 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Fine-Grained Information and Noise Decoupling for Remote Sensing Change Detection
Apr 17, 2024Change detection aims to identify remote sense object changes by analyzing data between bitemporal image pairs. Due to the large temporal and spatial span of data collection in change detection image pairs, there are often a significant amount of task-specific and task-agnostic noise. Previous effort has focused excessively on denoising, with this goes a great deal of loss of fine-grained information. In this paper, we revisit the importance of fine-grained features in change detection and propose a series of operations for fine-grained information compensation and noise decoupling (FINO). First, the context is utilized to compensate for the fine-grained information in the feature space. Next, a shape-aware and a brightness-aware module are designed to improve the capacity for representation learning. The shape-aware module guides the backbone for more precise shape estimation, guiding the backbone network in extracting object shape features. The brightness-aware module learns a overall brightness estimation to improve the model's robustness to task-agnostic noise. Finally, a task-specific noise decoupling structure is designed as a way to improve the model's ability to separate noise interference from feature similarity. With these training schemes, our proposed method achieves new state-of-the-art (SOTA) results in multiple change detection benchmarks. The code will be made available.
RFENet: Towards Reciprocal Feature Evolution for Glass Segmentation
Jul 12, 2023Glass-like objects are widespread in daily life but remain intractable to be segmented for most existing methods. The transparent property makes it difficult to be distinguished from background, while the tiny separation boundary further impedes the acquisition of their exact contour. In this paper, by revealing the key co-evolution demand of semantic and boundary learning, we propose a Selective Mutual Evolution (SME) module to enable the reciprocal feature learning between them. Then to exploit the global shape context, we propose a Structurally Attentive Refinement (SAR) module to conduct a fine-grained feature refinement for those ambiguous points around the boundary. Finally, to further utilize the multi-scale representation, we integrate the above two modules into a cascaded structure and then introduce a Reciprocal Feature Evolution Network (RFENet) for effective glass-like object segmentation. Extensive experiments demonstrate that our RFENet achieves state-of-the-art performance on three popular public datasets.
HDNet: A Hierarchically Decoupled Network for Crowd Counting
Dec 12, 2022Recently, density map regression-based methods have dominated in crowd counting owing to their excellent fitting ability on density distribution. However, further improvement tends to saturate mainly because of the confusing background noise and the large density variation. In this paper, we propose a Hierarchically Decoupled Network (HDNet) to solve the above two problems within a unified framework. Specifically, a background classification sub-task is decomposed from the density map prediction task, which is then assigned to a Density Decoupling Module (DDM) to exploit its highly discriminative ability. For the remaining foreground prediction sub-task, it is further hierarchically decomposed to several density-specific sub-tasks by the DDM, which are then solved by the regression-based experts in a Foreground Density Estimation Module (FDEM). Although the proposed strategy effectively reduces the hypothesis space so as to relieve the optimization for those task-specific experts, the high correlation of these sub-tasks are ignored. Therefore, we introduce three types of interaction strategies to unify the whole framework, which are Feature Interaction, Gradient Interaction, and Scale Interaction. Integrated with the above spirits, HDNet achieves state-of-the-art performance on several popular counting benchmarks.
LCTR: On Awakening the Local Continuity of Transformer for Weakly Supervised Object Localization
Dec 10, 2021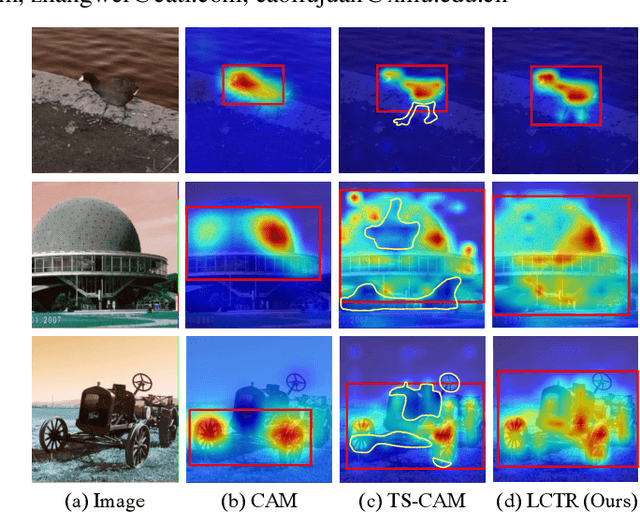
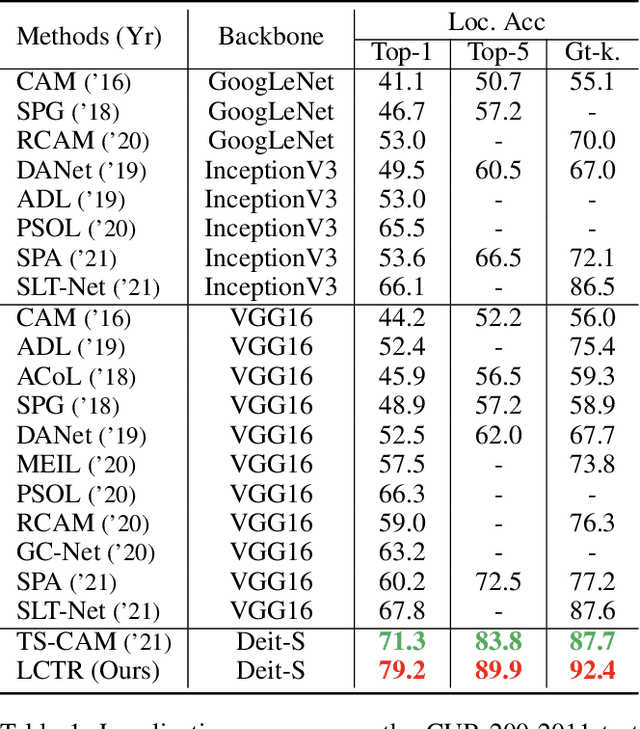
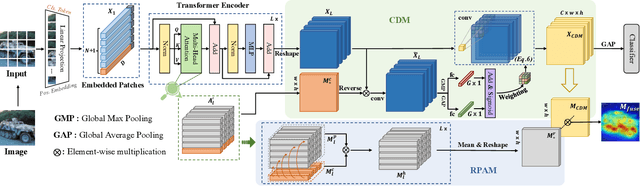
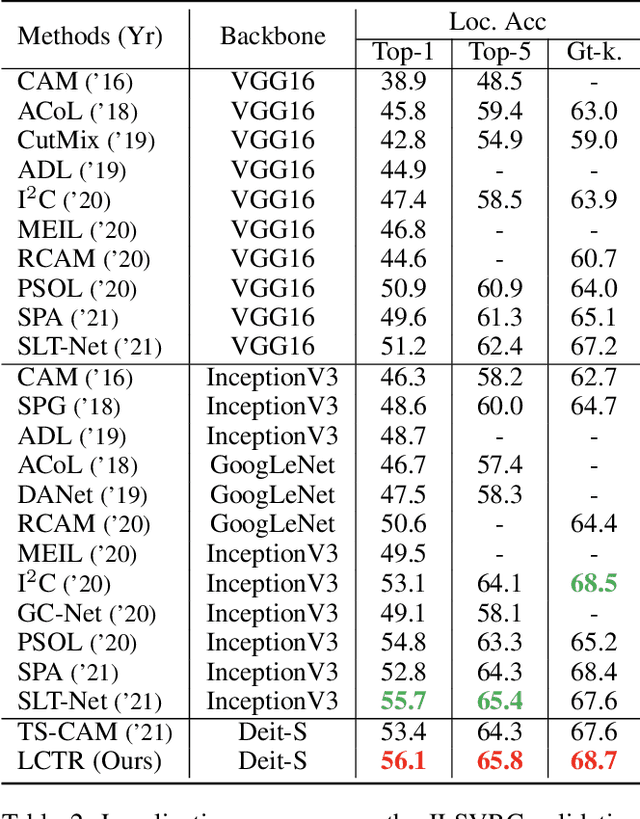
Weakly supervised object localization (WSOL) aims to learn object localizer solely by using image-level labels. The convolution neural network (CNN) based techniques often result in highlighting the most discriminative part of objects while ignoring the entire object extent. Recently, the transformer architecture has been deployed to WSOL to capture the long-range feature dependencies with self-attention mechanism and multilayer perceptron structure. Nevertheless, transformers lack the locality inductive bias inherent to CNNs and therefore may deteriorate local feature details in WSOL. In this paper, we propose a novel framework built upon the transformer, termed LCTR (Local Continuity TRansformer), which targets at enhancing the local perception capability of global features among long-range feature dependencies. To this end, we propose a relational patch-attention module (RPAM), which considers cross-patch information on a global basis. We further design a cue digging module (CDM), which utilizes local features to guide the learning trend of the model for highlighting the weak local responses. Finally, comprehensive experiments are carried out on two widely used datasets, ie, CUB-200-2011 and ILSVRC, to verify the effectiveness of our method.
Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework
Aug 07, 2021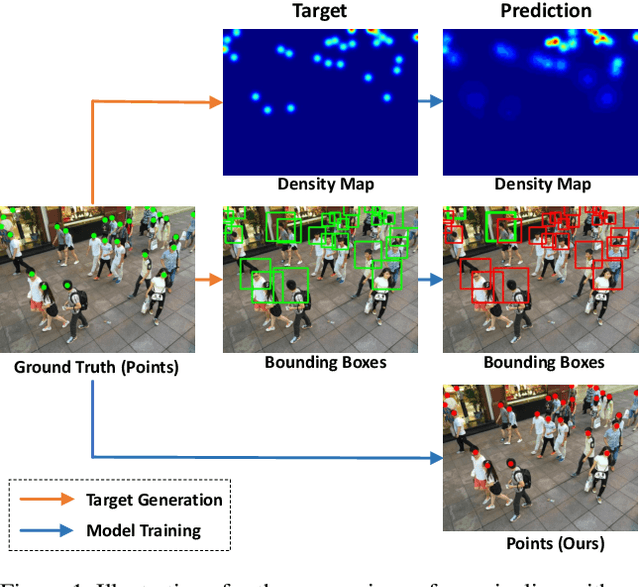
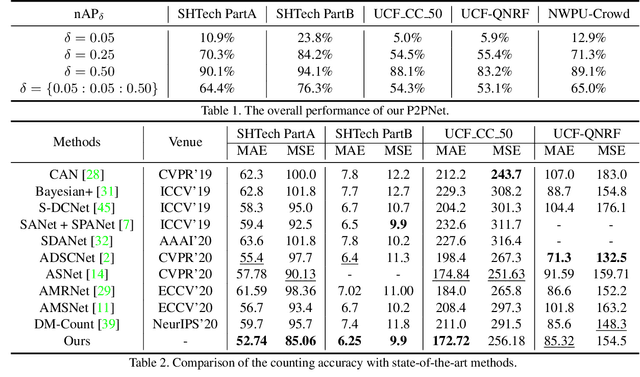
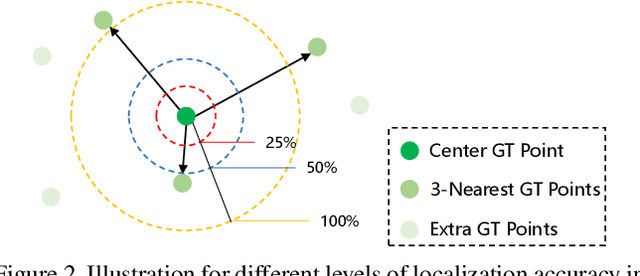
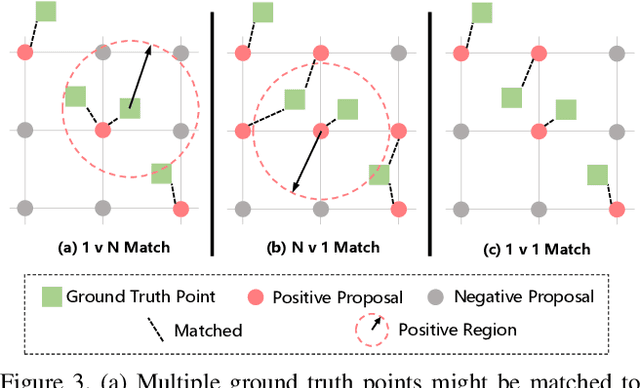
Localizing individuals in crowds is more in accordance with the practical demands of subsequent high-level crowd analysis tasks than simply counting. However, existing localization based methods relying on intermediate representations (\textit{i.e.}, density maps or pseudo boxes) serving as learning targets are counter-intuitive and error-prone. In this paper, we propose a purely point-based framework for joint crowd counting and individual localization. For this framework, instead of merely reporting the absolute counting error at image level, we propose a new metric, called density Normalized Average Precision (nAP), to provide more comprehensive and more precise performance evaluation. Moreover, we design an intuitive solution under this framework, which is called Point to Point Network (P2PNet). P2PNet discards superfluous steps and directly predicts a set of point proposals to represent heads in an image, being consistent with the human annotation results. By thorough analysis, we reveal the key step towards implementing such a novel idea is to assign optimal learning targets for these proposals. Therefore, we propose to conduct this crucial association in an one-to-one matching manner using the Hungarian algorithm. The P2PNet not only significantly surpasses state-of-the-art methods on popular counting benchmarks, but also achieves promising localization accuracy. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet.
Uniformity in Heterogeneity:Diving Deep into Count Interval Partition for Crowd Counting
Aug 07, 2021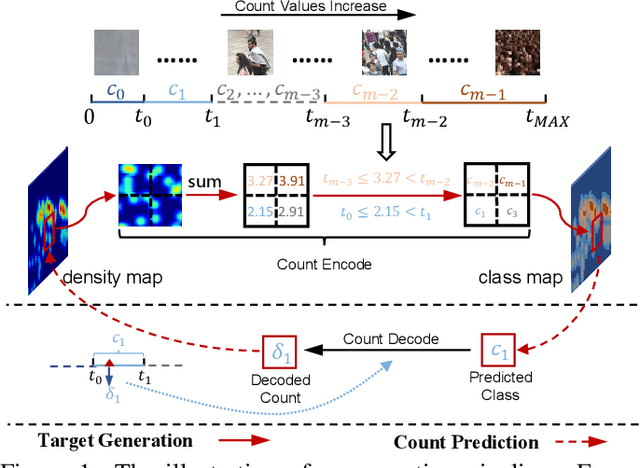
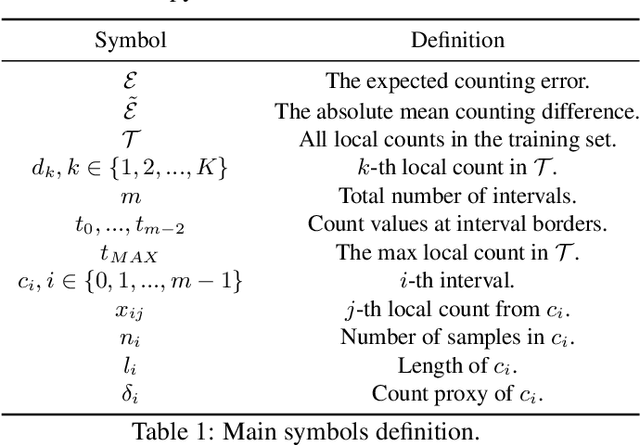
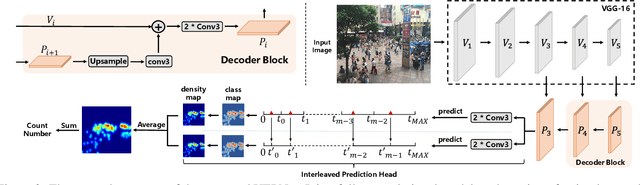
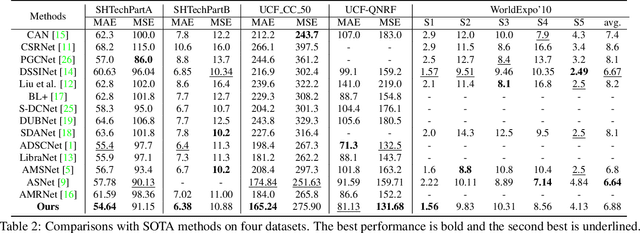
Recently, the problem of inaccurate learning targets in crowd counting draws increasing attention. Inspired by a few pioneering work, we solve this problem by trying to predict the indices of pre-defined interval bins of counts instead of the count values themselves. However, an inappropriate interval setting might make the count error contributions from different intervals extremely imbalanced, leading to inferior counting performance. Therefore, we propose a novel count interval partition criterion called Uniform Error Partition (UEP), which always keeps the expected counting error contributions equal for all intervals to minimize the prediction risk. Then to mitigate the inevitably introduced discretization errors in the count quantization process, we propose another criterion called Mean Count Proxies (MCP). The MCP criterion selects the best count proxy for each interval to represent its count value during inference, making the overall expected discretization error of an image nearly negligible. As far as we are aware, this work is the first to delve into such a classification task and ends up with a promising solution for count interval partition. Following the above two theoretically demonstrated criterions, we propose a simple yet effective model termed Uniform Error Partition Network (UEPNet), which achieves state-of-the-art performance on several challenging datasets. The codes will be available at: https://github.com/TencentYoutuResearch/CrowdCounting-UEPNet.
Chained-Tracker: Chaining Paired Attentive Regression Results for End-to-End Joint Multiple-Object Detection and Tracking
Jul 29, 2020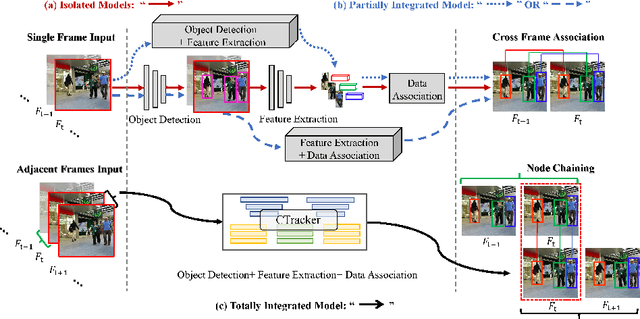

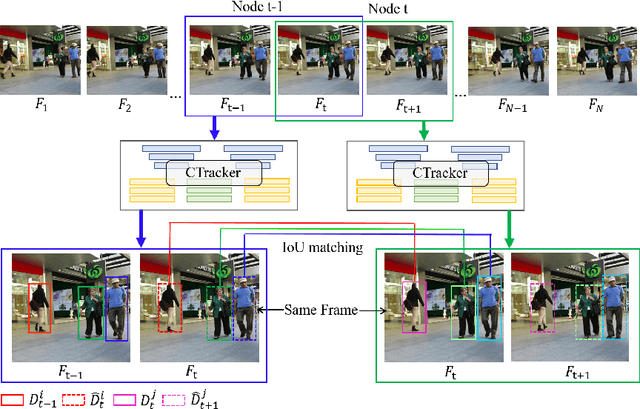
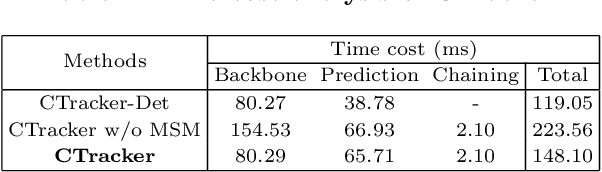
Existing Multiple-Object Tracking (MOT) methods either follow the tracking-by-detection paradigm to conduct object detection, feature extraction and data association separately, or have two of the three subtasks integrated to form a partially end-to-end solution. Going beyond these sub-optimal frameworks, we propose a simple online model named Chained-Tracker (CTracker), which naturally integrates all the three subtasks into an end-to-end solution (the first as far as we know). It chains paired bounding boxes regression results estimated from overlapping nodes, of which each node covers two adjacent frames. The paired regression is made attentive by object-attention (brought by a detection module) and identity-attention (ensured by an ID verification module). The two major novelties: chained structure and paired attentive regression, make CTracker simple, fast and effective, setting new MOTA records on MOT16 and MOT17 challenge datasets (67.6 and 66.6, respectively), without relying on any extra training data. The source code of CTracker can be found at: github.com/pjl1995/CTracker.
DSFD: Dual Shot Face Detector
Oct 24, 2018
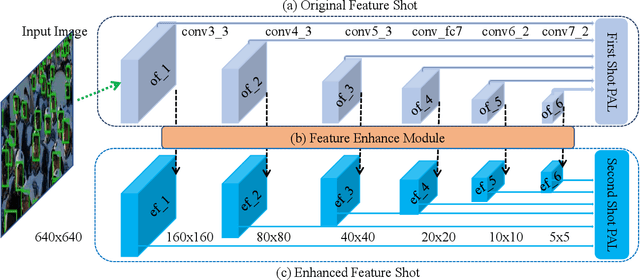

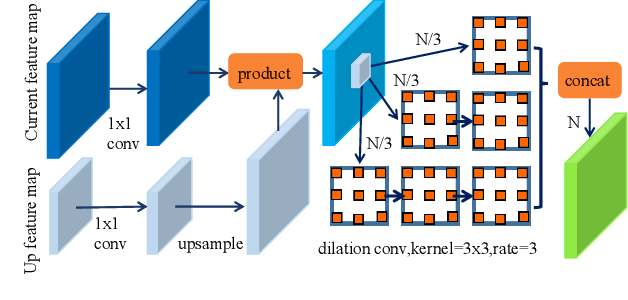
Recently, Convolutional Neural Network (CNN) has achieved great success in face detection. However, it remains a challenging problem for the current face detection methods owing to high degree of variability in scale, pose, occlusion, expression, appearance and illumination. In this paper, we propose a novel face detection network named Dual Shot face Detector(DSFD), which inherits the architecture of SSD and introduces a Feature Enhance Module (FEM) for transferring the original feature maps to extend the single shot detector to dual shot detector. Specially, Progressive Anchor Loss (PAL) computed by using two set of anchors is adopted to effectively facilitate the features. Additionally, we propose an Improved Anchor Matching (IAM) method by integrating novel data augmentation techniques and anchor design strategy in our DSFD to provide better initialization for the regressor. Extensive experiments on popular benchmarks: WIDER FACE (easy: $0.966$, medium: $0.957$, hard: $0.904$) and FDDB ( discontinuous: $0.991$, continuous: $0.862$) demonstrate the superiority of DSFD over the state-of-the-art face detectors (e.g., PyramidBox and SRN). Code will be made available upon publication.