 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection
Dec 30, 2025Existing Real-Time Object Detection (RTOD) methods commonly adopt YOLO-like architectures for their favorable trade-off between accuracy and speed. However, these models rely on static dense computation that applies uniform processing to all inputs, misallocating representational capacity and computational resources such as over-allocating on trivial scenes while under-serving complex ones. This mismatch results in both computational redundancy and suboptimal detection performance. To overcome this limitation, we propose YOLO-Master, a novel YOLO-like framework that introduces instance-conditional adaptive computation for RTOD. This is achieved through a Efficient Sparse Mixture-of-Experts (ES-MoE) block that dynamically allocates computational resources to each input according to its scene complexity. At its core, a lightweight dynamic routing network guides expert specialization during training through a diversity enhancing objective, encouraging complementary expertise among experts. Additionally, the routing network adaptively learns to activate only the most relevant experts, thereby improving detection performance while minimizing computational overhead during inference. Comprehensive experiments on five large-scale benchmarks demonstrate the superiority of YOLO-Master. On MS COCO, our model achieves 42.4% AP with 1.62ms latency, outperforming YOLOv13-N by +0.8% mAP and 17.8% faster inference. Notably, the gains are most pronounced on challenging dense scenes, while the model preserves efficiency on typical inputs and maintains real-time inference speed. Code will be available.
The devil is in the details: Enhancing Video Virtual Try-On via Keyframe-Driven Details Injection
Dec 23, 2025Although diffusion transformer (DiT)-based video virtual try-on (VVT) has made significant progress in synthesizing realistic videos, existing methods still struggle to capture fine-grained garment dynamics and preserve background integrity across video frames. They also incur high computational costs due to additional interaction modules introduced into DiTs, while the limited scale and quality of existing public datasets also restrict model generalization and effective training. To address these challenges, we propose a novel framework, KeyTailor, along with a large-scale, high-definition dataset, ViT-HD. The core idea of KeyTailor is a keyframe-driven details injection strategy, motivated by the fact that keyframes inherently contain both foreground dynamics and background consistency. Specifically, KeyTailor adopts an instruction-guided keyframe sampling strategy to filter informative frames from the input video. Subsequently,two tailored keyframe-driven modules, the garment details enhancement module and the collaborative background optimization module, are employed to distill garment dynamics into garment-related latents and to optimize the integrity of background latents, both guided by keyframes.These enriched details are then injected into standard DiT blocks together with pose, mask, and noise latents, enabling efficient and realistic try-on video synthesis. This design ensures consistency without explicitly modifying the DiT architecture, while simultaneously avoiding additional complexity. In addition, our dataset ViT-HD comprises 15, 070 high-quality video samples at a resolution of 810*1080, covering diverse garments. Extensive experiments demonstrate that KeyTailor outperforms state-of-the-art baselines in terms of garment fidelity and background integrity across both dynamic and static scenarios.
Soul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation
Dec 15, 2025We propose a multimodal-driven framework for high-fidelity long-term digital human animation termed $\textbf{Soul}$, which generates semantically coherent videos from a single-frame portrait image, text prompts, and audio, achieving precise lip synchronization, vivid facial expressions, and robust identity preservation. We construct Soul-1M, containing 1 million finely annotated samples with a precise automated annotation pipeline (covering portrait, upper-body, full-body, and multi-person scenes) to mitigate data scarcity, and we carefully curate Soul-Bench for comprehensive and fair evaluation of audio-/text-guided animation methods. The model is built on the Wan2.2-5B backbone, integrating audio-injection layers and multiple training strategies together with threshold-aware codebook replacement to ensure long-term generation consistency. Meanwhile, step/CFG distillation and a lightweight VAE are used to optimize inference efficiency, achieving an 11.4$\times$ speedup with negligible quality loss. Extensive experiments show that Soul significantly outperforms current leading open-source and commercial models on video quality, video-text alignment, identity preservation, and lip-synchronization accuracy, demonstrating broad applicability in real-world scenarios such as virtual anchors and film production. Project page at https://zhangzjn.github.io/projects/Soul/
Transform Trained Transformer: Accelerating Naive 4K Video Generation Over 10$\times$
Dec 15, 2025Native 4K (2160$\times$3840) video generation remains a critical challenge due to the quadratic computational explosion of full-attention as spatiotemporal resolution increases, making it difficult for models to strike a balance between efficiency and quality. This paper proposes a novel Transformer retrofit strategy termed $\textbf{T3}$ ($\textbf{T}$ransform $\textbf{T}$rained $\textbf{T}$ransformer) that, without altering the core architecture of full-attention pretrained models, significantly reduces compute requirements by optimizing their forward logic. Specifically, $\textbf{T3-Video}$ introduces a multi-scale weight-sharing window attention mechanism and, via hierarchical blocking together with an axis-preserving full-attention design, can effect an "attention pattern" transformation of a pretrained model using only modest compute and data. Results on 4K-VBench show that $\textbf{T3-Video}$ substantially outperforms existing approaches: while delivering performance improvements (+4.29$\uparrow$ VQA and +0.08$\uparrow$ VTC), it accelerates native 4K video generation by more than 10$\times$. Project page at https://zhangzjn.github.io/projects/T3-Video
RoleRMBench & RoleRM: Towards Reward Modeling for Profile-Based Role Play in Dialogue Systems
Dec 11, 2025Reward modeling has become a cornerstone of aligning large language models (LLMs) with human preferences. Yet, when extended to subjective and open-ended domains such as role play, existing reward models exhibit severe degradation, struggling to capture nuanced and persona-grounded human judgments. To address this gap, we introduce RoleRMBench, the first systematic benchmark for reward modeling in role-playing dialogue, covering seven fine-grained capabilities from narrative management to role consistency and engagement. Evaluation on RoleRMBench reveals large and consistent gaps between general-purpose reward models and human judgment, particularly in narrative and stylistic dimensions. We further propose RoleRM, a reward model trained with Continuous Implicit Preferences (CIP), which reformulates subjective evaluation as continuous consistent pairwise supervision under multiple structuring strategies. Comprehensive experiments show that RoleRM surpasses strong open- and closed-source reward models by over 24% on average, demonstrating substantial gains in narrative coherence and stylistic fidelity. Our findings highlight the importance of continuous preference representation and annotation consistency, establishing a foundation for subjective alignment in human-centered dialogue systems.
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Jul 02, 2025Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
Real-IAD D3: A Real-World 2D/Pseudo-3D/3D Dataset for Industrial Anomaly Detection
Apr 19, 2025The increasing complexity of industrial anomaly detection (IAD) has positioned multimodal detection methods as a focal area of machine vision research. However, dedicated multimodal datasets specifically tailored for IAD remain limited. Pioneering datasets like MVTec 3D have laid essential groundwork in multimodal IAD by incorporating RGB+3D data, but still face challenges in bridging the gap with real industrial environments due to limitations in scale and resolution. To address these challenges, we introduce Real-IAD D3, a high-precision multimodal dataset that uniquely incorporates an additional pseudo3D modality generated through photometric stereo, alongside high-resolution RGB images and micrometer-level 3D point clouds. Real-IAD D3 features finer defects, diverse anomalies, and greater scale across 20 categories, providing a challenging benchmark for multimodal IAD Additionally, we introduce an effective approach that integrates RGB, point cloud, and pseudo-3D depth information to leverage the complementary strengths of each modality, enhancing detection performance. Our experiments highlight the importance of these modalities in boosting detection robustness and overall IAD performance. The dataset and code are publicly accessible for research purposes at https://realiad4ad.github.io/Real-IAD D3
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025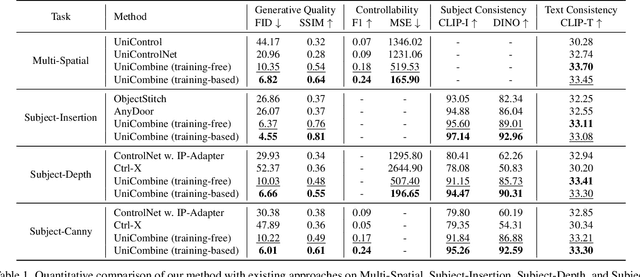
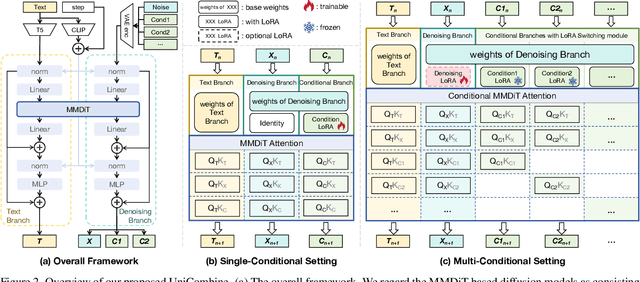
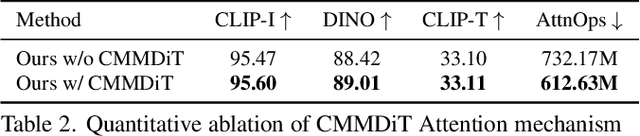
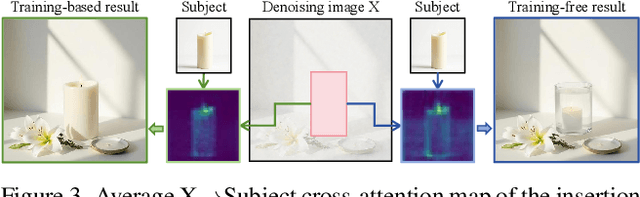
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
SoftPatch+: Fully Unsupervised Anomaly Classification and Segmentation
Dec 30, 2024



Although mainstream unsupervised anomaly detection (AD) (including image-level classification and pixel-level segmentation)algorithms perform well in academic datasets, their performance is limited in practical application due to the ideal experimental setting of clean training data. Training with noisy data is an inevitable problem in real-world anomaly detection but is seldom discussed. This paper is the first to consider fully unsupervised industrial anomaly detection (i.e., unsupervised AD with noisy data). To solve this problem, we proposed memory-based unsupervised AD methods, SoftPatch and SoftPatch+, which efficiently denoise the data at the patch level. Noise discriminators are utilized to generate outlier scores for patch-level noise elimination before coreset construction. The scores are then stored in the memory bank to soften the anomaly detection boundary. Compared with existing methods, SoftPatch maintains a strong modeling ability of normal data and alleviates the overconfidence problem in coreset, and SoftPatch+ has more robust performance which is articularly useful in real-world industrial inspection scenarios with high levels of noise (from 10% to 40%). Comprehensive experiments conducted in diverse noise scenarios demonstrate that both SoftPatch and SoftPatch+ outperform the state-of-the-art AD methods on the MVTecAD, ViSA, and BTAD benchmarks. Furthermore, the performance of SoftPatch and SoftPatch+ is comparable to that of the noise-free methods in conventional unsupervised AD setting. The code of the proposed methods can be found at https://github.com/TencentYoutuResearch/AnomalyDetection-SoftPatch.