 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-AutoDP: Automatic Data Processing via LLM Agents for Model Fine-tuning
Jan 28, 2026Large Language Models (LLMs) can be fine-tuned on domain-specific data to enhance their performance in specialized fields. However, such data often contains numerous low-quality samples, necessitating effective data processing (DP). In practice, DP strategies are typically developed through iterative manual analysis and trial-and-error adjustment. These processes inevitably incur high labor costs and may lead to privacy issues in high-privacy domains like healthcare due to direct human access to sensitive data. Thus, achieving automated data processing without exposing the raw data has become a critical challenge. To address this challenge, we propose LLM-AutoDP, a novel framework that leverages LLMs as agents to automatically generate and optimize data processing strategies. Our method generates multiple candidate strategies and iteratively refines them using feedback signals and comparative evaluations. This iterative in-context learning mechanism enables the agent to converge toward high-quality processing pipelines without requiring direct human intervention or access to the underlying data. To further accelerate strategy search, we introduce three key techniques: Distribution Preserving Sampling, which reduces data volume while maintaining distributional integrity; Processing Target Selection, which uses a binary classifier to identify low-quality samples for focused processing; Cache-and-Reuse Mechanism}, which minimizes redundant computations by reusing prior processing results. Results show that models trained on data processed by our framework achieve over 80% win rates against models trained on unprocessed data. Compared to AutoML baselines based on LLM agents, LLM-AutoDP achieves approximately a 65% win rate. Moreover, our acceleration techniques reduce the total searching time by up to 10 times, demonstrating both effectiveness and efficiency.
GradPruner: Gradient-Guided Layer Pruning Enabling Efficient Fine-Tuning and Inference for LLMs
Jan 27, 2026Fine-tuning Large Language Models (LLMs) with downstream data is often considered time-consuming and expensive. Structured pruning methods are primarily employed to improve the inference efficiency of pre-trained models. Meanwhile, they often require additional time and memory for training, knowledge distillation, structure search, and other strategies, making efficient model fine-tuning challenging to achieve. To simultaneously enhance the training and inference efficiency of downstream task fine-tuning, we introduce GradPruner, which can prune layers of LLMs guided by gradients in the early stages of fine-tuning. GradPruner uses the cumulative gradients of each parameter during the initial phase of fine-tuning to compute the Initial Gradient Information Accumulation Matrix (IGIA-Matrix) to assess the importance of layers and perform pruning. We sparsify the pruned layers based on the IGIA-Matrix and merge them with the remaining layers. Only elements with the same sign are merged to reduce interference from sign variations. We conducted extensive experiments on two LLMs across eight downstream datasets. Including medical, financial, and general benchmark tasks. The results demonstrate that GradPruner has achieved a parameter reduction of 40% with only a 0.99% decrease in accuracy. Our code is publicly available.
Information Leakage from Embedding in Large Language Models
May 22, 2024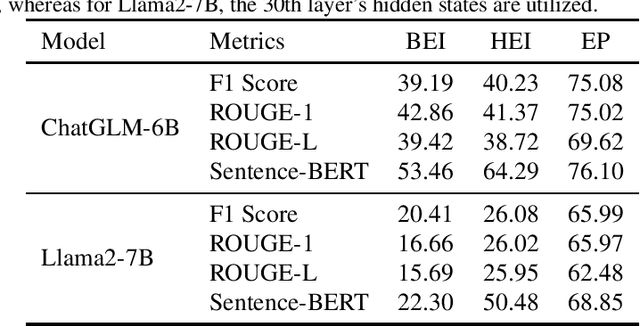
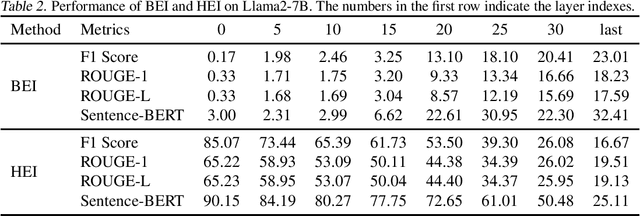
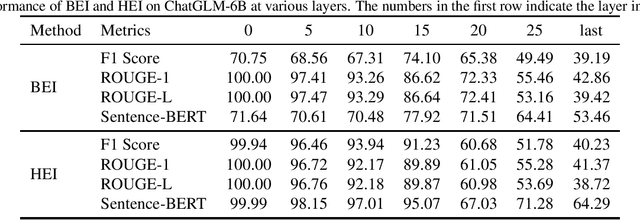
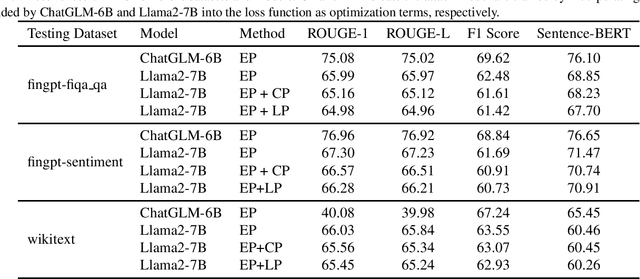
The widespread adoption of large language models (LLMs) has raised concerns regarding data privacy. This study aims to investigate the potential for privacy invasion through input reconstruction attacks, in which a malicious model provider could potentially recover user inputs from embeddings. We first propose two base methods to reconstruct original texts from a model's hidden states. We find that these two methods are effective in attacking the embeddings from shallow layers, but their effectiveness decreases when attacking embeddings from deeper layers. To address this issue, we then present Embed Parrot, a Transformer-based method, to reconstruct input from embeddings in deep layers. Our analysis reveals that Embed Parrot effectively reconstructs original inputs from the hidden states of ChatGLM-6B and Llama2-7B, showcasing stable performance across various token lengths and data distributions. To mitigate the risk of privacy breaches, we introduce a defense mechanism to deter exploitation of the embedding reconstruction process. Our findings emphasize the importance of safeguarding user privacy in distributed learning systems and contribute valuable insights to enhance the security protocols within such environments.
A Fast, Performant, Secure Distributed Training Framework For Large Language Model
Jan 19, 2024



The distributed (federated) LLM is an important method for co-training the domain-specific LLM using siloed data. However, maliciously stealing model parameters and data from the server or client side has become an urgent problem to be solved. In this paper, we propose a secure distributed LLM based on model slicing. In this case, we deploy the Trusted Execution Environment (TEE) on both the client and server side, and put the fine-tuned structure (LoRA or embedding of P-tuning v2) into the TEE. Then, secure communication is executed in the TEE and general environments through lightweight encryption. In order to further reduce the equipment cost as well as increase the model performance and accuracy, we propose a split fine-tuning scheme. In particular, we split the LLM by layers and place the latter layers in a server-side TEE (the client does not need a TEE). We then combine the proposed Sparsification Parameter Fine-tuning (SPF) with the LoRA part to improve the accuracy of the downstream task. Numerous experiments have shown that our method guarantees accuracy while maintaining security.
HPN: Personalized Federated Hyperparameter Optimization
Apr 11, 2023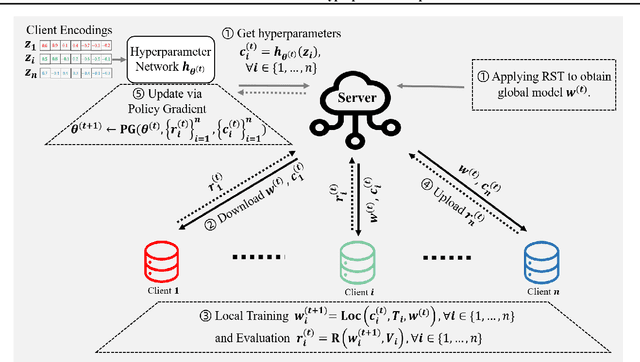
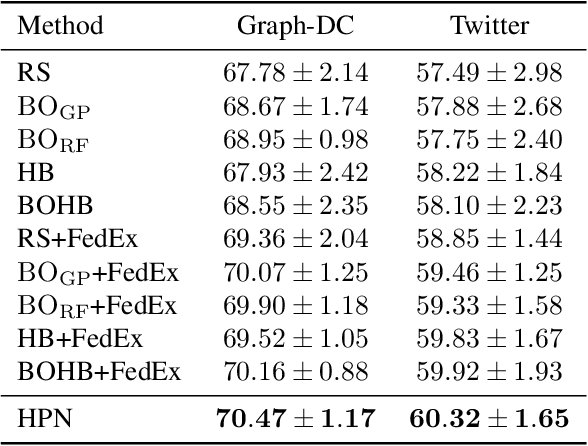
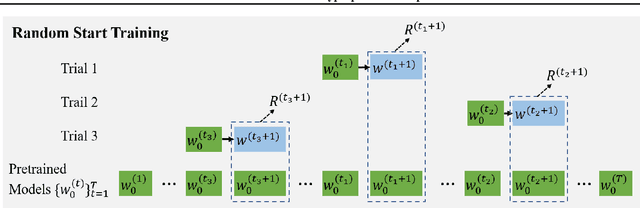
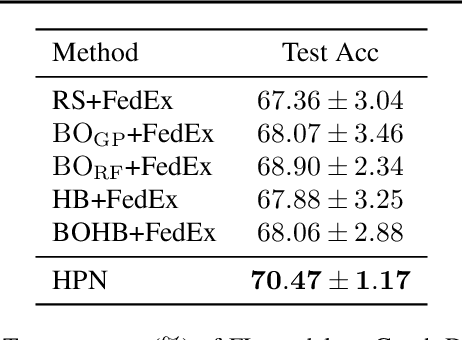
Numerous research studies in the field of federated learning (FL) have attempted to use personalization to address the heterogeneity among clients, one of FL's most crucial and challenging problems. However, existing works predominantly focus on tailoring models. Yet, due to the heterogeneity of clients, they may each require different choices of hyperparameters, which have not been studied so far. We pinpoint two challenges of personalized federated hyperparameter optimization (pFedHPO): handling the exponentially increased search space and characterizing each client without compromising its data privacy. To overcome them, we propose learning a \textsc{H}yper\textsc{P}arameter \textsc{N}etwork (HPN) fed with client encoding to decide personalized hyperparameters. The client encoding is calculated with a random projection-based procedure to protect each client's privacy. Besides, we design a novel mechanism to debias the low-fidelity function evaluation samples for learning HPN. We conduct extensive experiments on FL tasks from various domains, demonstrating the superiority of HPN.
PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient
Jul 05, 2022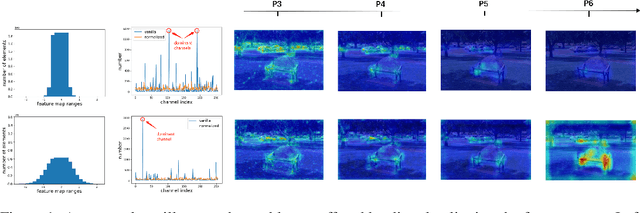
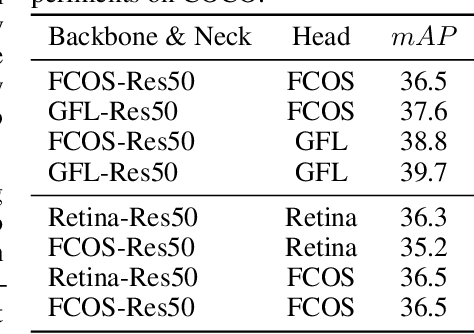
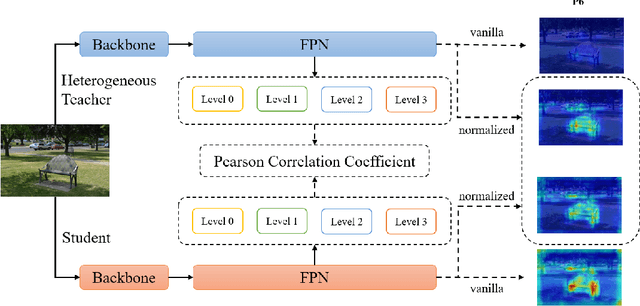
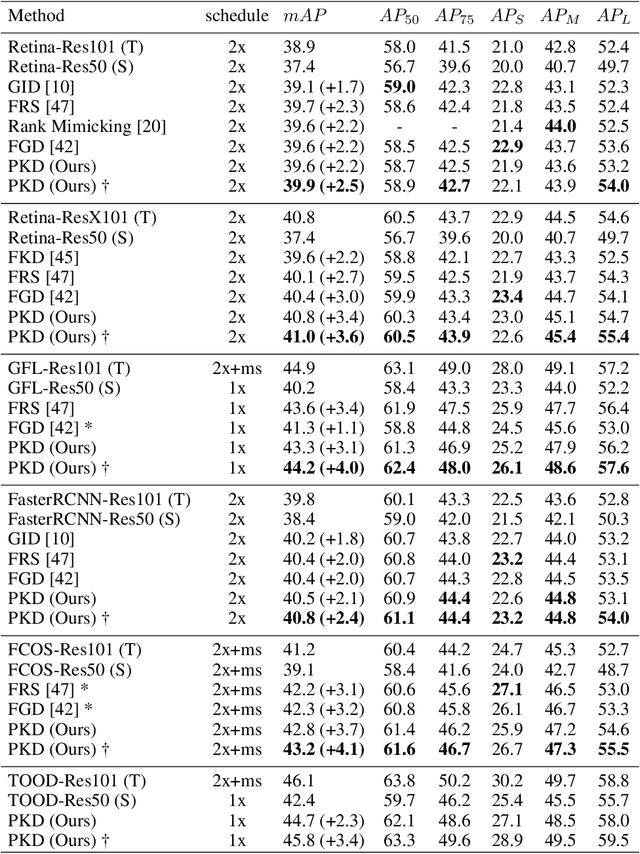
Knowledge distillation(KD) is a widely-used technique to train compact models in object detection. However, there is still a lack of study on how to distill between heterogeneous detectors. In this paper, we empirically find that better FPN features from a heterogeneous teacher detector can help the student although their detection heads and label assignments are different. However, directly aligning the feature maps to distill detectors suffers from two problems. First, the difference in feature magnitude between the teacher and the student could enforce overly strict constraints on the student. Second, the FPN stages and channels with large feature magnitude from the teacher model could dominate the gradient of distillation loss, which will overwhelm the effects of other features in KD and introduce much noise. To address the above issues, we propose to imitate features with Pearson Correlation Coefficient to focus on the relational information from the teacher and relax constraints on the magnitude of the features. Our method consistently outperforms the existing detection KD methods and works for both homogeneous and heterogeneous student-teacher pairs. Furthermore, it converges faster. With a powerful MaskRCNN-Swin detector as the teacher, ResNet-50 based RetinaNet and FCOS achieve 41.5% and 43.9% mAP on COCO2017, which are 4.1\% and 4.8\% higher than the baseline, respectively.
Differentially Private Federated Learning with Local Regularization and Sparsification
Mar 21, 2022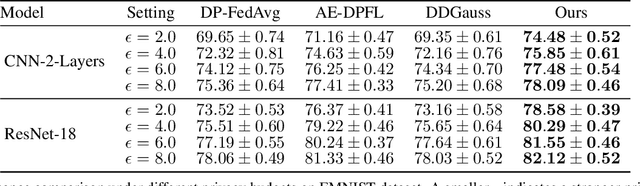
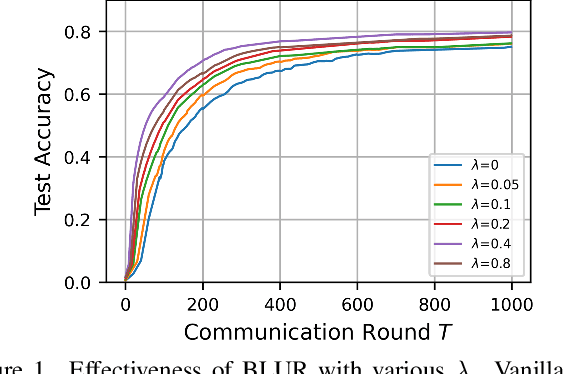
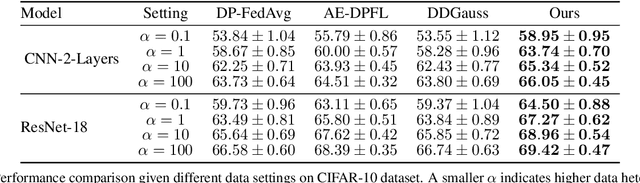
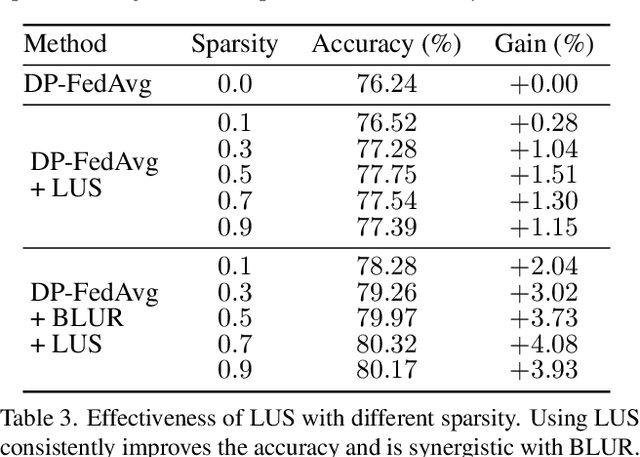
User-level differential privacy (DP) provides certifiable privacy guarantees to the information that is specific to any user's data in federated learning. Existing methods that ensure user-level DP come at the cost of severe accuracy decrease. In this paper, we study the cause of model performance degradation in federated learning under user-level DP guarantee. We find the key to solving this issue is to naturally restrict the norm of local updates before executing operations that guarantee DP. To this end, we propose two techniques, Bounded Local Update Regularization and Local Update Sparsification, to increase model quality without sacrificing privacy. We provide theoretical analysis on the convergence of our framework and give rigorous privacy guarantees. Extensive experiments show that our framework significantly improves the privacy-utility trade-off over the state-of-the-arts for federated learning with user-level DP guarantee.
DPNAS: Neural Architecture Search for Deep Learning with Differential Privacy
Oct 19, 2021



Training deep neural networks (DNNs) for meaningful differential privacy (DP) guarantees severely degrades model utility. In this paper, we demonstrate that the architecture of DNNs has a significant impact on model utility in the context of private deep learning, whereas its effect is largely unexplored in previous studies. In light of this missing, we propose the very first framework that employs neural architecture search to automatic model design for private deep learning, dubbed as DPNAS. To integrate private learning with architecture search, we delicately design a novel search space and propose a DP-aware method for training candidate models. We empirically certify the effectiveness of the proposed framework. The searched model DPNASNet achieves state-of-the-art privacy/utility trade-offs, e.g., for the privacy budget of $(\epsilon, \delta)=(3, 1\times10^{-5})$, our model obtains test accuracy of $98.57\%$ on MNIST, $88.09\%$ on FashionMNIST, and $68.33\%$ on CIFAR-10. Furthermore, by studying the generated architectures, we provide several intriguing findings of designing private-learning-friendly DNNs, which can shed new light on model design for deep learning with differential privacy.
SpatialFlow: Bridging All Tasks for Panoptic Segmentation
Dec 02, 2019
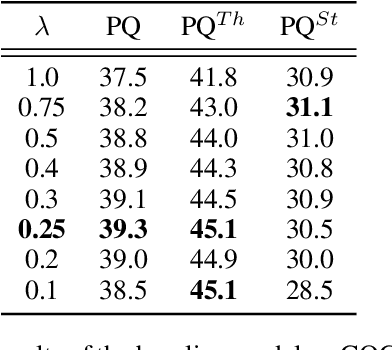
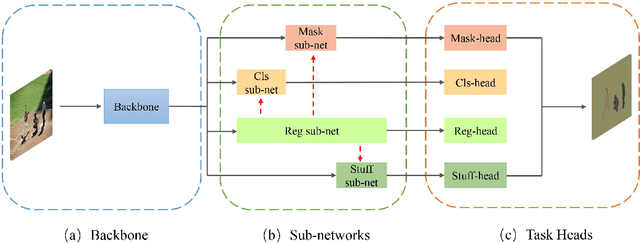
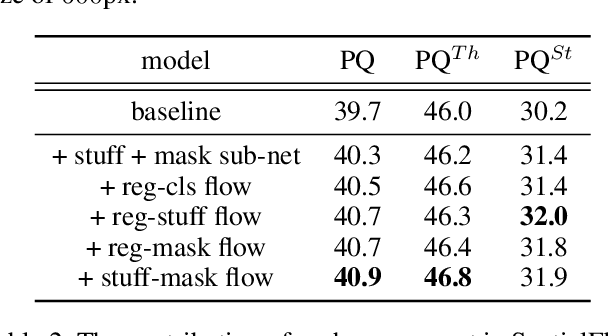
Object location is fundamental to panoptic segmentation as it is related to all things and stuff. How to integrate object location in both thing and stuff segmentation is a crucial problem. In this paper, we propose object spatial information flows to achieve this objective. More importantly, we design four parallel sub-networks for sub-tasks in panoptic segmentation, which leads to the preferable adaptation of object spatial information. With sub-networks, the flows can bridge all tasks together by delivering the object's spatial context from the box regression task to others. They can also provide clues for segmenting both things and stuff, which helps the network better understand the whole image. Upon the sub-networks and the flows, we present a location-aware and unified framework for panoptic segmentation, denoted as SpatialFlow. We perform a detailed ablation study on each component and conduct extensive experiments to prove the effectiveness of Our SpatialFlow. Furthermore, we achieve state-of-the-art results, which are $47.3$ PQ and $62.5$ PQ respectively on MS-COCO and Cityscapes panoptic benchmarks.
Location-aware Upsampling for Semantic Segmentation
Nov 14, 2019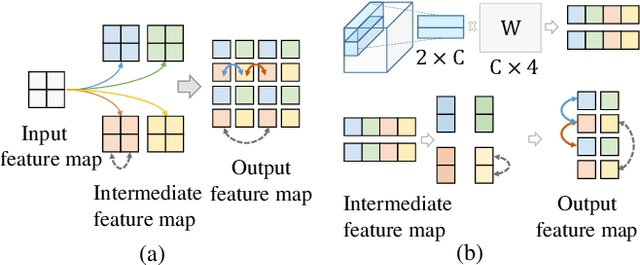
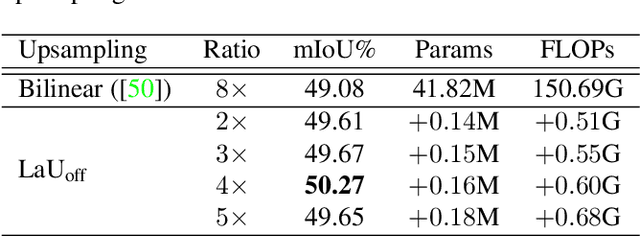
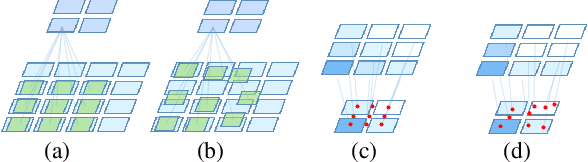

Many successful learning targets such as minimizing dice loss and cross-entropy loss have enabled unprecedented breakthroughs in segmentation tasks. Beyond these semantic metrics, this paper aims to introduce location supervision into semantic segmentation. Based on this idea, we present a Location-aware Upsampling (LaU) that adaptively refines the interpolating coordinates with trainable offsets. Then, location-aware losses are established by encouraging pixels to move towards well-classified locations. An LaU is offset prediction coupled with interpolation, which is trained end-to-end to generate confidence score at each position from coarse to fine. Guided by location-aware losses, the new module can replace its plain counterpart (\textit{e.g.}, bilinear upsampling) in a plug-and-play manner to further boost the leading encoder-decoder approaches. Extensive experiments validate the consistent improvement over the state-of-the-art methods on benchmark datasets. Our code is available at https://github.com/HolmesShuan/Location-aware-Upsampling-for-Semantic-Segmentation