 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTP-Spikformer: Token Pruned Spiking Transformer
Feb 28, 2026Spiking neural networks (SNNs) offer an energy-efficient alternative to traditional neural networks due to their event-driven computing paradigm. However, recent advancements in spiking transformers have focused on improving accuracy with large-scale architectures, which require significant computational resources and limit deployment on resource-constrained devices. In this paper, we propose a simple yet effective token pruning method for spiking transformers, termed TP-Spikformer, that reduces storage and computational overhead while maintaining competitive performance. Specifically, we first introduce a heuristic spatiotemporal information-retaining criterion that comprehensively evaluates tokens' importance, assigning higher scores to informative tokens for retention and lower scores to uninformative ones for pruning. Based on this criterion, we propose an information-retaining token pruning framework that employs a block-level early stopping strategy for uninformative tokens, instead of removing them outright. This also helps preserve more information during token pruning. We demonstrate the effectiveness, efficiency and scalability of TP-Spikformer through extensive experiments across diverse architectures, including Spikformer, QKFormer and Spike-driven Transformer V1 and V3, and a range of tasks such as image classification, object detection, semantic segmentation and event-based object tracking. Particularly, TP-Spikformer performs well in a training-free manner. These results reveal its potential as an efficient and practical solution for deploying SNNs in real-world applications with limited computational resources.
Robust Spiking Neural Networks Against Adversarial Attacks
Feb 24, 2026Spiking Neural Networks (SNNs) represent a promising paradigm for energy-efficient neuromorphic computing due to their bio-plausible and spike-driven characteristics. However, the robustness of SNNs in complex adversarial environments remains significantly constrained. In this study, we theoretically demonstrate that those threshold-neighboring spiking neurons are the key factors limiting the robustness of directly trained SNNs. We find that these neurons set the upper limits for the maximum potential strength of adversarial attacks and are prone to state-flipping under minor disturbances. To address this challenge, we propose a Threshold Guarding Optimization (TGO) method, which comprises two key aspects. First, we incorporate additional constraints into the loss function to move neurons' membrane potentials away from their thresholds. It increases SNNs' gradient sparsity, thereby reducing the theoretical upper bound of adversarial attacks. Second, we introduce noisy spiking neurons to transition the neuronal firing mechanism from deterministic to probabilistic, decreasing their state-flipping probability due to minor disturbances. Extensive experiments conducted in standard adversarial scenarios prove that our method significantly enhances the robustness of directly trained SNNs. These findings pave the way for advancing more reliable and secure neuromorphic computing in real-world applications.
Spiking Vision Transformer with Saccadic Attention
Feb 18, 2025



The combination of Spiking Neural Networks (SNNs) and Vision Transformers (ViTs) holds potential for achieving both energy efficiency and high performance, particularly suitable for edge vision applications. However, a significant performance gap still exists between SNN-based ViTs and their ANN counterparts. Here, we first analyze why SNN-based ViTs suffer from limited performance and identify a mismatch between the vanilla self-attention mechanism and spatio-temporal spike trains. This mismatch results in degraded spatial relevance and limited temporal interactions. To address these issues, we draw inspiration from biological saccadic attention mechanisms and introduce an innovative Saccadic Spike Self-Attention (SSSA) method. Specifically, in the spatial domain, SSSA employs a novel spike distribution-based method to effectively assess the relevance between Query and Key pairs in SNN-based ViTs. Temporally, SSSA employs a saccadic interaction module that dynamically focuses on selected visual areas at each timestep and significantly enhances whole scene understanding through temporal interactions. Building on the SSSA mechanism, we develop a SNN-based Vision Transformer (SNN-ViT). Extensive experiments across various visual tasks demonstrate that SNN-ViT achieves state-of-the-art performance with linear computational complexity. The effectiveness and efficiency of the SNN-ViT highlight its potential for power-critical edge vision applications.
QP-SNN: Quantized and Pruned Spiking Neural Networks
Feb 09, 2025



Brain-inspired Spiking Neural Networks (SNNs) leverage sparse spikes to encode information and operate in an asynchronous event-driven manner, offering a highly energy-efficient paradigm for machine intelligence. However, the current SNN community focuses primarily on performance improvement by developing large-scale models, which limits the applicability of SNNs in resource-limited edge devices. In this paper, we propose a hardware-friendly and lightweight SNN, aimed at effectively deploying high-performance SNN in resource-limited scenarios. Specifically, we first develop a baseline model that integrates uniform quantization and structured pruning, called QP-SNN baseline. While this baseline significantly reduces storage demands and computational costs, it suffers from performance decline. To address this, we conduct an in-depth analysis of the challenges in quantization and pruning that lead to performance degradation and propose solutions to enhance the baseline's performance. For weight quantization, we propose a weight rescaling strategy that utilizes bit width more effectively to enhance the model's representation capability. For structured pruning, we propose a novel pruning criterion using the singular value of spatiotemporal spike activities to enable more accurate removal of redundant kernels. Extensive experiments demonstrate that integrating two proposed methods into the baseline allows QP-SNN to achieve state-of-the-art performance and efficiency, underscoring its potential for enhancing SNN deployment in edge intelligence computing.
Single Image Dehazing Using Scene Depth Ordering
Aug 11, 2024



Images captured in hazy weather generally suffer from quality degradation, and many dehazing methods have been developed to solve this problem. However, single image dehazing problem is still challenging due to its ill-posed nature. In this paper, we propose a depth order guided single image dehazing method, which utilizes depth order in hazy images to guide the dehazing process to achieve a similar depth perception in corresponding dehazing results. The consistency of depth perception ensures that the regions that look farther or closer in hazy images also appear farther or closer in the corresponding dehazing results, and thus effectively avoid the undesired visual effects. To achieve this goal, a simple yet effective strategy is proposed to extract the depth order in hazy images, which offers a reference for depth perception in hazy weather. Additionally, a depth order embedded transformation model is devised, which performs transmission estimation under the guidance of depth order to realize an unchanged depth order in the dehazing results. The extracted depth order provides a powerful global constraint for the dehazing process, which contributes to the efficient utilization of global information, thereby bringing an overall improvement in restoration quality. Extensive experiments demonstrate that the proposed method can better recover potential structure and vivid color with higher computational efficiency than the state-of-the-art dehazing methods.
Advancing Spiking Neural Networks towards Multiscale Spatiotemporal Interaction Learning
May 22, 2024



Recent advancements in neuroscience research have propelled the development of Spiking Neural Networks (SNNs), which not only have the potential to further advance neuroscience research but also serve as an energy-efficient alternative to Artificial Neural Networks (ANNs) due to their spike-driven characteristics. However, previous studies often neglected the multiscale information and its spatiotemporal correlation between event data, leading SNN models to approximate each frame of input events as static images. We hypothesize that this oversimplification significantly contributes to the performance gap between SNNs and traditional ANNs. To address this issue, we have designed a Spiking Multiscale Attention (SMA) module that captures multiscale spatiotemporal interaction information. Furthermore, we developed a regularization method named Attention ZoneOut (AZO), which utilizes spatiotemporal attention weights to reduce the model's generalization error through pseudo-ensemble training. Our approach has achieved state-of-the-art results on mainstream neural morphology datasets. Additionally, we have reached a performance of 77.1% on the Imagenet-1K dataset using a 104-layer ResNet architecture enhanced with SMA and AZO. This achievement confirms the state-of-the-art performance of SNNs with non-transformer architectures and underscores the effectiveness of our method in bridging the performance gap between SNN models and traditional ANN models.
OR Residual Connection Achieving Comparable Accuracy to ADD Residual Connection in Deep Residual Spiking Neural Networks
Nov 11, 2023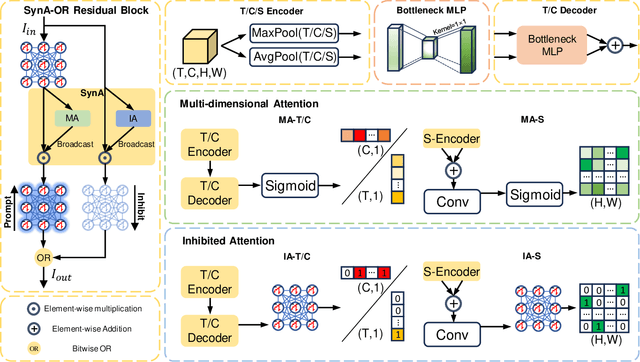
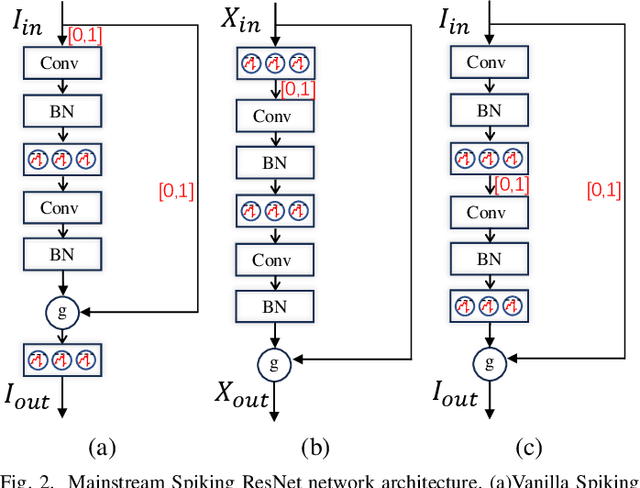
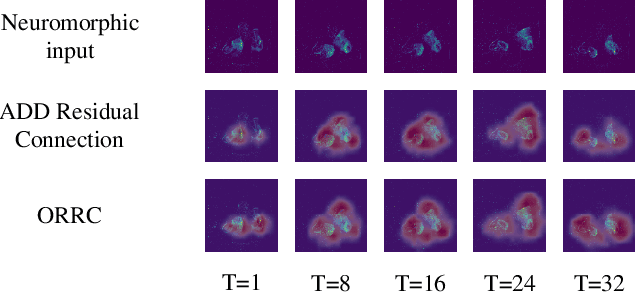
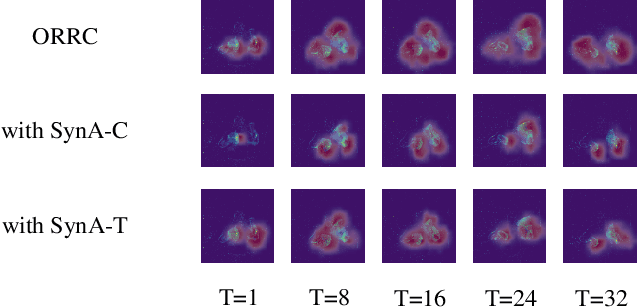
Spiking Neural Networks (SNNs) have garnered substantial attention in brain-like computing for their biological fidelity and the capacity to execute energy-efficient spike-driven operations. As the demand for heightened performance in SNNs surges, the trend towards training deeper networks becomes imperative, while residual learning stands as a pivotal method for training deep neural networks. In our investigation, we identified that the SEW-ResNet, a prominent representative of deep residual spiking neural networks, incorporates non-event-driven operations. To rectify this, we introduce the OR Residual connection (ORRC) to the architecture. Additionally, we propose the Synergistic Attention (SynA) module, an amalgamation of the Inhibitory Attention (IA) module and the Multi-dimensional Attention (MA) module, to offset energy loss stemming from high quantization. When integrating SynA into the network, we observed the phenomenon of "natural pruning", where after training, some or all of the shortcuts in the network naturally drop out without affecting the model's classification accuracy. This significantly reduces computational overhead and makes it more suitable for deployment on edge devices. Experimental results on various public datasets confirmed that the SynA enhanced OR-Spiking ResNet achieved single-sample classification with as little as 0.8 spikes per neuron. Moreover, when compared to other spike residual models, it exhibited higher accuracy and lower power consumption. Codes are available at https://github.com/Ym-Shan/ORRC-SynA-natural-pruning.