 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean Flow Policy Optimization
Apr 16, 2026Diffusion models have recently emerged as expressive policy representations for online reinforcement learning (RL). However, their iterative generative processes introduce substantial training and inference overhead. To overcome this limitation, we propose to represent policies using MeanFlow models, a class of few-step flow-based generative models, to improve training and inference efficiency over diffusion-based RL approaches. To promote exploration, we optimize MeanFlow policies under the maximum entropy RL framework via soft policy iteration, and address two key challenges specific to MeanFlow policies: action likelihood evaluation and soft policy improvement. Experiments on MuJoCo and DeepMind Control Suite benchmarks demonstrate that our method, Mean Flow Policy Optimization (MFPO), achieves performance comparable to or exceeding current diffusion-based baselines while considerably reducing training and inference time. Our code is available at https://github.com/MFPolicy/MFPO.
On Active Privacy Auditing in Supervised Fine-tuning for White-Box Language Models
Nov 12, 2024


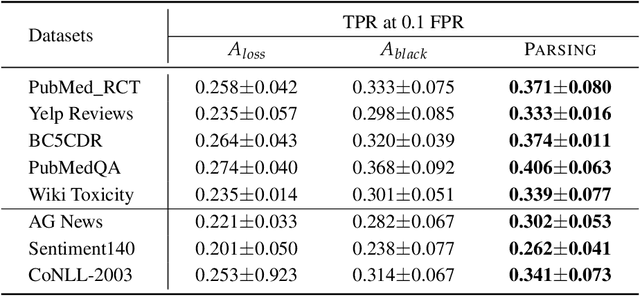
The pretraining and fine-tuning approach has become the leading technique for various NLP applications. However, recent studies reveal that fine-tuning data, due to their sensitive nature, domain-specific characteristics, and identifiability, pose significant privacy concerns. To help develop more privacy-resilient fine-tuning models, we introduce a novel active privacy auditing framework, dubbed Parsing, designed to identify and quantify privacy leakage risks during the supervised fine-tuning (SFT) of language models (LMs). The framework leverages improved white-box membership inference attacks (MIAs) as the core technology, utilizing novel learning objectives and a two-stage pipeline to monitor the privacy of the LMs' fine-tuning process, maximizing the exposure of privacy risks. Additionally, we have improved the effectiveness of MIAs on large LMs including GPT-2, Llama2, and certain variants of them. Our research aims to provide the SFT community of LMs with a reliable, ready-to-use privacy auditing tool, and to offer valuable insights into safeguarding privacy during the fine-tuning process. Experimental results confirm the framework's efficiency across various models and tasks, emphasizing notable privacy concerns in the fine-tuning process. Project code available for https://anonymous.4open.science/r/PARSING-4817/.
Differentially Private Federated Learning with Local Regularization and Sparsification
Mar 21, 2022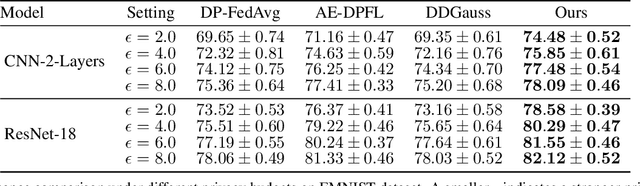
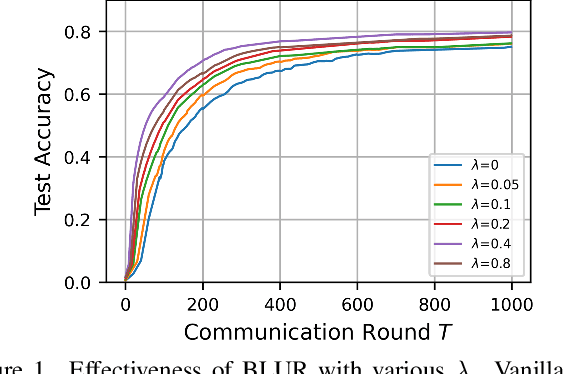
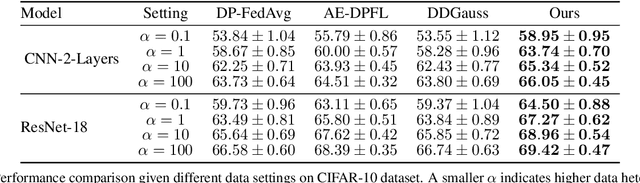
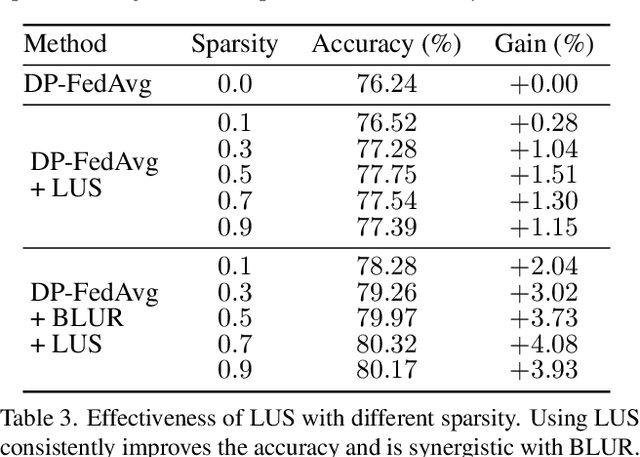
User-level differential privacy (DP) provides certifiable privacy guarantees to the information that is specific to any user's data in federated learning. Existing methods that ensure user-level DP come at the cost of severe accuracy decrease. In this paper, we study the cause of model performance degradation in federated learning under user-level DP guarantee. We find the key to solving this issue is to naturally restrict the norm of local updates before executing operations that guarantee DP. To this end, we propose two techniques, Bounded Local Update Regularization and Local Update Sparsification, to increase model quality without sacrificing privacy. We provide theoretical analysis on the convergence of our framework and give rigorous privacy guarantees. Extensive experiments show that our framework significantly improves the privacy-utility trade-off over the state-of-the-arts for federated learning with user-level DP guarantee.
APRIL: Finding the Achilles' Heel on Privacy for Vision Transformers
Dec 28, 2021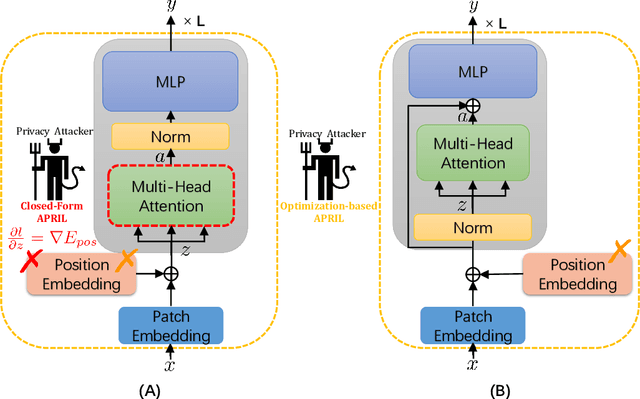



Federated learning frameworks typically require collaborators to share their local gradient updates of a common model instead of sharing training data to preserve privacy. However, prior works on Gradient Leakage Attacks showed that private training data can be revealed from gradients. So far almost all relevant works base their attacks on fully-connected or convolutional neural networks. Given the recent overwhelmingly rising trend of adapting Transformers to solve multifarious vision tasks, it is highly valuable to investigate the privacy risk of vision transformers. In this paper, we analyse the gradient leakage risk of self-attention based mechanism in both theoretical and practical manners. Particularly, we propose APRIL - Attention PRIvacy Leakage, which poses a strong threat to self-attention inspired models such as ViT. Showing how vision Transformers are at the risk of privacy leakage via gradients, we urge the significance of designing privacy-safer Transformer models and defending schemes.
Joint Channel and Weight Pruning for Model Acceleration on Moblie Devices
Nov 09, 2021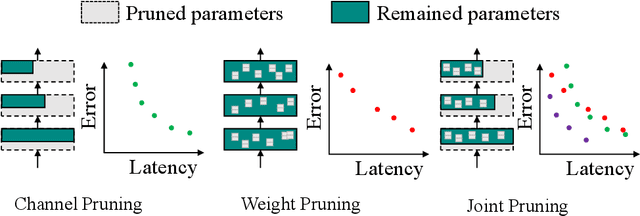
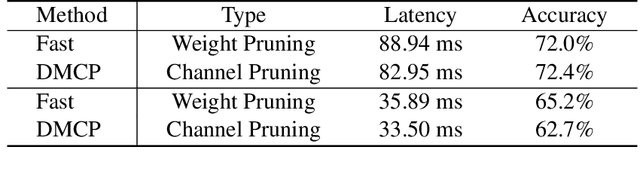
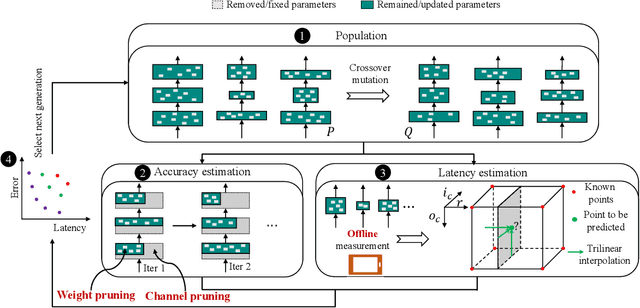
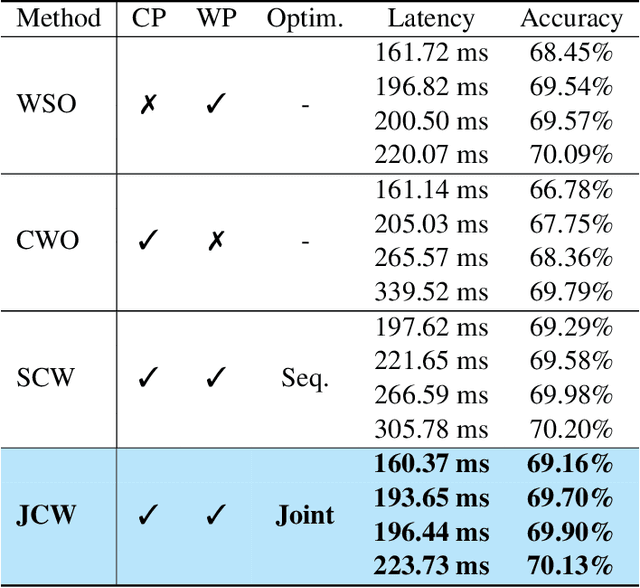
For practical deep neural network design on mobile devices, it is essential to consider the constraints incurred by the computational resources and the inference latency in various applications. Among deep network acceleration related approaches, pruning is a widely adopted practice to balance the computational resource consumption and the accuracy, where unimportant connections can be removed either channel-wisely or randomly with a minimal impact on model accuracy. The channel pruning instantly results in a significant latency reduction, while the random weight pruning is more flexible to balance the latency and accuracy. In this paper, we present a unified framework with Joint Channel pruning and Weight pruning (JCW), and achieves a better Pareto-frontier between the latency and accuracy than previous model compression approaches. To fully optimize the trade-off between the latency and accuracy, we develop a tailored multi-objective evolutionary algorithm in the JCW framework, which enables one single search to obtain the optimal candidate architectures for various deployment requirements. Extensive experiments demonstrate that the JCW achieves a better trade-off between the latency and accuracy against various state-of-the-art pruning methods on the ImageNet classification dataset. Our codes are available at https://github.com/jcw-anonymous/JCW.
DPNAS: Neural Architecture Search for Deep Learning with Differential Privacy
Oct 19, 2021



Training deep neural networks (DNNs) for meaningful differential privacy (DP) guarantees severely degrades model utility. In this paper, we demonstrate that the architecture of DNNs has a significant impact on model utility in the context of private deep learning, whereas its effect is largely unexplored in previous studies. In light of this missing, we propose the very first framework that employs neural architecture search to automatic model design for private deep learning, dubbed as DPNAS. To integrate private learning with architecture search, we delicately design a novel search space and propose a DP-aware method for training candidate models. We empirically certify the effectiveness of the proposed framework. The searched model DPNASNet achieves state-of-the-art privacy/utility trade-offs, e.g., for the privacy budget of $(\epsilon, \delta)=(3, 1\times10^{-5})$, our model obtains test accuracy of $98.57\%$ on MNIST, $88.09\%$ on FashionMNIST, and $68.33\%$ on CIFAR-10. Furthermore, by studying the generated architectures, we provide several intriguing findings of designing private-learning-friendly DNNs, which can shed new light on model design for deep learning with differential privacy.
MetaPred: Meta-Learning for Clinical Risk Prediction with Limited Patient Electronic Health Records
May 08, 2019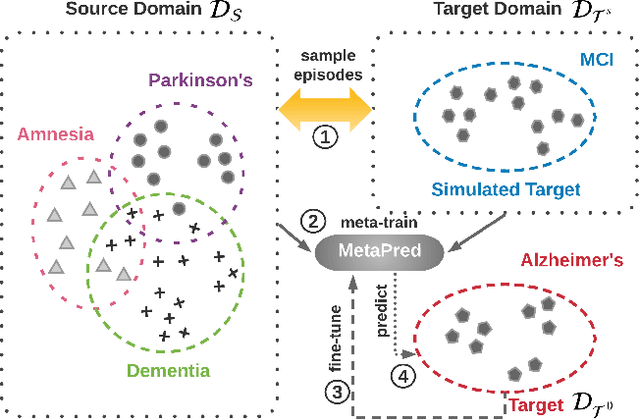
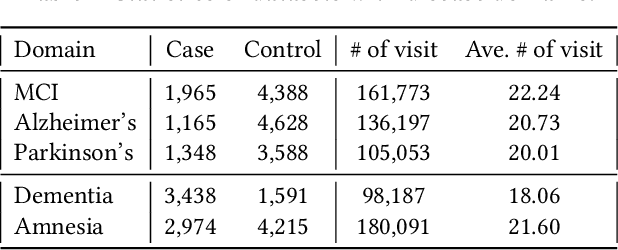
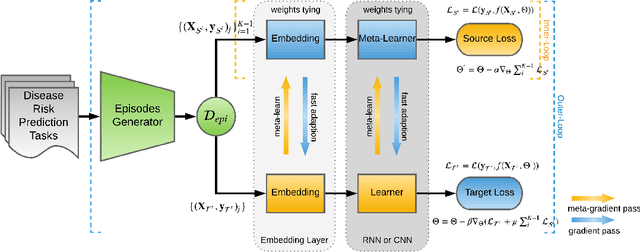
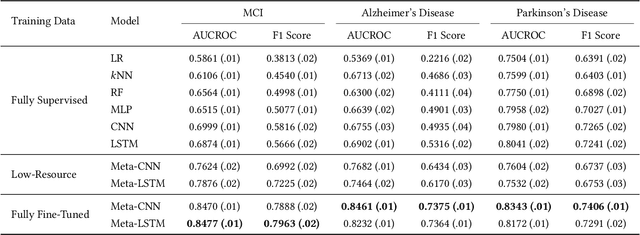
In recent years, increasingly augmentation of health data, such as patient Electronic Health Records (EHR), are becoming readily available. This provides an unprecedented opportunity for knowledge discovery and data mining algorithms to dig insights from them, which can, later on, be helpful to the improvement of the quality of care delivery. Predictive modeling of clinical risk, including in-hospital mortality, hospital readmission, chronic disease onset, condition exacerbation, etc., from patient EHR, is one of the health data analytic problems that attract most of the interests. The reason is not only because the problem is important in clinical settings, but also there are challenges working with EHR such as sparsity, irregularity, temporality, etc. Different from applications in other domains such as computer vision and natural language processing, the labeled data samples in medicine (patients) are relatively limited, which creates lots of troubles for effective predictive model learning, especially for complicated models such as deep learning. In this paper, we propose MetaPred, a meta-learning for clinical risk prediction from longitudinal patient EHRs. In particular, in order to predict the target risk where there are limited data samples, we train a meta-learner from a set of related risk prediction tasks which learns how a good predictor is learned. The meta-learned can then be directly used in target risk prediction, and the limited available samples can be used for further fine-tuning the model performance. The effectiveness of MetaPred is tested on a real patient EHR repository from Oregon Health & Science University. We are able to demonstrate that with CNN and RNN as base predictors, MetaPred can achieve much better performance for predicting target risk with low resources comparing with the predictor trained on the limited samples available for this risk.
Identification of Predictive Sub-Phenotypes of Acute Kidney Injury using Structured and Unstructured Electronic Health Record Data with Memory Networks
Apr 10, 2019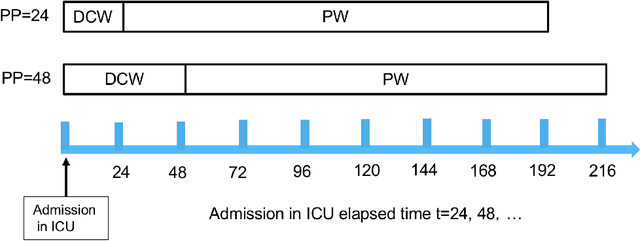
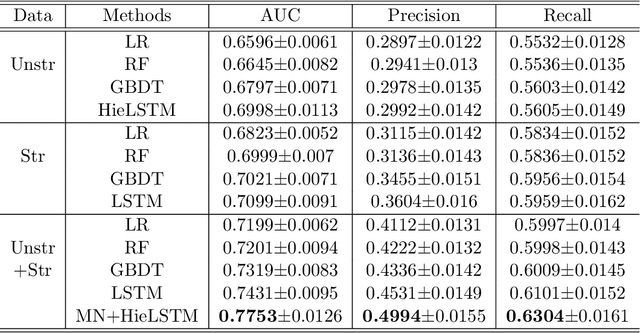
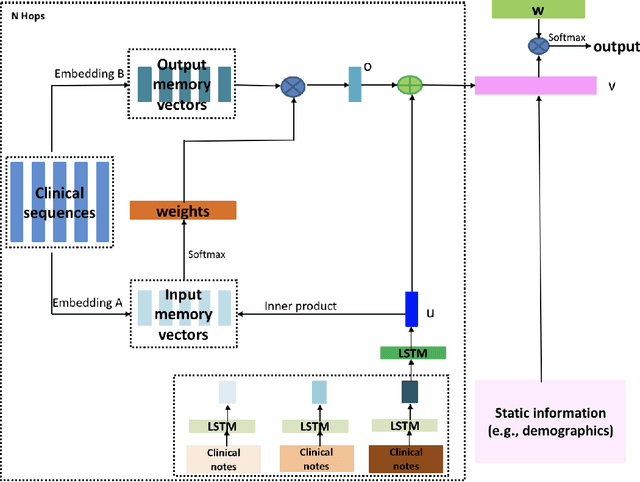
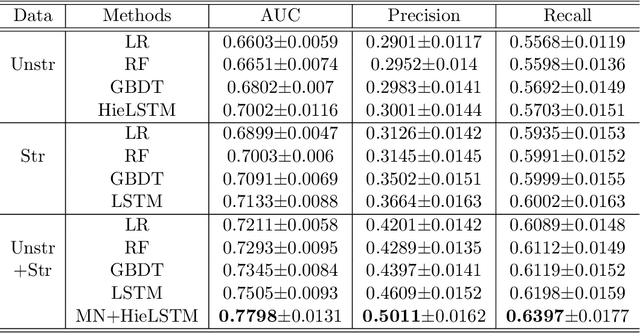
Acute Kidney Injury (AKI) is a common clinical syndrome characterized by the rapid loss of kidney excretory function, which aggravates the clinical severity of other diseases in a large number of hospitalized patients. Accurate early prediction of AKI can enable in-time interventions and treatments. However, AKI is highly heterogeneous, thus identification of AKI sub-phenotypes can lead to an improved understanding of the disease pathophysiology and development of more targeted clinical interventions. This study used a memory network-based deep learning approach to discover predictive AKI sub-phenotypes using structured and unstructured electronic health record (EHR) data of patients before AKI diagnosis. We leveraged a real world critical care EHR corpus including 37,486 ICU stays. Our approach identified three distinct sub-phenotypes: sub-phenotype I is with an average age of 63.03$ \pm 17.25 $ years, and is characterized by mild loss of kidney excretory function (Serum Creatinne (SCr) $1.55\pm 0.34$ mg/dL, estimated Glomerular Filtration Rate Test (eGFR) $107.65\pm 54.98$ mL/min/1.73$m^2$). These patients are more likely to develop stage I AKI. Sub-phenotype II is with average age 66.81$ \pm 10.43 $ years, and was characterized by severe loss of kidney excretory function (SCr $1.96\pm 0.49$ mg/dL, eGFR $82.19\pm 55.92$ mL/min/1.73$m^2$). These patients are more likely to develop stage III AKI. Sub-phenotype III is with average age 65.07$ \pm 11.32 $ years, and was characterized moderate loss of kidney excretory function and thus more likely to develop stage II AKI (SCr $1.69\pm 0.32$ mg/dL, eGFR $93.97\pm 56.53$ mL/min/1.73$m^2$). Both SCr and eGFR are significantly different across the three sub-phenotypes with statistical testing plus postdoc analysis, and the conclusion still holds after age adjustment.