 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePro-AD: Learning Comprehensive Prototypes with Prototype-based Constraint for Multi-class Unsupervised Anomaly Detection
Jun 16, 2025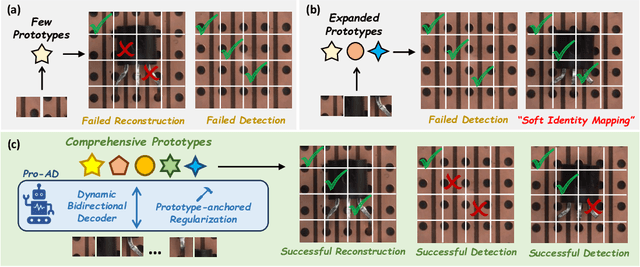



Prototype-based reconstruction methods for unsupervised anomaly detection utilize a limited set of learnable prototypes which only aggregates insufficient normal information, resulting in undesirable reconstruction. However, increasing the number of prototypes may lead to anomalies being well reconstructed through the attention mechanism, which we refer to as the "Soft Identity Mapping" problem. In this paper, we propose Pro-AD to address these issues and fully utilize the prototypes to boost the performance of anomaly detection. Specifically, we first introduce an expanded set of learnable prototypes to provide sufficient capacity for semantic information. Then we employ a Dynamic Bidirectional Decoder which integrates the process of the normal information aggregation and the target feature reconstruction via prototypes, with the aim of allowing the prototypes to aggregate more comprehensive normal semantic information from different levels of the image features and the target feature reconstruction to not only utilize its contextual information but also dynamically leverage the learned comprehensive prototypes. Additionally, to prevent the anomalies from being well reconstructed using sufficient semantic information through the attention mechanism, Pro-AD introduces a Prototype-based Constraint that applied within the target feature reconstruction process of the decoder, which further improves the performance of our approach. Extensive experiments on multiple challenging benchmarks demonstrate that our Pro-AD achieve state-of-the-art performance, highlighting its superior robustness and practical effectiveness for Multi-class Unsupervised Anomaly Detection task.
Real-IAD D3: A Real-World 2D/Pseudo-3D/3D Dataset for Industrial Anomaly Detection
Apr 19, 2025The increasing complexity of industrial anomaly detection (IAD) has positioned multimodal detection methods as a focal area of machine vision research. However, dedicated multimodal datasets specifically tailored for IAD remain limited. Pioneering datasets like MVTec 3D have laid essential groundwork in multimodal IAD by incorporating RGB+3D data, but still face challenges in bridging the gap with real industrial environments due to limitations in scale and resolution. To address these challenges, we introduce Real-IAD D3, a high-precision multimodal dataset that uniquely incorporates an additional pseudo3D modality generated through photometric stereo, alongside high-resolution RGB images and micrometer-level 3D point clouds. Real-IAD D3 features finer defects, diverse anomalies, and greater scale across 20 categories, providing a challenging benchmark for multimodal IAD Additionally, we introduce an effective approach that integrates RGB, point cloud, and pseudo-3D depth information to leverage the complementary strengths of each modality, enhancing detection performance. Our experiments highlight the importance of these modalities in boosting detection robustness and overall IAD performance. The dataset and code are publicly accessible for research purposes at https://realiad4ad.github.io/Real-IAD D3
PA-CLIP: Enhancing Zero-Shot Anomaly Detection through Pseudo-Anomaly Awareness
Mar 03, 2025In industrial anomaly detection (IAD), accurately identifying defects amidst diverse anomalies and under varying imaging conditions remains a significant challenge. Traditional approaches often struggle with high false-positive rates, frequently misclassifying normal shadows and surface deformations as defects, an issue that becomes particularly pronounced in products with complex and intricate surface features. To address these challenges, we introduce PA-CLIP, a zero-shot anomaly detection method that reduces background noise and enhances defect detection through a pseudo-anomaly-based framework. The proposed method integrates a multiscale feature aggregation strategy for capturing detailed global and local information, two memory banks for distinguishing background information, including normal patterns and pseudo-anomalies, from true anomaly features, and a decision-making module designed to minimize false positives caused by environmental variations while maintaining high defect sensitivity. Demonstrated on the MVTec AD and VisA datasets, PA-CLIP outperforms existing zero-shot methods, providing a robust solution for industrial defect detection.
OSV: One Step is Enough for High-Quality Image to Video Generation
Sep 17, 2024



Video diffusion models have shown great potential in generating high-quality videos, making them an increasingly popular focus. However, their inherent iterative nature leads to substantial computational and time costs. While efforts have been made to accelerate video diffusion by reducing inference steps (through techniques like consistency distillation) and GAN training (these approaches often fall short in either performance or training stability). In this work, we introduce a two-stage training framework that effectively combines consistency distillation with GAN training to address these challenges. Additionally, we propose a novel video discriminator design, which eliminates the need for decoding the video latents and improves the final performance. Our model is capable of producing high-quality videos in merely one-step, with the flexibility to perform multi-step refinement for further performance enhancement. Our quantitative evaluation on the OpenWebVid-1M benchmark shows that our model significantly outperforms existing methods. Notably, our 1-step performance(FVD 171.15) exceeds the 8-step performance of the consistency distillation based method, AnimateLCM (FVD 184.79), and approaches the 25-step performance of advanced Stable Video Diffusion (FVD 156.94).
DualAnoDiff: Dual-Interrelated Diffusion Model for Few-Shot Anomaly Image Generation
Aug 24, 2024



The performance of anomaly inspection in industrial manufacturing is constrained by the scarcity of anomaly data. To overcome this challenge, researchers have started employing anomaly generation approaches to augment the anomaly dataset. However, existing anomaly generation methods suffer from limited diversity in the generated anomalies and struggle to achieve a seamless blending of this anomaly with the original image. In this paper, we overcome these challenges from a new perspective, simultaneously generating a pair of the overall image and the corresponding anomaly part. We propose DualAnoDiff, a novel diffusion-based few-shot anomaly image generation model, which can generate diverse and realistic anomaly images by using a dual-interrelated diffusion model, where one of them is employed to generate the whole image while the other one generates the anomaly part. Moreover, we extract background and shape information to mitigate the distortion and blurriness phenomenon in few-shot image generation. Extensive experiments demonstrate the superiority of our proposed model over state-of-the-art methods in terms of both realism and diversity. Overall, our approach significantly improves the performance of downstream anomaly detection tasks, including anomaly detection, anomaly localization, and anomaly classification tasks.
PSPU: Enhanced Positive and Unlabeled Learning by Leveraging Pseudo Supervision
Jul 09, 2024



Positive and Unlabeled (PU) learning, a binary classification model trained with only positive and unlabeled data, generally suffers from overfitted risk estimation due to inconsistent data distributions. To address this, we introduce a pseudo-supervised PU learning framework (PSPU), in which we train the PU model first, use it to gather confident samples for the pseudo supervision, and then apply these supervision to correct the PU model's weights by leveraging non-PU objectives. We also incorporate an additional consistency loss to mitigate noisy sample effects. Our PSPU outperforms recent PU learning methods significantly on MNIST, CIFAR-10, CIFAR-100 in both balanced and imbalanced settings, and enjoys competitive performance on MVTecAD for industrial anomaly detection.
Single-temporal Supervised Remote Change Detection for Domain Generalization
Apr 19, 2024

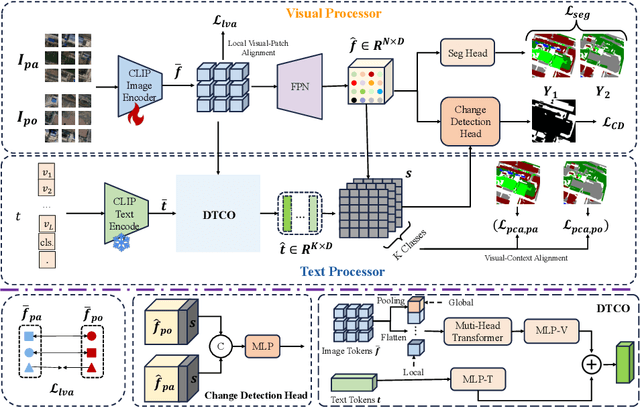

Change detection is widely applied in remote sensing image analysis. Existing methods require training models separately for each dataset, which leads to poor domain generalization. Moreover, these methods rely heavily on large amounts of high-quality pair-labelled data for training, which is expensive and impractical. In this paper, we propose a multimodal contrastive learning (ChangeCLIP) based on visual-language pre-training for change detection domain generalization. Additionally, we propose a dynamic context optimization for prompt learning. Meanwhile, to address the data dependency issue of existing methods, we introduce a single-temporal and controllable AI-generated training strategy (SAIN). This allows us to train the model using a large number of single-temporal images without image pairs in the real world, achieving excellent generalization. Extensive experiments on series of real change detection datasets validate the superiority and strong generalization of ChangeCLIP, outperforming state-of-the-art change detection methods. Code will be available.
Leveraging Fine-Grained Information and Noise Decoupling for Remote Sensing Change Detection
Apr 17, 2024Change detection aims to identify remote sense object changes by analyzing data between bitemporal image pairs. Due to the large temporal and spatial span of data collection in change detection image pairs, there are often a significant amount of task-specific and task-agnostic noise. Previous effort has focused excessively on denoising, with this goes a great deal of loss of fine-grained information. In this paper, we revisit the importance of fine-grained features in change detection and propose a series of operations for fine-grained information compensation and noise decoupling (FINO). First, the context is utilized to compensate for the fine-grained information in the feature space. Next, a shape-aware and a brightness-aware module are designed to improve the capacity for representation learning. The shape-aware module guides the backbone for more precise shape estimation, guiding the backbone network in extracting object shape features. The brightness-aware module learns a overall brightness estimation to improve the model's robustness to task-agnostic noise. Finally, a task-specific noise decoupling structure is designed as a way to improve the model's ability to separate noise interference from feature similarity. With these training schemes, our proposed method achieves new state-of-the-art (SOTA) results in multiple change detection benchmarks. The code will be made available.
Real-IAD: A Real-World Multi-View Dataset for Benchmarking Versatile Industrial Anomaly Detection
Mar 19, 2024Industrial anomaly detection (IAD) has garnered significant attention and experienced rapid development. However, the recent development of IAD approach has encountered certain difficulties due to dataset limitations. On the one hand, most of the state-of-the-art methods have achieved saturation (over 99% in AUROC) on mainstream datasets such as MVTec, and the differences of methods cannot be well distinguished, leading to a significant gap between public datasets and actual application scenarios. On the other hand, the research on various new practical anomaly detection settings is limited by the scale of the dataset, posing a risk of overfitting in evaluation results. Therefore, we propose a large-scale, Real-world, and multi-view Industrial Anomaly Detection dataset, named Real-IAD, which contains 150K high-resolution images of 30 different objects, an order of magnitude larger than existing datasets. It has a larger range of defect area and ratio proportions, making it more challenging than previous datasets. To make the dataset closer to real application scenarios, we adopted a multi-view shooting method and proposed sample-level evaluation metrics. In addition, beyond the general unsupervised anomaly detection setting, we propose a new setting for Fully Unsupervised Industrial Anomaly Detection (FUIAD) based on the observation that the yield rate in industrial production is usually greater than 60%, which has more practical application value. Finally, we report the results of popular IAD methods on the Real-IAD dataset, providing a highly challenging benchmark to promote the development of the IAD field.
Learning Unified Reference Representation for Unsupervised Multi-class Anomaly Detection
Mar 18, 2024In the field of multi-class anomaly detection, reconstruction-based methods derived from single-class anomaly detection face the well-known challenge of ``learning shortcuts'', wherein the model fails to learn the patterns of normal samples as it should, opting instead for shortcuts such as identity mapping or artificial noise elimination. Consequently, the model becomes unable to reconstruct genuine anomalies as normal instances, resulting in a failure of anomaly detection. To counter this issue, we present a novel unified feature reconstruction-based anomaly detection framework termed RLR (Reconstruct features from a Learnable Reference representation). Unlike previous methods, RLR utilizes learnable reference representations to compel the model to learn normal feature patterns explicitly, thereby prevents the model from succumbing to the ``learning shortcuts'' issue. Additionally, RLR incorporates locality constraints into the learnable reference to facilitate more effective normal pattern capture and utilizes a masked learnable key attention mechanism to enhance robustness. Evaluation of RLR on the 15-category MVTec-AD dataset and the 12-category VisA dataset shows superior performance compared to state-of-the-art methods under the unified setting. The code of RLR will be publicly available.