 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-AD: Learning to Reconstruct Global and Local Features for Multi-class Anomaly Detection
Mar 27, 2025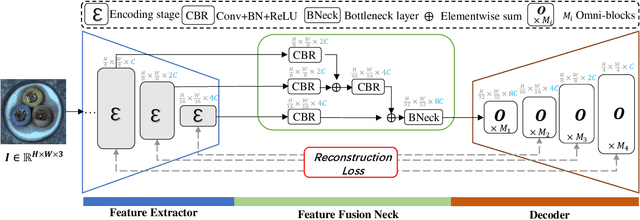



In multi-class unsupervised anomaly detection(MUAD), reconstruction-based methods learn to map input images to normal patterns to identify anomalous pixels. However, this strategy easily falls into the well-known "learning shortcut" issue when decoders fail to capture normal patterns and reconstruct both normal and abnormal samples naively. To address that, we propose to learn the input features in global and local manners, forcing the network to memorize the normal patterns more comprehensively. Specifically, we design a two-branch decoder block, named Omni-block. One branch corresponds to global feature learning, where we serialize two self-attention blocks but replace the query and (key, value) with learnable tokens, respectively, thus capturing global features of normal patterns concisely and thoroughly. The local branch comprises depth-separable convolutions, whose locality enables effective and efficient learning of local features for normal patterns. By stacking Omni-blocks, we build a framework, Omni-AD, to learn normal patterns of different granularity and reconstruct them progressively. Comprehensive experiments on public anomaly detection benchmarks show that our method outperforms state-of-the-art approaches in MUAD. Code is available at https://github.com/easyoo/Omni-AD.git.
LLaVA-KD: A Framework of Distilling Multimodal Large Language Models
Oct 21, 2024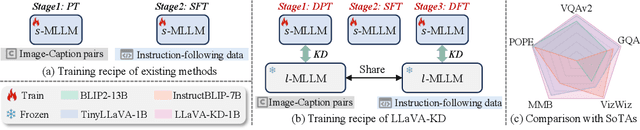
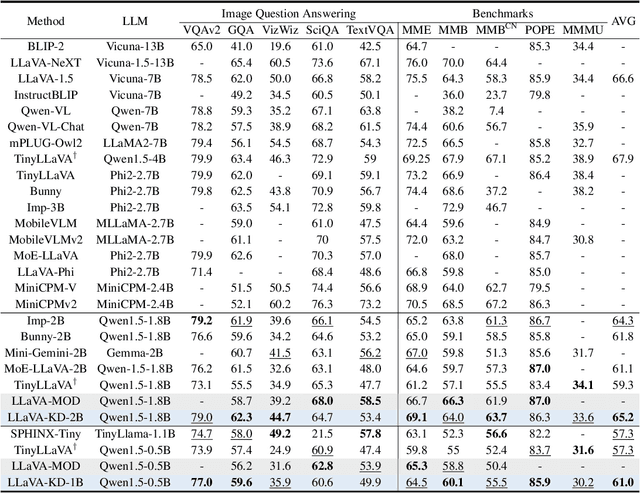
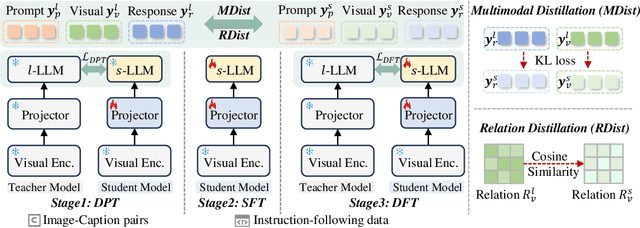
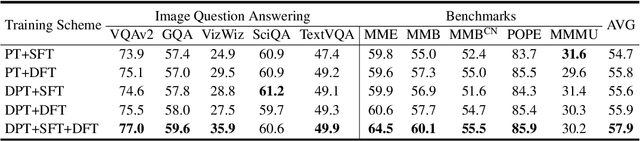
The success of Large Language Models (LLM) has led researchers to explore Multimodal Large Language Models (MLLM) for unified visual and linguistic understanding. However, the increasing model size and computational complexity of MLLM limit their use in resource-constrained environments. Small-scale MLLM (s-MLLM) aims to retain the capabilities of the large-scale model (l-MLLM) while reducing computational demands, but resulting in a significant decline in performance. To address the aforementioned issues, we propose a novel LLaVA-KD framework to transfer knowledge from l-MLLM to s-MLLM. Specifically, we introduce Multimodal Distillation (MDist) to minimize the divergence between the visual-textual output distributions of l-MLLM and s-MLLM, and Relation Distillation (RDist) to transfer l-MLLM's ability to model correlations between visual features. Additionally, we propose a three-stage training scheme to fully exploit the potential of s-MLLM: 1) Distilled Pre-Training to align visual-textual representations, 2) Supervised Fine-Tuning to equip the model with multimodal understanding, and 3) Distilled Fine-Tuning to further transfer l-MLLM capabilities. Our approach significantly improves performance without altering the small model's architecture. Extensive experiments and ablation studies validate the effectiveness of each proposed component. Code will be available at https://github.com/caiyuxuan1120/LLaVA-KD.
Anomaly Detection by Adapting a pre-trained Vision Language Model
Mar 14, 2024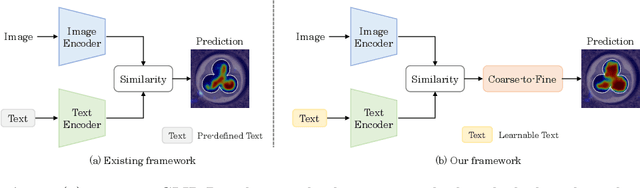

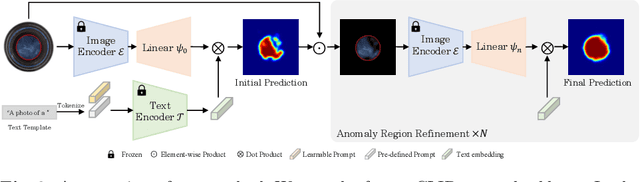

Recently, large vision and language models have shown their success when adapting them to many downstream tasks. In this paper, we present a unified framework named CLIP-ADA for Anomaly Detection by Adapting a pre-trained CLIP model. To this end, we make two important improvements: 1) To acquire unified anomaly detection across industrial images of multiple categories, we introduce the learnable prompt and propose to associate it with abnormal patterns through self-supervised learning. 2) To fully exploit the representation power of CLIP, we introduce an anomaly region refinement strategy to refine the localization quality. During testing, the anomalies are localized by directly calculating the similarity between the representation of the learnable prompt and the image. Comprehensive experiments demonstrate the superiority of our framework, e.g., we achieve the state-of-the-art 97.5/55.6 and 89.3/33.1 on MVTec-AD and VisA for anomaly detection and localization. In addition, the proposed method also achieves encouraging performance with marginal training data, which is more challenging.