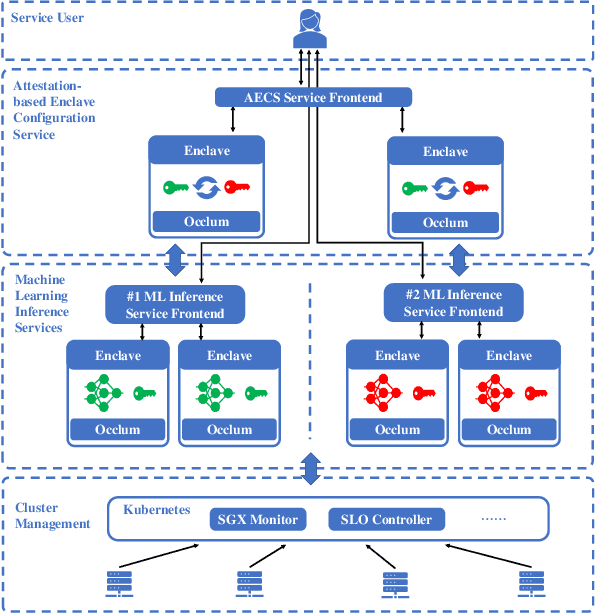
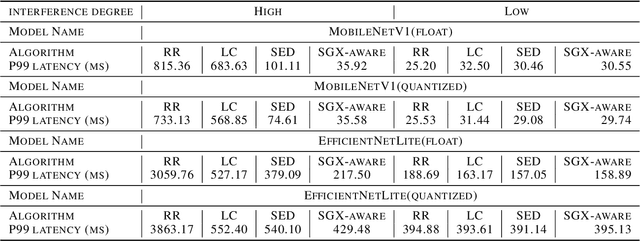
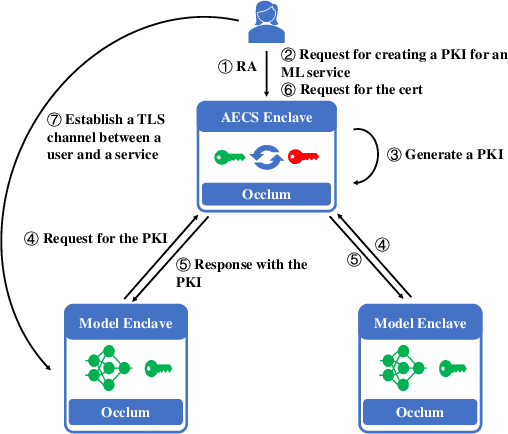
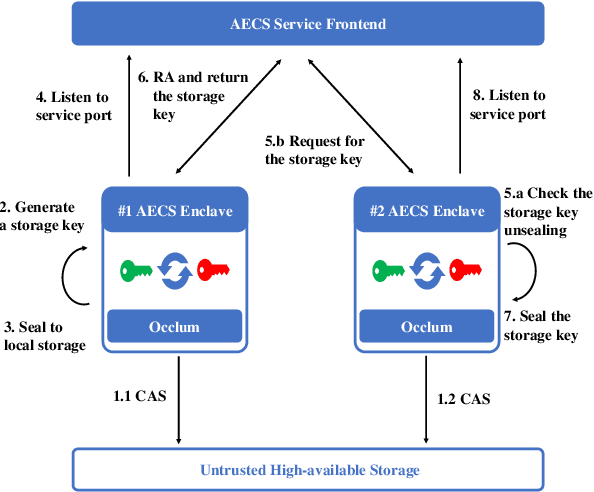
We present S3ML, a secure serving system for machine learning inference in this paper. S3ML runs machine learning models in Intel SGX enclaves to protect users' privacy. S3ML designs a secure key management service to construct flexible privacy-preserving server clusters and proposes novel SGX-aware load balancing and scaling methods to satisfy users' Service-Level Objectives. We have implemented S3ML based on Kubernetes as a low-overhead, high-available, and scalable system. We demonstrate the system performance and effectiveness of S3ML through extensive experiments on a series of widely-used models.
A Hybrid-Domain Framework for Secure Gradient Tree Boosting
May 18, 2020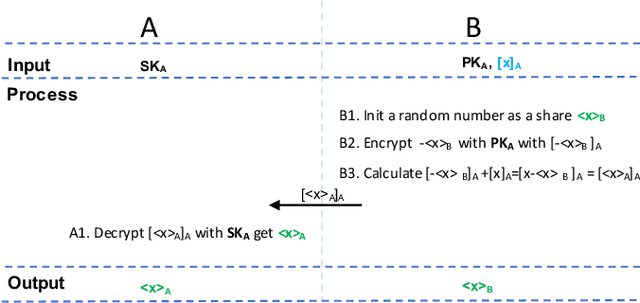
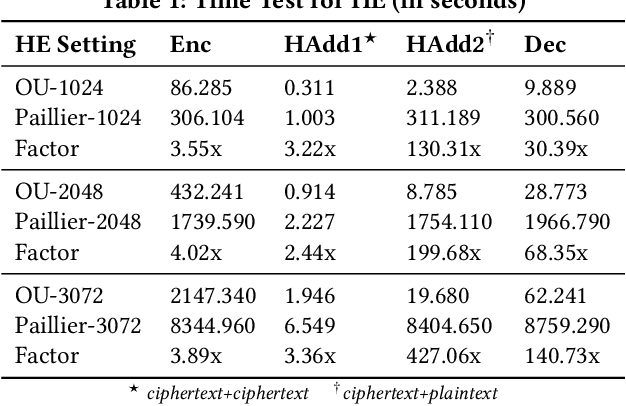
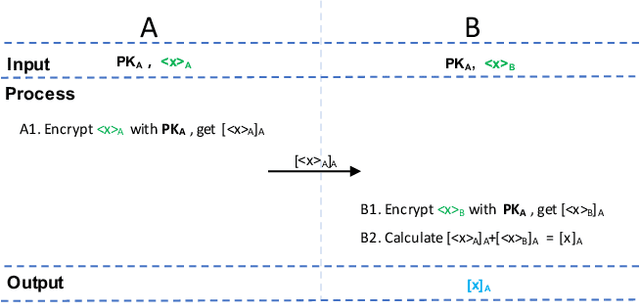
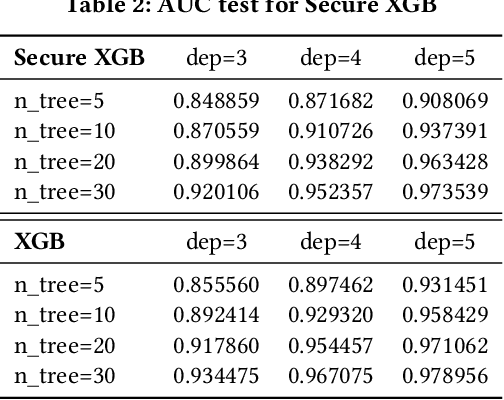
Gradient tree boosting (e.g. XGB) is one of the most widely usedmachine learning models in practice. How to build a secure XGB inface of data isolation problem becomes a hot research topic. However, existing works tend to leak intermediate information and thusraise potential privacy risk. In this paper, we propose a novel framework for two parties to build secure XGB with vertically partitioneddata. Specifically, we associate Homomorphic Encryption (HE) domain with Secret Sharing (SS) domain by providing the two-waytransformation primitives. The framework generally promotes theefficiency for privacy preserving machine learning and offers theflexibility to implement other machine learning models. Then weelaborate two secure XGB training algorithms as well as a corresponding prediction algorithm under the hybrid security domains.Next, we compare our proposed two training algorithms throughboth complexity analysis and experiments. Finally, we verify themodel performance on benchmark dataset and further apply ourwork to a real-world scenario.