 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference of Online Newton Methods with Nesterov's Accelerated Sketching
Apr 25, 2026Reliable decision-making with streaming data requires principled uncertainty quantification of online methods. While first-order methods enable efficient iterate updates, their inference procedures still require updating proper (covariance) matrices, incurring $O(d^2)$ time and memory complexity, and are sensitive to ill-conditioning and noise heterogeneity of the problem. This costly inference task offers an opportunity for more robust second-order methods, which are, however, bottlenecked by solving Newton systems with $O(d^3)$ complexity. In this paper, we address this gap by studying an online Newton method with Hessian averaging, where the Newton direction at each step is approximately computed using a sketch-and-project solver with Nesterov's acceleration, matching $O(d^2)$ complexity of first-order methods. For the proposed method, we quantify its uncertainty arising from both random data and randomized computation. Under standard smoothness and moment conditions, we establish global almost-sure convergence, prove asymptotic normality of the last iterate with a limiting covariance characterized by a Lyapunov equation, and develop a fully online covariance estimator with non-asymptotic convergence guarantees. We also connect the resulting uncertainty quantification to that of exact and sketched Newton methods without Nesterov's acceleration. Extensive experiments on regression models demonstrate the superiority of the proposed method for online inference.
VLA Knows Its Limits
Feb 24, 2026Action chunking has recently emerged as a standard practice in flow-based Vision-Language-Action (VLA) models. However, the effect and choice of the execution horizon - the number of actions to be executed from each predicted chunk - remains underexplored. In this work, we first show that varying the execution horizon leads to substantial performance deviations, with performance initially improving and then declining as the horizon increases. To uncover the reasons, we analyze the cross- and self-attention weights in flow-based VLAs and reveal two key phenomena: (i) intra-chunk actions attend invariantly to vision-language tokens, limiting adaptability to environmental changes; and (ii) the initial and terminal action tokens serve as stable anchors, forming latent centers around which intermediate actions are organized. Motivated by these insights, we interpret action self-attention weights as a proxy for the model's predictive limit and propose AutoHorizon, the first test-time method that dynamically estimates the execution horizon for each predicted action chunk to adapt to changing perceptual conditions. Across simulated and real-world robotic manipulation tasks, AutoHorizon is performant, incurs negligible computational overhead, and generalizes across diverse tasks and flow-based models.
Real-Time Robot Execution with Masked Action Chunking
Jan 27, 2026Real-time execution is essential for cyber-physical systems such as robots. These systems operate in dynamic real-world environments where even small delays can undermine responsiveness and compromise performance. Asynchronous inference has recently emerged as a system-level paradigm for real-time robot manipulation, enabling the next action chunk to be predicted while the current one is being executed. While this approach achieves real-time responsiveness, naive integration often results in execution failure. Previous methods attributed this failure to inter-chunk discontinuity and developed test-time algorithms to smooth chunk boundaries. In contrast, we identify another critical yet overlooked factor: intra-chunk inconsistency, where the robot's executed action chunk partially misaligns with its current perception. To address this, we propose REMAC, which learns corrective adjustments on the pretrained policy through masked action chunking, enabling the policy to remain resilient under mismatches between intended actions and actual execution during asynchronous inference. In addition, we introduce a prefix-preserved sampling procedure to reinforce inter-chunk continuity. Overall, our method delivers more reliable policies without incurring additional latency. Extensive experiments in both simulation and real-world settings demonstrate that our method enables faster task execution, maintains robustness across varying delays, and consistently achieves higher completion rates.
Distill Video Datasets into Images
Dec 16, 2025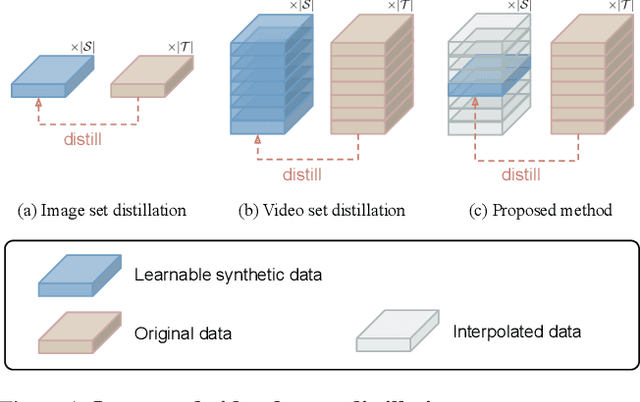
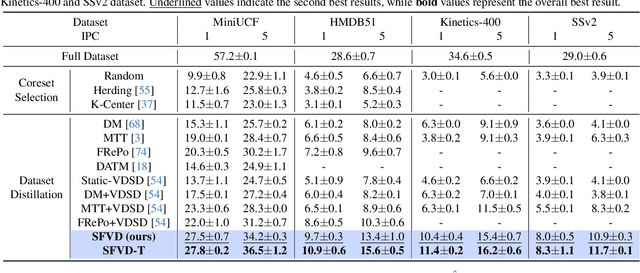
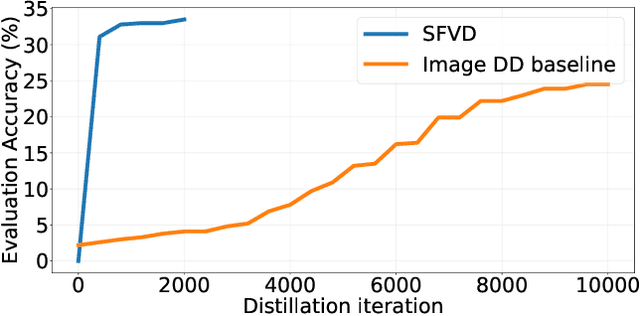
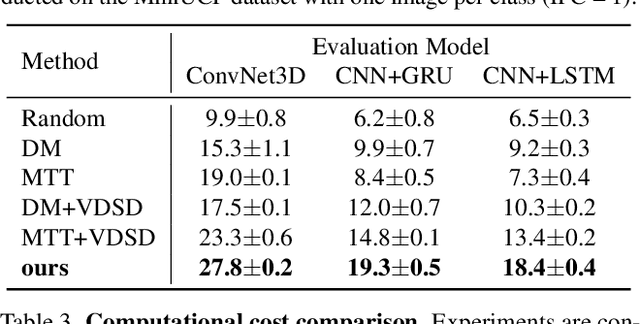
Dataset distillation aims to synthesize compact yet informative datasets that allow models trained on them to achieve performance comparable to training on the full dataset. While this approach has shown promising results for image data, extending dataset distillation methods to video data has proven challenging and often leads to suboptimal performance. In this work, we first identify the core challenge in video set distillation as the substantial increase in learnable parameters introduced by the temporal dimension of video, which complicates optimization and hinders convergence. To address this issue, we observe that a single frame is often sufficient to capture the discriminative semantics of a video. Leveraging this insight, we propose Single-Frame Video set Distillation (SFVD), a framework that distills videos into highly informative frames for each class. Using differentiable interpolation, these frames are transformed into video sequences and matched with the original dataset, while updates are restricted to the frames themselves for improved optimization efficiency. To further incorporate temporal information, the distilled frames are combined with sampled real videos from real videos during the matching process through a channel reshaping layer. Extensive experiments on multiple benchmarks demonstrate that SFVD substantially outperforms prior methods, achieving improvements of up to 5.3% on MiniUCF, thereby offering a more effective solution.
From Particles to Fields: Reframing Photon Mapping with Continuous Gaussian Photon Fields
Dec 13, 2025Accurately modeling light transport is essential for realistic image synthesis. Photon mapping provides physically grounded estimates of complex global illumination effects such as caustics and specular-diffuse interactions, yet its per-view radiance estimation remains computationally inefficient when rendering multiple views of the same scene. The inefficiency arises from independent photon tracing and stochastic kernel estimation at each viewpoint, leading to inevitable redundant computation. To accelerate multi-view rendering, we reformulate photon mapping as a continuous and reusable radiance function. Specifically, we introduce the Gaussian Photon Field (GPF), a learnable representation that encodes photon distributions as anisotropic 3D Gaussian primitives parameterized by position, rotation, scale, and spectrum. GPF is initialized from physically traced photons in the first SPPM iteration and optimized using multi-view supervision of final radiance, distilling photon-based light transport into a continuous field. Once trained, the field enables differentiable radiance evaluation along camera rays without repeated photon tracing or iterative refinement. Extensive experiments on scenes with complex light transport, such as caustics and specular-diffuse interactions, demonstrate that GPF attains photon-level accuracy while reducing computation by orders of magnitude, unifying the physical rigor of photon-based rendering with the efficiency of neural scene representations.
TraceFlow: Dynamic 3D Reconstruction of Specular Scenes Driven by Ray Tracing
Dec 10, 2025We present TraceFlow, a novel framework for high-fidelity rendering of dynamic specular scenes by addressing two key challenges: precise reflection direction estimation and physically accurate reflection modeling. To achieve this, we propose a Residual Material-Augmented 2D Gaussian Splatting representation that models dynamic geometry and material properties, allowing accurate reflection ray computation. Furthermore, we introduce a Dynamic Environment Gaussian and a hybrid rendering pipeline that decomposes rendering into diffuse and specular components, enabling physically grounded specular synthesis via rasterization and ray tracing. Finally, we devise a coarse-to-fine training strategy to improve optimization stability and promote physically meaningful decomposition. Extensive experiments on dynamic scene benchmarks demonstrate that TraceFlow outperforms prior methods both quantitatively and qualitatively, producing sharper and more realistic specular reflections in complex dynamic environments.
Efficient Multimodal Dataset Distillation via Generative Models
Sep 18, 2025Dataset distillation aims to synthesize a small dataset from a large dataset, enabling the model trained on it to perform well on the original dataset. With the blooming of large language models and multimodal large language models, the importance of multimodal datasets, particularly image-text datasets, has grown significantly. However, existing multimodal dataset distillation methods are constrained by the Matching Training Trajectories algorithm, which significantly increases the computing resource requirement, and takes days to process the distillation. In this work, we introduce EDGE, a generative distillation method for efficient multimodal dataset distillation. Specifically, we identify two key challenges of distilling multimodal datasets with generative models: 1) The lack of correlation between generated images and captions. 2) The lack of diversity among generated samples. To address the aforementioned issues, we propose a novel generative model training workflow with a bi-directional contrastive loss and a diversity loss. Furthermore, we propose a caption synthesis strategy to further improve text-to-image retrieval performance by introducing more text information. Our method is evaluated on Flickr30K, COCO, and CC3M datasets, demonstrating superior performance and efficiency compared to existing approaches. Notably, our method achieves results 18x faster than the state-of-the-art method.
STCOcc: Sparse Spatial-Temporal Cascade Renovation for 3D Occupancy and Scene Flow Prediction
Apr 28, 2025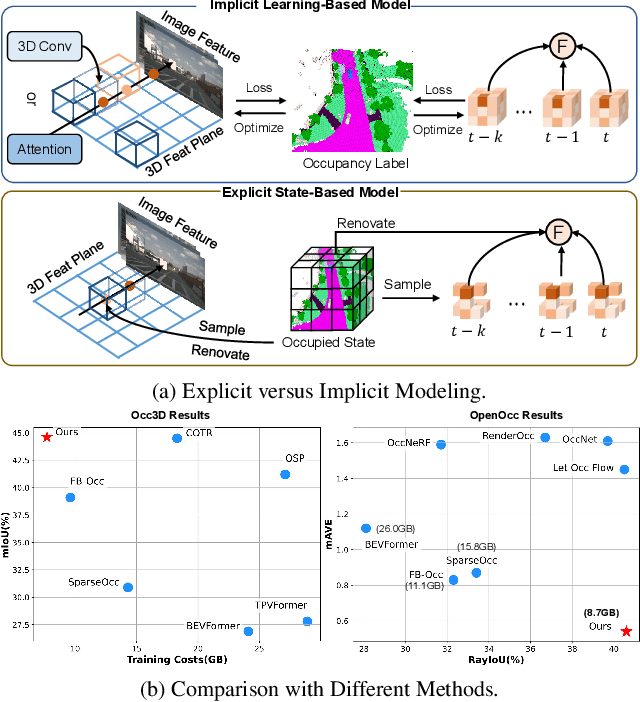
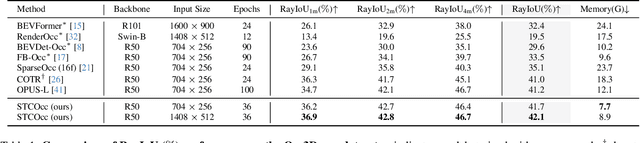
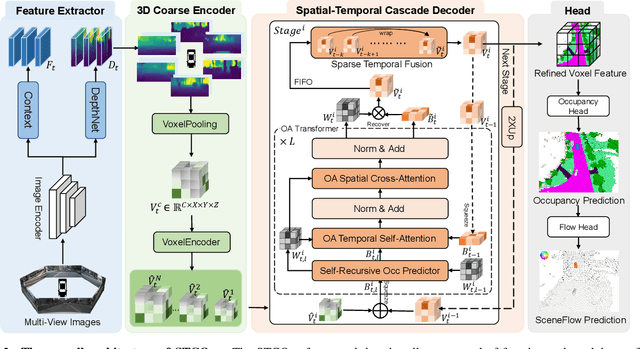
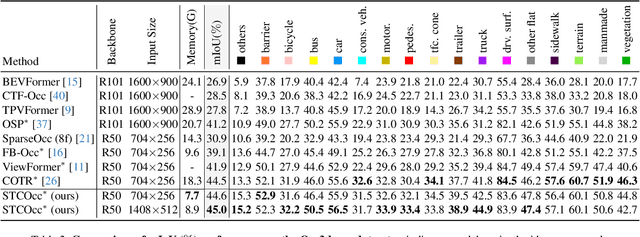
3D occupancy and scene flow offer a detailed and dynamic representation of 3D scene. Recognizing the sparsity and complexity of 3D space, previous vision-centric methods have employed implicit learning-based approaches to model spatial and temporal information. However, these approaches struggle to capture local details and diminish the model's spatial discriminative ability. To address these challenges, we propose a novel explicit state-based modeling method designed to leverage the occupied state to renovate the 3D features. Specifically, we propose a sparse occlusion-aware attention mechanism, integrated with a cascade refinement strategy, which accurately renovates 3D features with the guidance of occupied state information. Additionally, we introduce a novel method for modeling long-term dynamic interactions, which reduces computational costs and preserves spatial information. Compared to the previous state-of-the-art methods, our efficient explicit renovation strategy not only delivers superior performance in terms of RayIoU and mAVE for occupancy and scene flow prediction but also markedly reduces GPU memory usage during training, bringing it down to 8.7GB. Our code is available on https://github.com/lzzzzzm/STCOcc
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025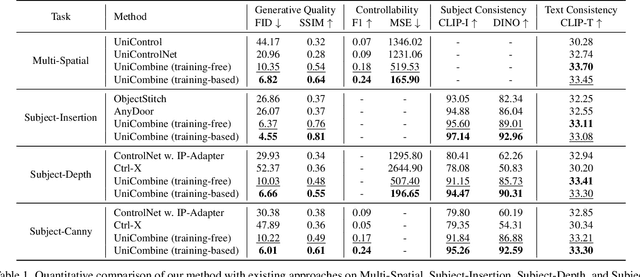
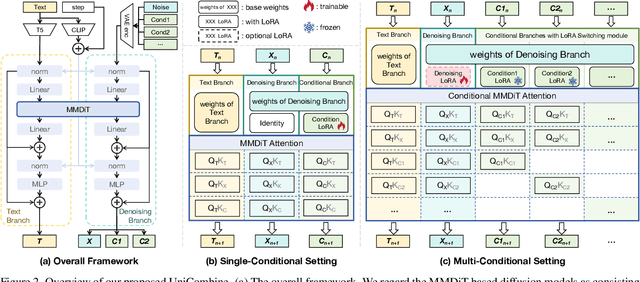
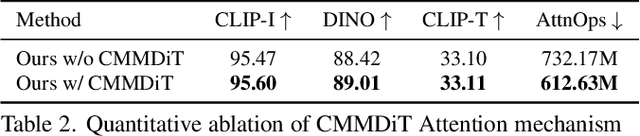
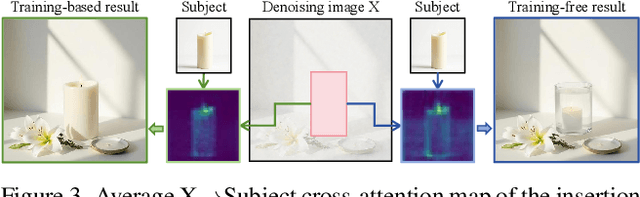
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
X-Field: A Physically Grounded Representation for 3D X-ray Reconstruction
Mar 11, 2025X-ray imaging is indispensable in medical diagnostics, yet its use is tightly regulated due to potential health risks. To mitigate radiation exposure, recent research focuses on generating novel views from sparse inputs and reconstructing Computed Tomography (CT) volumes, borrowing representations from the 3D reconstruction area. However, these representations originally target visible light imaging that emphasizes reflection and scattering effects, while neglecting penetration and attenuation properties of X-ray imaging. In this paper, we introduce X-Field, the first 3D representation specifically designed for X-ray imaging, rooted in the energy absorption rates across different materials. To accurately model diverse materials within internal structures, we employ 3D ellipsoids with distinct attenuation coefficients. To estimate each material's energy absorption of X-rays, we devise an efficient path partitioning algorithm accounting for complex ellipsoid intersections. We further propose hybrid progressive initialization to refine the geometric accuracy of X-Filed and incorporate material-based optimization to enhance model fitting along material boundaries. Experiments show that X-Field achieves superior visual fidelity on both real-world human organ and synthetic object datasets, outperforming state-of-the-art methods in X-ray Novel View Synthesis and CT Reconstruction.