 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accurate Binary Spiking Neural Networks: Learning with Adaptive Gradient Modulation Mechanism
Feb 20, 2025



Binary Spiking Neural Networks (BSNNs) inherit the eventdriven paradigm of SNNs, while also adopting the reduced storage burden of binarization techniques. These distinct advantages grant BSNNs lightweight and energy-efficient characteristics, rendering them ideal for deployment on resource-constrained edge devices. However, due to the binary synaptic weights and non-differentiable spike function, effectively training BSNNs remains an open question. In this paper, we conduct an in-depth analysis of the challenge for BSNN learning, namely the frequent weight sign flipping problem. To mitigate this issue, we propose an Adaptive Gradient Modulation Mechanism (AGMM), which is designed to reduce the frequency of weight sign flipping by adaptively adjusting the gradients during the learning process. The proposed AGMM can enable BSNNs to achieve faster convergence speed and higher accuracy, effectively narrowing the gap between BSNNs and their full-precision equivalents. We validate AGMM on both static and neuromorphic datasets, and results indicate that it achieves state-of-the-art results among BSNNs. This work substantially reduces storage demands and enhances SNNs' inherent energy efficiency, making them highly feasible for resource-constrained environments.
QP-SNN: Quantized and Pruned Spiking Neural Networks
Feb 09, 2025



Brain-inspired Spiking Neural Networks (SNNs) leverage sparse spikes to encode information and operate in an asynchronous event-driven manner, offering a highly energy-efficient paradigm for machine intelligence. However, the current SNN community focuses primarily on performance improvement by developing large-scale models, which limits the applicability of SNNs in resource-limited edge devices. In this paper, we propose a hardware-friendly and lightweight SNN, aimed at effectively deploying high-performance SNN in resource-limited scenarios. Specifically, we first develop a baseline model that integrates uniform quantization and structured pruning, called QP-SNN baseline. While this baseline significantly reduces storage demands and computational costs, it suffers from performance decline. To address this, we conduct an in-depth analysis of the challenges in quantization and pruning that lead to performance degradation and propose solutions to enhance the baseline's performance. For weight quantization, we propose a weight rescaling strategy that utilizes bit width more effectively to enhance the model's representation capability. For structured pruning, we propose a novel pruning criterion using the singular value of spatiotemporal spike activities to enable more accurate removal of redundant kernels. Extensive experiments demonstrate that integrating two proposed methods into the baseline allows QP-SNN to achieve state-of-the-art performance and efficiency, underscoring its potential for enhancing SNN deployment in edge intelligence computing.
Binary Event-Driven Spiking Transformer
Jan 10, 2025



Transformer-based Spiking Neural Networks (SNNs) introduce a novel event-driven self-attention paradigm that combines the high performance of Transformers with the energy efficiency of SNNs. However, the larger model size and increased computational demands of the Transformer structure limit their practicality in resource-constrained scenarios. In this paper, we integrate binarization techniques into Transformer-based SNNs and propose the Binary Event-Driven Spiking Transformer, i.e. BESTformer. The proposed BESTformer can significantly reduce storage and computational demands by representing weights and attention maps with a mere 1-bit. However, BESTformer suffers from a severe performance drop from its full-precision counterpart due to the limited representation capability of binarization. To address this issue, we propose a Coupled Information Enhancement (CIE) method, which consists of a reversible framework and information enhancement distillation. By maximizing the mutual information between the binary model and its full-precision counterpart, the CIE method effectively mitigates the performance degradation of the BESTformer. Extensive experiments on static and neuromorphic datasets demonstrate that our method achieves superior performance to other binary SNNs, showcasing its potential as a compact yet high-performance model for resource-limited edge devices.
Q-SNNs: Quantized Spiking Neural Networks
Jun 19, 2024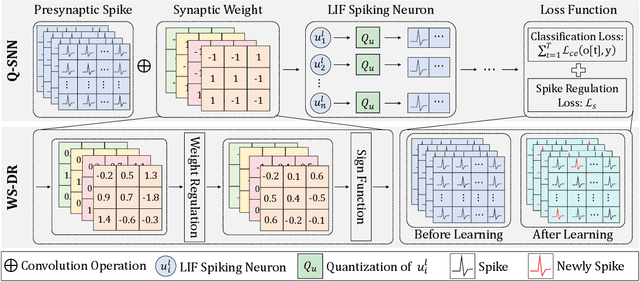
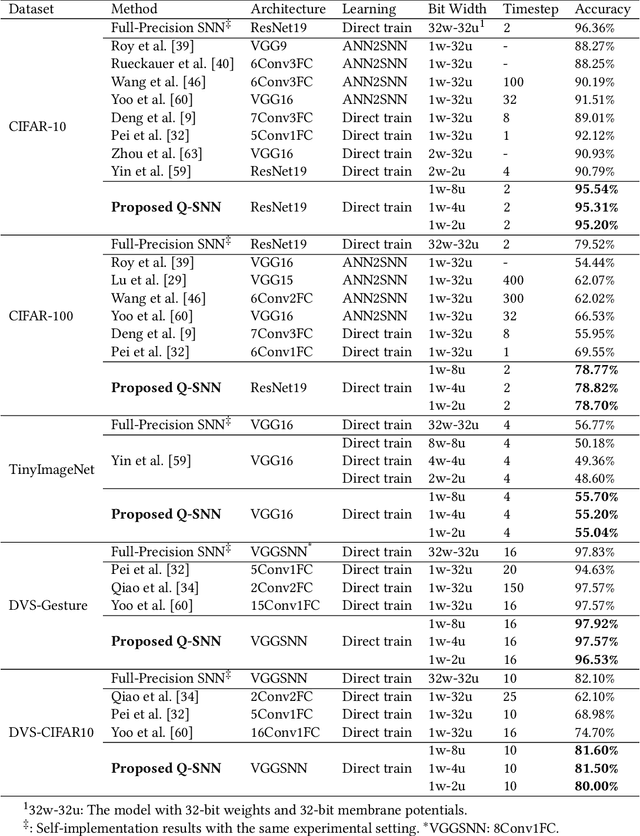
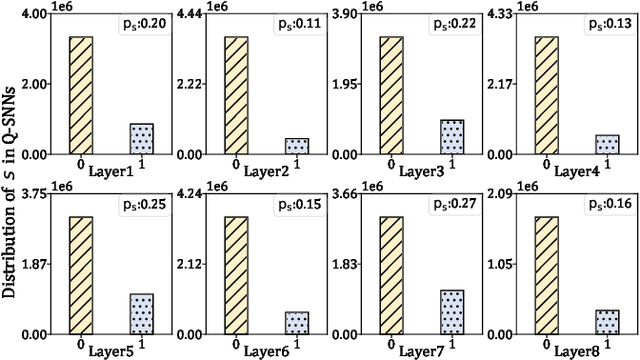
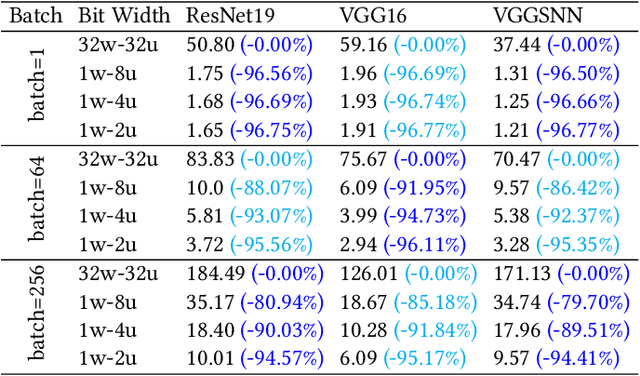
Brain-inspired Spiking Neural Networks (SNNs) leverage sparse spikes to represent information and process them in an asynchronous event-driven manner, offering an energy-efficient paradigm for the next generation of machine intelligence. However, the current focus within the SNN community prioritizes accuracy optimization through the development of large-scale models, limiting their viability in resource-constrained and low-power edge devices. To address this challenge, we introduce a lightweight and hardware-friendly Quantized SNN (Q-SNN) that applies quantization to both synaptic weights and membrane potentials. By significantly compressing these two key elements, the proposed Q-SNNs substantially reduce both memory usage and computational complexity. Moreover, to prevent the performance degradation caused by this compression, we present a new Weight-Spike Dual Regulation (WS-DR) method inspired by information entropy theory. Experimental evaluations on various datasets, including static and neuromorphic, demonstrate that our Q-SNNs outperform existing methods in terms of both model size and accuracy. These state-of-the-art results in efficiency and efficacy suggest that the proposed method can significantly improve edge intelligent computing.