 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Leakage from Embedding in Large Language Models
May 22, 2024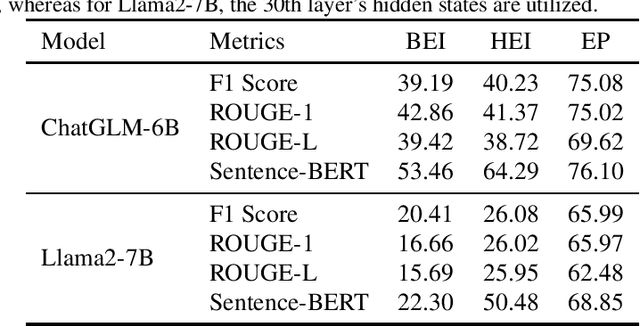
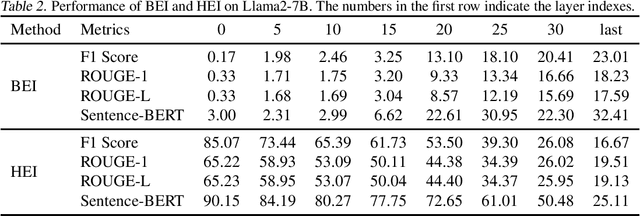
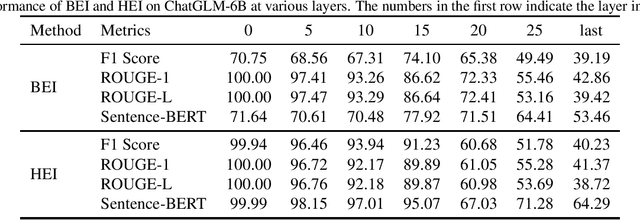
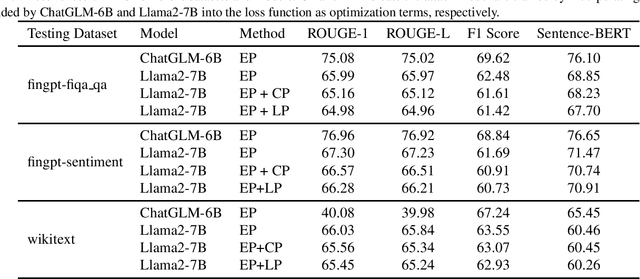
The widespread adoption of large language models (LLMs) has raised concerns regarding data privacy. This study aims to investigate the potential for privacy invasion through input reconstruction attacks, in which a malicious model provider could potentially recover user inputs from embeddings. We first propose two base methods to reconstruct original texts from a model's hidden states. We find that these two methods are effective in attacking the embeddings from shallow layers, but their effectiveness decreases when attacking embeddings from deeper layers. To address this issue, we then present Embed Parrot, a Transformer-based method, to reconstruct input from embeddings in deep layers. Our analysis reveals that Embed Parrot effectively reconstructs original inputs from the hidden states of ChatGLM-6B and Llama2-7B, showcasing stable performance across various token lengths and data distributions. To mitigate the risk of privacy breaches, we introduce a defense mechanism to deter exploitation of the embedding reconstruction process. Our findings emphasize the importance of safeguarding user privacy in distributed learning systems and contribute valuable insights to enhance the security protocols within such environments.