 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\text{G}^2$RPO: Granular GRPO for Precise Reward in Flow Models
Oct 02, 2025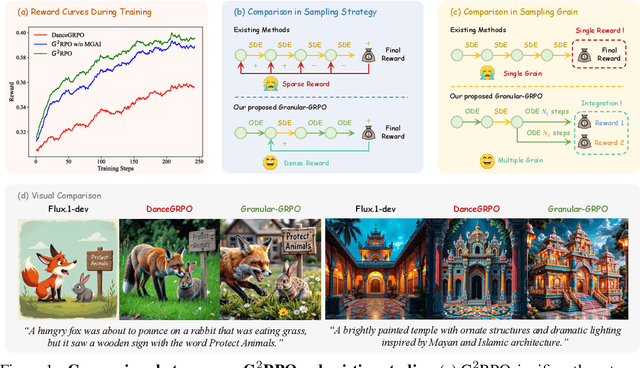
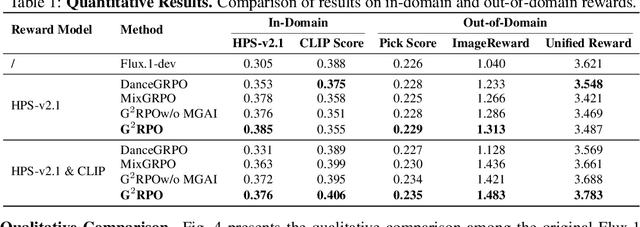
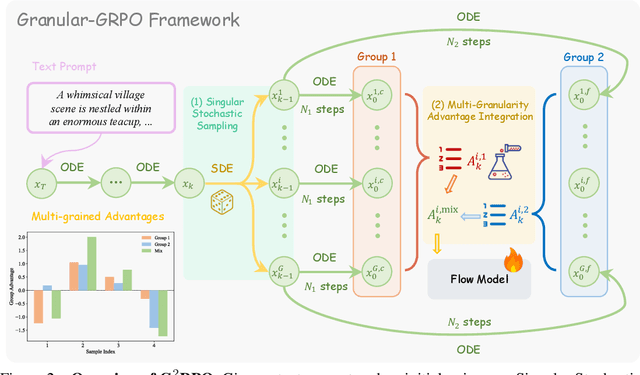
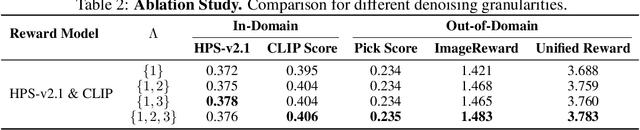
The integration of online reinforcement learning (RL) into diffusion and flow models has recently emerged as a promising approach for aligning generative models with human preferences. Stochastic sampling via Stochastic Differential Equations (SDE) is employed during the denoising process to generate diverse denoising directions for RL exploration. While existing methods effectively explore potential high-value samples, they suffer from sub-optimal preference alignment due to sparse and narrow reward signals. To address these challenges, we propose a novel Granular-GRPO ($\text{G}^2$RPO ) framework that achieves precise and comprehensive reward assessments of sampling directions in reinforcement learning of flow models. Specifically, a Singular Stochastic Sampling strategy is introduced to support step-wise stochastic exploration while enforcing a high correlation between the reward and the injected noise, thereby facilitating a faithful reward for each SDE perturbation. Concurrently, to eliminate the bias inherent in fixed-granularity denoising, we introduce a Multi-Granularity Advantage Integration module that aggregates advantages computed at multiple diffusion scales, producing a more comprehensive and robust evaluation of the sampling directions. Experiments conducted on various reward models, including both in-domain and out-of-domain evaluations, demonstrate that our $\text{G}^2$RPO significantly outperforms existing flow-based GRPO baselines,highlighting its effectiveness and robustness.
DiCache: Let Diffusion Model Determine Its Own Cache
Aug 24, 2025

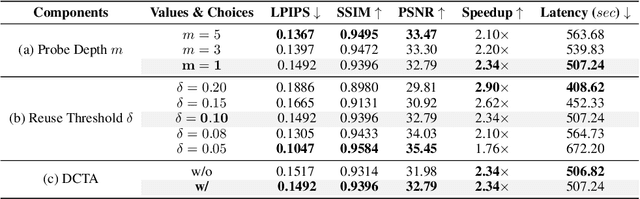
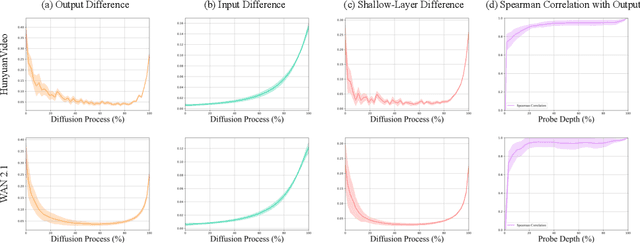
Recent years have witnessed the rapid development of acceleration techniques for diffusion models, especially caching-based acceleration methods. These studies seek to answer two fundamental questions: "When to cache" and "How to use cache", typically relying on predefined empirical laws or dataset-level priors to determine the timing of caching and utilizing handcrafted rules for leveraging multi-step caches. However, given the highly dynamic nature of the diffusion process, they often exhibit limited generalizability and fail on outlier samples. In this paper, a strong correlation is revealed between the variation patterns of the shallow-layer feature differences in the diffusion model and those of final model outputs. Moreover, we have observed that the features from different model layers form similar trajectories. Based on these observations, we present DiCache, a novel training-free adaptive caching strategy for accelerating diffusion models at runtime, answering both when and how to cache within a unified framework. Specifically, DiCache is composed of two principal components: (1) Online Probe Profiling Scheme leverages a shallow-layer online probe to obtain a stable prior for the caching error in real time, enabling the model to autonomously determine caching schedules. (2) Dynamic Cache Trajectory Alignment combines multi-step caches based on shallow-layer probe feature trajectory to better approximate the current feature, facilitating higher visual quality. Extensive experiments validate DiCache's capability in achieving higher efficiency and improved visual fidelity over state-of-the-art methods on various leading diffusion models including WAN 2.1, HunyuanVideo for video generation, and Flux for image generation.
HiFlow: Training-free High-Resolution Image Generation with Flow-Aligned Guidance
Apr 08, 2025Text-to-image (T2I) diffusion/flow models have drawn considerable attention recently due to their remarkable ability to deliver flexible visual creations. Still, high-resolution image synthesis presents formidable challenges due to the scarcity and complexity of high-resolution content. To this end, we present HiFlow, a training-free and model-agnostic framework to unlock the resolution potential of pre-trained flow models. Specifically, HiFlow establishes a virtual reference flow within the high-resolution space that effectively captures the characteristics of low-resolution flow information, offering guidance for high-resolution generation through three key aspects: initialization alignment for low-frequency consistency, direction alignment for structure preservation, and acceleration alignment for detail fidelity. By leveraging this flow-aligned guidance, HiFlow substantially elevates the quality of high-resolution image synthesis of T2I models and demonstrates versatility across their personalized variants. Extensive experiments validate HiFlow's superiority in achieving superior high-resolution image quality over current state-of-the-art methods.
Light-A-Video: Training-free Video Relighting via Progressive Light Fusion
Feb 12, 2025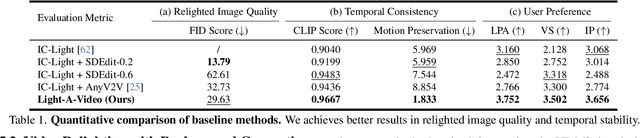
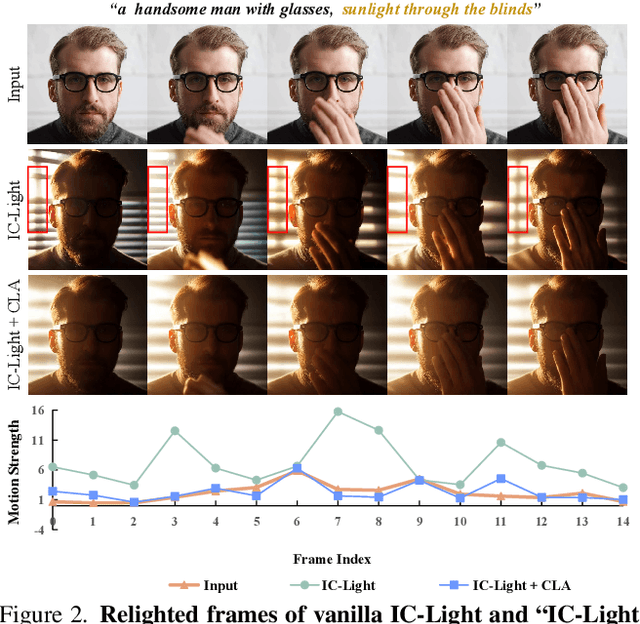
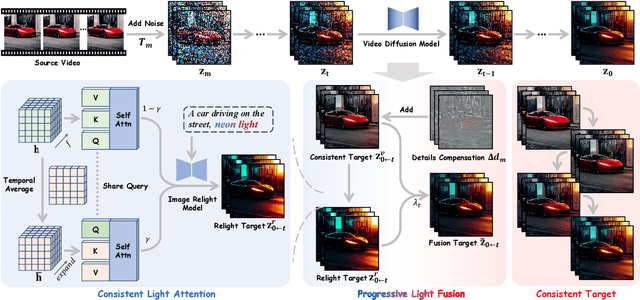
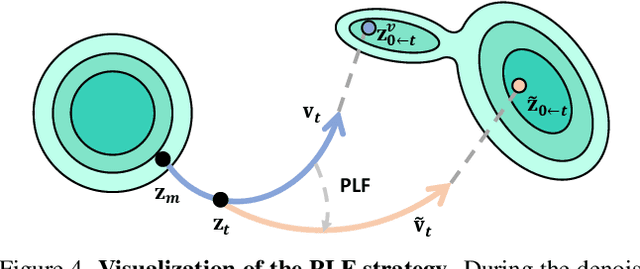
Recent advancements in image relighting models, driven by large-scale datasets and pre-trained diffusion models, have enabled the imposition of consistent lighting. However, video relighting still lags, primarily due to the excessive training costs and the scarcity of diverse, high-quality video relighting datasets. A simple application of image relighting models on a frame-by-frame basis leads to several issues: lighting source inconsistency and relighted appearance inconsistency, resulting in flickers in the generated videos. In this work, we propose Light-A-Video, a training-free approach to achieve temporally smooth video relighting. Adapted from image relighting models, Light-A-Video introduces two key techniques to enhance lighting consistency. First, we design a Consistent Light Attention (CLA) module, which enhances cross-frame interactions within the self-attention layers to stabilize the generation of the background lighting source. Second, leveraging the physical principle of light transport independence, we apply linear blending between the source video's appearance and the relighted appearance, using a Progressive Light Fusion (PLF) strategy to ensure smooth temporal transitions in illumination. Experiments show that Light-A-Video improves the temporal consistency of relighted video while maintaining the image quality, ensuring coherent lighting transitions across frames. Project page: https://bujiazi.github.io/light-a-video.github.io/.
BroadWay: Boost Your Text-to-Video Generation Model in a Training-free Way
Oct 08, 2024



The text-to-video (T2V) generation models, offering convenient visual creation, have recently garnered increasing attention. Despite their substantial potential, the generated videos may present artifacts, including structural implausibility, temporal inconsistency, and a lack of motion, often resulting in near-static video. In this work, we have identified a correlation between the disparity of temporal attention maps across different blocks and the occurrence of temporal inconsistencies. Additionally, we have observed that the energy contained within the temporal attention maps is directly related to the magnitude of motion amplitude in the generated videos. Based on these observations, we present BroadWay, a training-free method to improve the quality of text-to-video generation without introducing additional parameters, augmenting memory or sampling time. Specifically, BroadWay is composed of two principal components: 1) Temporal Self-Guidance improves the structural plausibility and temporal consistency of generated videos by reducing the disparity between the temporal attention maps across various decoder blocks. 2) Fourier-based Motion Enhancement enhances the magnitude and richness of motion by amplifying the energy of the map. Extensive experiments demonstrate that BroadWay significantly improves the quality of text-to-video generation with negligible additional cost.
Single Image Dehazing Using Scene Depth Ordering
Aug 11, 2024



Images captured in hazy weather generally suffer from quality degradation, and many dehazing methods have been developed to solve this problem. However, single image dehazing problem is still challenging due to its ill-posed nature. In this paper, we propose a depth order guided single image dehazing method, which utilizes depth order in hazy images to guide the dehazing process to achieve a similar depth perception in corresponding dehazing results. The consistency of depth perception ensures that the regions that look farther or closer in hazy images also appear farther or closer in the corresponding dehazing results, and thus effectively avoid the undesired visual effects. To achieve this goal, a simple yet effective strategy is proposed to extract the depth order in hazy images, which offers a reference for depth perception in hazy weather. Additionally, a depth order embedded transformation model is devised, which performs transmission estimation under the guidance of depth order to realize an unchanged depth order in the dehazing results. The extracted depth order provides a powerful global constraint for the dehazing process, which contributes to the efficient utilization of global information, thereby bringing an overall improvement in restoration quality. Extensive experiments demonstrate that the proposed method can better recover potential structure and vivid color with higher computational efficiency than the state-of-the-art dehazing methods.
MotionClone: Training-Free Motion Cloning for Controllable Video Generation
Jun 12, 2024Motion-based controllable text-to-video generation involves motions to control the video generation. Previous methods typically require the training of models to encode motion cues or the fine-tuning of video diffusion models. However, these approaches often result in suboptimal motion generation when applied outside the trained domain. In this work, we propose MotionClone, a training-free framework that enables motion cloning from a reference video to control text-to-video generation. We employ temporal attention in video inversion to represent the motions in the reference video and introduce primary temporal-attention guidance to mitigate the influence of noisy or very subtle motions within the attention weights. Furthermore, to assist the generation model in synthesizing reasonable spatial relationships and enhance its prompt-following capability, we propose a location-aware semantic guidance mechanism that leverages the coarse location of the foreground from the reference video and original classifier-free guidance features to guide the video generation. Extensive experiments demonstrate that MotionClone exhibits proficiency in both global camera motion and local object motion, with notable superiority in terms of motion fidelity, textual alignment, and temporal consistency.
ReasonPix2Pix: Instruction Reasoning Dataset for Advanced Image Editing
May 18, 2024Instruction-based image editing focuses on equipping a generative model with the capacity to adhere to human-written instructions for editing images. Current approaches typically comprehend explicit and specific instructions. However, they often exhibit a deficiency in executing active reasoning capacities required to comprehend instructions that are implicit or insufficiently defined. To enhance active reasoning capabilities and impart intelligence to the editing model, we introduce ReasonPix2Pix, a comprehensive reasoning-attentive instruction editing dataset. The dataset is characterized by 1) reasoning instruction, 2) more realistic images from fine-grained categories, and 3) increased variances between input and edited images. When fine-tuned with our dataset under supervised conditions, the model demonstrates superior performance in instructional editing tasks, independent of whether the tasks require reasoning or not. The code, model, and dataset will be publicly available.
Seed Optimization with Frozen Generator for Superior Zero-shot Low-light Enhancement
Feb 15, 2024



In this work, we observe that the generators, which are pre-trained on massive natural images, inherently hold the promising potential for superior low-light image enhancement against varying scenarios.Specifically, we embed a pre-trained generator to Retinex model to produce reflectance maps with enhanced detail and vividness, thereby recovering features degraded by low-light conditions.Taking one step further, we introduce a novel optimization strategy, which backpropagates the gradients to the input seeds rather than the parameters of the low-light enhancement model, thus intactly retaining the generative knowledge learned from natural images and achieving faster convergence speed. Benefiting from the pre-trained knowledge and seed-optimization strategy, the low-light enhancement model can significantly regularize the realness and fidelity of the enhanced result, thus rapidly generating high-quality images without training on any low-light dataset. Extensive experiments on various benchmarks demonstrate the superiority of the proposed method over numerous state-of-the-art methods qualitatively and quantitatively.
Masked Pre-trained Model Enables Universal Zero-shot Denoiser
Jan 26, 2024In this work, we observe that the model, which is trained on vast general images using masking strategy, has been naturally embedded with the distribution knowledge regarding natural images, and thus spontaneously attains the underlying potential for strong image denoising. Based on this observation, we propose a novel zero-shot denoising paradigm, i.e., Masked Pre-train then Iterative fill (MPI). MPI pre-trains a model with masking and fine-tunes it for denoising of a single image with unseen noise degradation. Concretely, the proposed MPI comprises two key procedures: 1) Masked Pre-training involves training a model on multiple natural images with random masks to gather generalizable representations, allowing for practical applications in varying noise degradation and even in distinct image types. 2) Iterative filling is devised to efficiently fuse pre-trained knowledge for denoising. Similar to but distinct from pre-training, random masking is retained to bridge the gap, but only the predicted parts covered by masks are assembled for efficiency, which enables high-quality denoising within a limited number of iterations. Comprehensive experiments across various noisy scenarios underscore the notable advances of proposed MPI over previous approaches with a marked reduction in inference time. Code is available at https://github.com/krennic999/MPI.git.