 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRTSearch: Unified Detection and Parameter Inference of Fast Radio Transients using Instance Segmentation
Apr 14, 2026The exponential growth of data from modern radio telescopes presents a significant challenge to traditional single-pulse search algorithms, which are computationally intensive and prone to high false-positive rates due to Radio Frequency Interference (RFI). In this work, we introduce FRTSearch, an end-to-end framework unifying the detection and physical characterization of Fast Radio Transients (FRTs). Leveraging the morphological universality of dispersive trajectories in time-frequency dynamic spectra, we reframe FRT detection as a pattern recognition problem governed by the cold plasma dispersion relation. To facilitate this, we constructed CRAFTS-FRT, a pixel-level annotated dataset derived from the Commensal Radio Astronomy FAST Survey (CRAFTS), comprising 2{,}392 instances across diverse source classes. This dataset enables the training of a Mask R-CNN model for precise trajectory segmentation. Coupled with our physics-driven IMPIC algorithm, the framework maps the geometric coordinates of segmented trajectories to directly infer the Dispersion Measure (DM) and Time of Arrival (ToA). Benchmarking on the FAST-FREX dataset shows that FRTSearch achieves a 98.0\% recall, competitive with exhaustive search methods, while reducing false positives by over 99.9\% compared to PRESTO and delivering a processing speedup of up to $13.9\times$. Furthermore, the framework demonstrates robust cross-facility generalization, detecting all 19 tested FRBs from the ASKAP survey without retraining. By shifting the paradigm from ``search-then-identify'' to ``detect-and-infer,'' FRTSearch provides a scalable, high-precision solution for real-time discovery in the era of petabyte-scale radio astronomy.
Improving Search Agent with One Line of Code
Mar 10, 2026Tool-based Agentic Reinforcement Learning (TARL) has emerged as a promising paradigm for training search agents to interact with external tools for a multi-turn information-seeking process autonomously. However, we identify a critical training instability that leads to catastrophic model collapse: Importance Sampling Distribution Drift(ISDD). In Group Relative Policy Optimization(GRPO), a widely adopted TARL algorithm, ISDD manifests as a precipitous decline in the importance sampling ratios, which nullifies gradient updates and triggers irreversible training failure. To address this, we propose \textbf{S}earch \textbf{A}gent \textbf{P}olicy \textbf{O}ptimization (\textbf{SAPO}), which stabilizes training via a conditional token-level KL constraint. Unlike hard clipping, which ignores distributional divergence, SAPO selectively penalizes the KL divergence between the current and old policies. Crucially, this penalty is applied only to positive tokens with low probabilities where the policy has shifted excessively, thereby preventing distribution drift while preserving gradient flow. Remarkably, SAPO requires only one-line code modification to standard GRPO, ensuring immediate deployability. Extensive experiments across seven QA benchmarks demonstrate that SAPO achieves \textbf{+10.6\% absolute improvement} (+31.5\% relative) over Search-R1, yielding consistent gains across varying model scales (1.5B, 14B) and families (Qwen, LLaMA).
SwiftVideo: A Unified Framework for Few-Step Video Generation through Trajectory-Distribution Alignment
Aug 08, 2025Diffusion-based or flow-based models have achieved significant progress in video synthesis but require multiple iterative sampling steps, which incurs substantial computational overhead. While many distillation methods that are solely based on trajectory-preserving or distribution-matching have been developed to accelerate video generation models, these approaches often suffer from performance breakdown or increased artifacts under few-step settings. To address these limitations, we propose \textbf{\emph{SwiftVideo}}, a unified and stable distillation framework that combines the advantages of trajectory-preserving and distribution-matching strategies. Our approach introduces continuous-time consistency distillation to ensure precise preservation of ODE trajectories. Subsequently, we propose a dual-perspective alignment that includes distribution alignment between synthetic and real data along with trajectory alignment across different inference steps. Our method maintains high-quality video generation while substantially reducing the number of inference steps. Quantitative evaluations on the OpenVid-1M benchmark demonstrate that our method significantly outperforms existing approaches in few-step video generation.
Swin DiT: Diffusion Transformer using Pseudo Shifted Windows
May 19, 2025Diffusion Transformers (DiTs) achieve remarkable performance within the domain of image generation through the incorporation of the transformer architecture. Conventionally, DiTs are constructed by stacking serial isotropic global information modeling transformers, which face significant computational cost when processing high-resolution images. We empirically analyze that latent space image generation does not exhibit a strong dependence on global information as traditionally assumed. Most of the layers in the model demonstrate redundancy in global computation. In addition, conventional attention mechanisms exhibit low-frequency inertia issues. To address these issues, we propose \textbf{P}seudo \textbf{S}hifted \textbf{W}indow \textbf{A}ttention (PSWA), which fundamentally mitigates global model redundancy. PSWA achieves intermediate global-local information interaction through window attention, while employing a high-frequency bridging branch to simulate shifted window operations, supplementing appropriate global and high-frequency information. Furthermore, we propose the Progressive Coverage Channel Allocation(PCCA) strategy that captures high-order attention similarity without additional computational cost. Building upon all of them, we propose a series of Pseudo \textbf{S}hifted \textbf{Win}dow DiTs (\textbf{Swin DiT}), accompanied by extensive experiments demonstrating their superior performance. For example, our proposed Swin-DiT-L achieves a 54%$\uparrow$ FID improvement over DiT-XL/2 while requiring less computational. https://github.com/wujiafu007/Swin-DiT
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025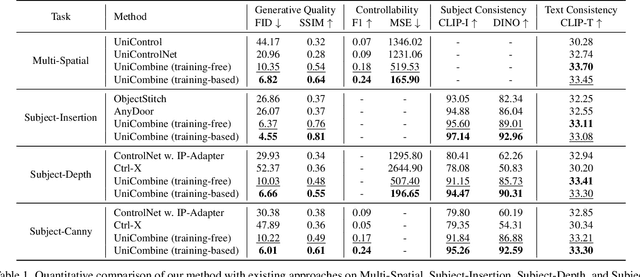
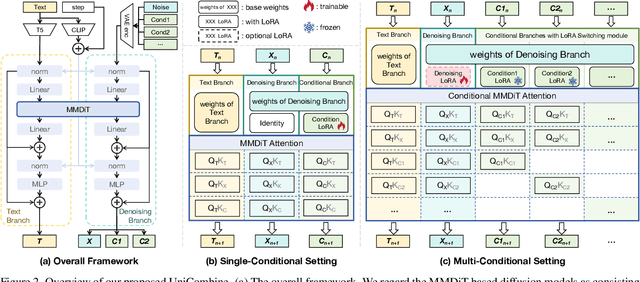
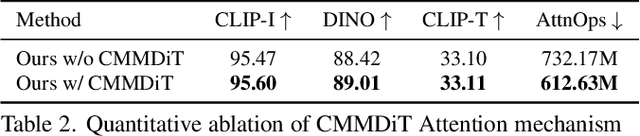
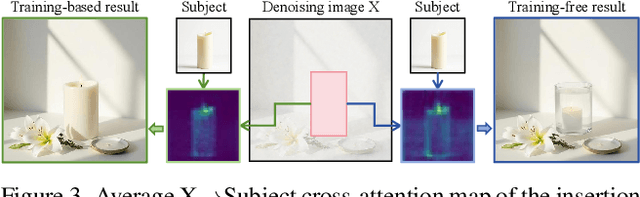
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
VI3DRM:Towards meticulous 3D Reconstruction from Sparse Views via Photo-Realistic Novel View Synthesis
Sep 12, 2024



Recently, methods like Zero-1-2-3 have focused on single-view based 3D reconstruction and have achieved remarkable success. However, their predictions for unseen areas heavily rely on the inductive bias of large-scale pretrained diffusion models. Although subsequent work, such as DreamComposer, attempts to make predictions more controllable by incorporating additional views, the results remain unrealistic due to feature entanglement in the vanilla latent space, including factors such as lighting, material, and structure. To address these issues, we introduce the Visual Isotropy 3D Reconstruction Model (VI3DRM), a diffusion-based sparse views 3D reconstruction model that operates within an ID consistent and perspective-disentangled 3D latent space. By facilitating the disentanglement of semantic information, color, material properties and lighting, VI3DRM is capable of generating highly realistic images that are indistinguishable from real photographs. By leveraging both real and synthesized images, our approach enables the accurate construction of pointmaps, ultimately producing finely textured meshes or point clouds. On the NVS task, tested on the GSO dataset, VI3DRM significantly outperforms state-of-the-art method DreamComposer, achieving a PSNR of 38.61, an SSIM of 0.929, and an LPIPS of 0.027. Code will be made available upon publication.
Temporal and Interactive Modeling for Efficient Human-Human Motion Generation
Aug 30, 2024



Human-human motion generation is essential for understanding humans as social beings. Although several transformer-based methods have been proposed, they typically model each individual separately and overlook the causal relationships in temporal motion sequences. Furthermore, the attention mechanism in transformers exhibits quadratic computational complexity, significantly reducing their efficiency when processing long sequences. In this paper, we introduce TIM (Temporal and Interactive Modeling), an efficient and effective approach that presents the pioneering human-human motion generation model utilizing RWKV. Specifically, we first propose Causal Interactive Injection to leverage the temporal properties of motion sequences and avoid non-causal and cumbersome modeling. Then we present Role-Evolving Mixing to adjust to the ever-evolving roles throughout the interaction. Finally, to generate smoother and more rational motion, we design Localized Pattern Amplification to capture short-term motion patterns. Extensive experiments on InterHuman demonstrate that our method achieves superior performance. Notably, TIM has achieved state-of-the-art results using only 32% of InterGen's trainable parameters. Code will be available soon. Homepage: https://aigc-explorer.github.io/TIM-page/
DualAnoDiff: Dual-Interrelated Diffusion Model for Few-Shot Anomaly Image Generation
Aug 24, 2024



The performance of anomaly inspection in industrial manufacturing is constrained by the scarcity of anomaly data. To overcome this challenge, researchers have started employing anomaly generation approaches to augment the anomaly dataset. However, existing anomaly generation methods suffer from limited diversity in the generated anomalies and struggle to achieve a seamless blending of this anomaly with the original image. In this paper, we overcome these challenges from a new perspective, simultaneously generating a pair of the overall image and the corresponding anomaly part. We propose DualAnoDiff, a novel diffusion-based few-shot anomaly image generation model, which can generate diverse and realistic anomaly images by using a dual-interrelated diffusion model, where one of them is employed to generate the whole image while the other one generates the anomaly part. Moreover, we extract background and shape information to mitigate the distortion and blurriness phenomenon in few-shot image generation. Extensive experiments demonstrate the superiority of our proposed model over state-of-the-art methods in terms of both realism and diversity. Overall, our approach significantly improves the performance of downstream anomaly detection tasks, including anomaly detection, anomaly localization, and anomaly classification tasks.
MDT-A2G: Exploring Masked Diffusion Transformers for Co-Speech Gesture Generation
Aug 06, 2024



Recent advancements in the field of Diffusion Transformers have substantially improved the generation of high-quality 2D images, 3D videos, and 3D shapes. However, the effectiveness of the Transformer architecture in the domain of co-speech gesture generation remains relatively unexplored, as prior methodologies have predominantly employed the Convolutional Neural Network (CNNs) or simple a few transformer layers. In an attempt to bridge this research gap, we introduce a novel Masked Diffusion Transformer for co-speech gesture generation, referred to as MDT-A2G, which directly implements the denoising process on gesture sequences. To enhance the contextual reasoning capability of temporally aligned speech-driven gestures, we incorporate a novel Masked Diffusion Transformer. This model employs a mask modeling scheme specifically designed to strengthen temporal relation learning among sequence gestures, thereby expediting the learning process and leading to coherent and realistic motions. Apart from audio, Our MDT-A2G model also integrates multi-modal information, encompassing text, emotion, and identity. Furthermore, we propose an efficient inference strategy that diminishes the denoising computation by leveraging previously calculated results, thereby achieving a speedup with negligible performance degradation. Experimental results demonstrate that MDT-A2G excels in gesture generation, boasting a learning speed that is over 6$\times$ faster than traditional diffusion transformers and an inference speed that is 5.7$\times$ than the standard diffusion model.
AdapNet: Adaptive Noise-Based Network for Low-Quality Image Retrieval
May 28, 2024

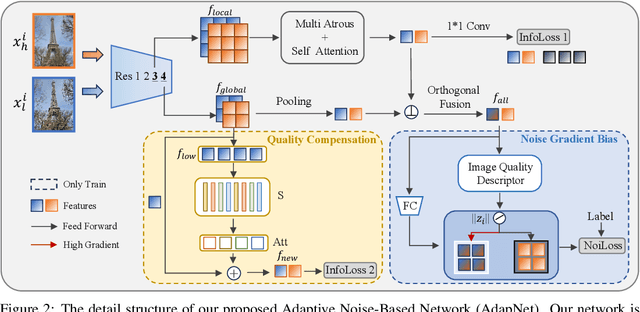

Image retrieval aims to identify visually similar images within a database using a given query image. Traditional methods typically employ both global and local features extracted from images for matching, and may also apply re-ranking techniques to enhance accuracy. However, these methods often fail to account for the noise present in query images, which can stem from natural or human-induced factors, thereby negatively impacting retrieval performance. To mitigate this issue, we introduce a novel setting for low-quality image retrieval, and propose an Adaptive Noise-Based Network (AdapNet) to learn robust abstract representations. Specifically, we devise a quality compensation block trained to compensate for various low-quality factors in input images. Besides, we introduce an innovative adaptive noise-based loss function, which dynamically adjusts its focus on the gradient in accordance with image quality, thereby augmenting the learning of unknown noisy samples during training and enhancing intra-class compactness. To assess the performance, we construct two datasets with low-quality queries, which is built by applying various types of noise on clean query images on the standard Revisited Oxford and Revisited Paris datasets. Comprehensive experimental results illustrate that AdapNet surpasses state-of-the-art methods on the Noise Revisited Oxford and Noise Revisited Paris benchmarks, while maintaining competitive performance on high-quality datasets. The code and constructed datasets will be made available.