 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Training-Free ANN-to-SNN Conversion for High-Performance Spiking Transformer
Aug 11, 2025Leveraging the event-driven paradigm, Spiking Neural Networks (SNNs) offer a promising approach for constructing energy-efficient Transformer architectures. Compared to directly trained Spiking Transformers, ANN-to-SNN conversion methods bypass the high training costs. However, existing methods still suffer from notable limitations, failing to effectively handle nonlinear operations in Transformer architectures and requiring additional fine-tuning processes for pre-trained ANNs. To address these issues, we propose a high-performance and training-free ANN-to-SNN conversion framework tailored for Transformer architectures. Specifically, we introduce a Multi-basis Exponential Decay (MBE) neuron, which employs an exponential decay strategy and multi-basis encoding method to efficiently approximate various nonlinear operations. It removes the requirement for weight modifications in pre-trained ANNs. Extensive experiments across diverse tasks (CV, NLU, NLG) and mainstream Transformer architectures (ViT, RoBERTa, GPT-2) demonstrate that our method achieves near-lossless conversion accuracy with significantly lower latency. This provides a promising pathway for the efficient and scalable deployment of Spiking Transformers in real-world applications.
Spiking Vision Transformer with Saccadic Attention
Feb 18, 2025The combination of Spiking Neural Networks (SNNs) and Vision Transformers (ViTs) holds potential for achieving both energy efficiency and high performance, particularly suitable for edge vision applications. However, a significant performance gap still exists between SNN-based ViTs and their ANN counterparts. Here, we first analyze why SNN-based ViTs suffer from limited performance and identify a mismatch between the vanilla self-attention mechanism and spatio-temporal spike trains. This mismatch results in degraded spatial relevance and limited temporal interactions. To address these issues, we draw inspiration from biological saccadic attention mechanisms and introduce an innovative Saccadic Spike Self-Attention (SSSA) method. Specifically, in the spatial domain, SSSA employs a novel spike distribution-based method to effectively assess the relevance between Query and Key pairs in SNN-based ViTs. Temporally, SSSA employs a saccadic interaction module that dynamically focuses on selected visual areas at each timestep and significantly enhances whole scene understanding through temporal interactions. Building on the SSSA mechanism, we develop a SNN-based Vision Transformer (SNN-ViT). Extensive experiments across various visual tasks demonstrate that SNN-ViT achieves state-of-the-art performance with linear computational complexity. The effectiveness and efficiency of the SNN-ViT highlight its potential for power-critical edge vision applications.
On Active Privacy Auditing in Supervised Fine-tuning for White-Box Language Models
Nov 12, 2024


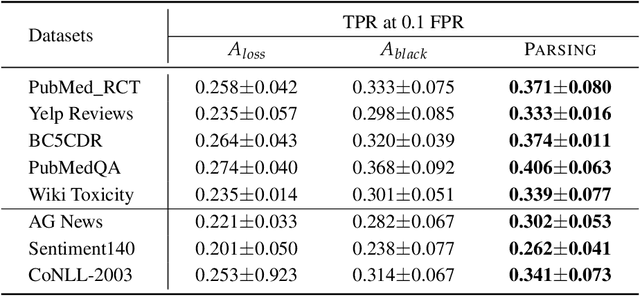
The pretraining and fine-tuning approach has become the leading technique for various NLP applications. However, recent studies reveal that fine-tuning data, due to their sensitive nature, domain-specific characteristics, and identifiability, pose significant privacy concerns. To help develop more privacy-resilient fine-tuning models, we introduce a novel active privacy auditing framework, dubbed Parsing, designed to identify and quantify privacy leakage risks during the supervised fine-tuning (SFT) of language models (LMs). The framework leverages improved white-box membership inference attacks (MIAs) as the core technology, utilizing novel learning objectives and a two-stage pipeline to monitor the privacy of the LMs' fine-tuning process, maximizing the exposure of privacy risks. Additionally, we have improved the effectiveness of MIAs on large LMs including GPT-2, Llama2, and certain variants of them. Our research aims to provide the SFT community of LMs with a reliable, ready-to-use privacy auditing tool, and to offer valuable insights into safeguarding privacy during the fine-tuning process. Experimental results confirm the framework's efficiency across various models and tasks, emphasizing notable privacy concerns in the fine-tuning process. Project code available for https://anonymous.4open.science/r/PARSING-4817/.
Horizon-wise Learning Paradigm Promotes Gene Splicing Identification
Jun 15, 2024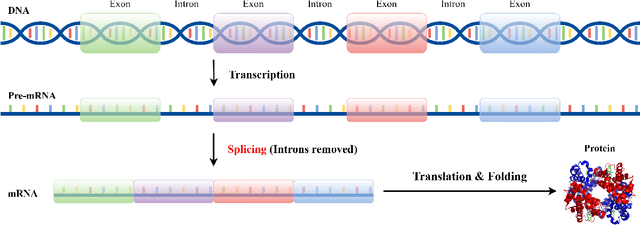
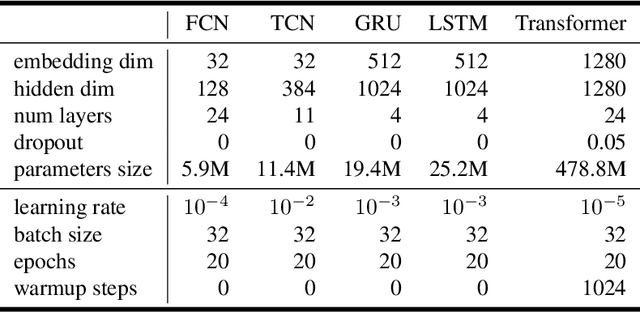
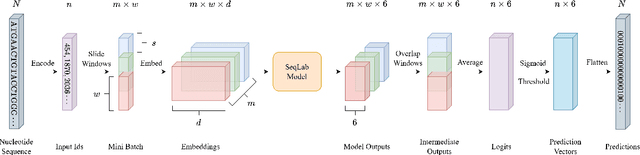
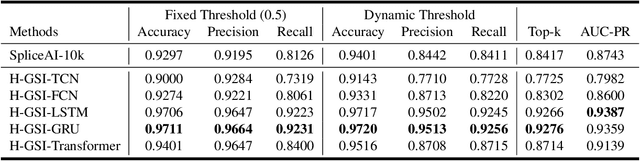
Identifying gene splicing is a core and significant task confronted in modern collaboration between artificial intelligence and bioinformatics. Past decades have witnessed great efforts on this concern, such as the bio-plausible splicing pattern AT-CG and the famous SpliceAI. In this paper, we propose a novel framework for the task of gene splicing identification, named Horizon-wise Gene Splicing Identification (H-GSI). The proposed H-GSI follows the horizon-wise identification paradigm and comprises four components: the pre-processing procedure transforming string data into tensors, the sliding window technique handling long sequences, the SeqLab model, and the predictor. In contrast to existing studies that process gene information with a truncated fixed-length sequence, H-GSI employs a horizon-wise identification paradigm in which all positions in a sequence are predicted with only one forward computation, improving accuracy and efficiency. The experiments conducted on the real-world Human dataset show that our proposed H-GSI outperforms SpliceAI and achieves the best accuracy of 97.20\%. The source code is available from this link.
Semi-Weakly Supervised Object Kinematic Motion Prediction
Apr 03, 2023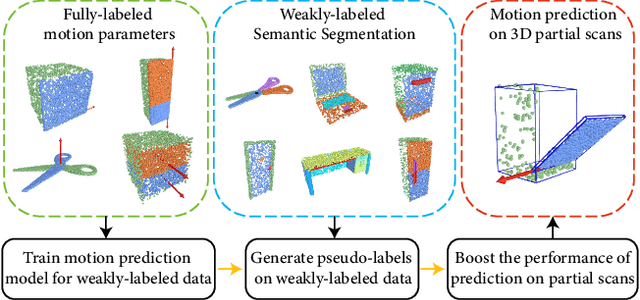
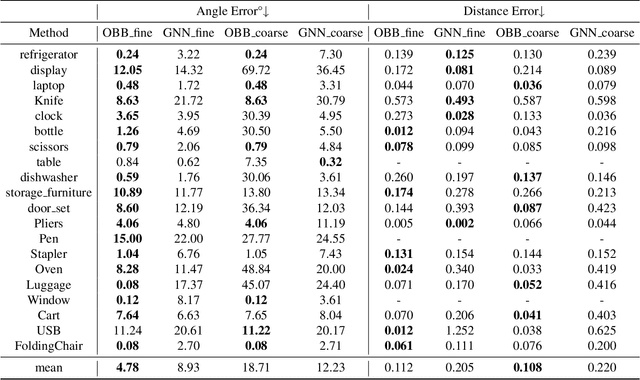
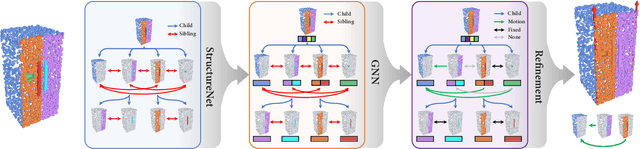

Given a 3D object, kinematic motion prediction aims to identify the mobile parts as well as the corresponding motion parameters. Due to the large variations in both topological structure and geometric details of 3D objects, this remains a challenging task and the lack of large scale labeled data also constrain the performance of deep learning based approaches. In this paper, we tackle the task of object kinematic motion prediction problem in a semi-weakly supervised manner. Our key observations are two-fold. First, although 3D dataset with fully annotated motion labels is limited, there are existing datasets and methods for object part semantic segmentation at large scale. Second, semantic part segmentation and mobile part segmentation is not always consistent but it is possible to detect the mobile parts from the underlying 3D structure. Towards this end, we propose a graph neural network to learn the map between hierarchical part-level segmentation and mobile parts parameters, which are further refined based on geometric alignment. This network can be first trained on PartNet-Mobility dataset with fully labeled mobility information and then applied on PartNet dataset with fine-grained and hierarchical part-level segmentation. The network predictions yield a large scale of 3D objects with pseudo labeled mobility information and can further be used for weakly-supervised learning with pre-existing segmentation. Our experiments show there are significant performance boosts with the augmented data for previous method designed for kinematic motion prediction on 3D partial scans.
Search By Image: Deeply Exploring Beneficial Features for Beauty Product Retrieval
Mar 24, 2023Searching by image is popular yet still challenging due to the extensive interference arose from i) data variations (e.g., background, pose, visual angle, brightness) of real-world captured images and ii) similar images in the query dataset. This paper studies a practically meaningful problem of beauty product retrieval (BPR) by neural networks. We broadly extract different types of image features, and raise an intriguing question that whether these features are beneficial to i) suppress data variations of real-world captured images, and ii) distinguish one image from others which look very similar but are intrinsically different beauty products in the dataset, therefore leading to an enhanced capability of BPR. To answer it, we present a novel variable-attention neural network to understand the combination of multiple features (termed VM-Net) of beauty product images. Considering that there are few publicly released training datasets for BPR, we establish a new dataset with more than one million images classified into more than 20K categories to improve both the generalization and anti-interference abilities of VM-Net and other methods. We verify the performance of VM-Net and its competitors on the benchmark dataset Perfect-500K, where VM-Net shows clear improvements over the competitors in terms of MAP@7. The source code and dataset will be released upon publication.
OPE-SR: Orthogonal Position Encoding for Designing a Parameter-free Upsampling Module in Arbitrary-scale Image Super-Resolution
Mar 02, 2023



Implicit neural representation (INR) is a popular approach for arbitrary-scale image super-resolution (SR), as a key component of INR, position encoding improves its representation ability. Motivated by position encoding, we propose orthogonal position encoding (OPE) - an extension of position encoding - and an OPE-Upscale module to replace the INR-based upsampling module for arbitrary-scale image super-resolution. Same as INR, our OPE-Upscale Module takes 2D coordinates and latent code as inputs; however it does not require training parameters. This parameter-free feature allows the OPE-Upscale Module to directly perform linear combination operations to reconstruct an image in a continuous manner, achieving an arbitrary-scale image reconstruction. As a concise SR framework, our method has high computing efficiency and consumes less memory comparing to the state-of-the-art (SOTA), which has been confirmed by extensive experiments and evaluations. In addition, our method has comparable results with SOTA in arbitrary scale image super-resolution. Last but not the least, we show that OPE corresponds to a set of orthogonal basis, justifying our design principle.
Semantic Segmentation by Improved Generative Adversarial Networks
Apr 20, 2021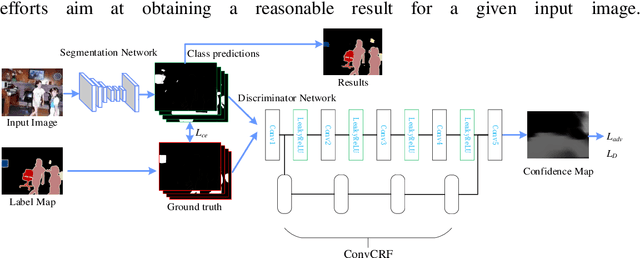


While most existing segmentation methods usually combined the powerful feature extraction capabilities of CNNs with Conditional Random Fields (CRFs) post-processing, the result always limited by the fault of CRFs . Due to the notoriously slow calculation speeds and poor efficiency of CRFs, in recent years, CRFs post-processing has been gradually eliminated. In this paper, an improved Generative Adversarial Networks (GANs) for image semantic segmentation task (semantic segmentation by GANs, Seg-GAN) is proposed to facilitate further segmentation research. In addition, we introduce Convolutional CRFs (ConvCRFs) as an effective improvement solution for the image semantic segmentation task. Towards the goal of differentiating the segmentation results from the ground truth distribution and improving the details of the output images, the proposed discriminator network is specially designed in a full convolutional manner combined with cascaded ConvCRFs. Besides, the adversarial loss aggressively encourages the output image to be close to the distribution of the ground truth. Our method not only learns an end-to-end mapping from input image to corresponding output image, but also learns a loss function to train this mapping. The experiments show that our method achieves better performance than state-of-the-art methods.
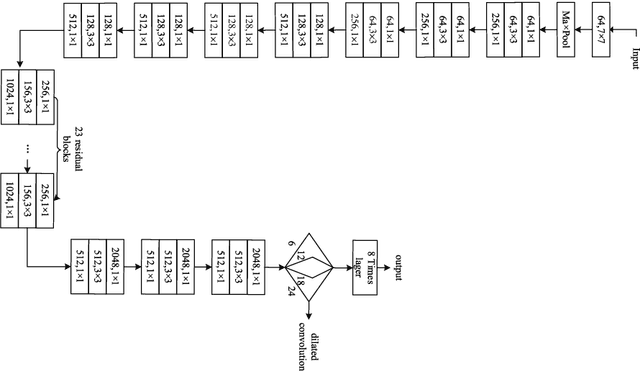
Superpixel Segmentation with Fully Convolutional Networks
Mar 29, 2020
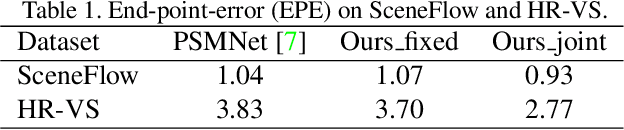

In computer vision, superpixels have been widely used as an effective way to reduce the number of image primitives for subsequent processing. But only a few attempts have been made to incorporate them into deep neural networks. One main reason is that the standard convolution operation is defined on regular grids and becomes inefficient when applied to superpixels. Inspired by an initialization strategy commonly adopted by traditional superpixel algorithms, we present a novel method that employs a simple fully convolutional network to predict superpixels on a regular image grid. Experimental results on benchmark datasets show that our method achieves state-of-the-art superpixel segmentation performance while running at about 50fps. Based on the predicted superpixels, we further develop a downsampling/upsampling scheme for deep networks with the goal of generating high-resolution outputs for dense prediction tasks. Specifically, we modify a popular network architecture for stereo matching to simultaneously predict superpixels and disparities. We show that improved disparity estimation accuracy can be obtained on public datasets.