 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecialized Re-Ranking: A Novel Retrieval-Verification Framework for Cloth Changing Person Re-Identification
Oct 07, 2022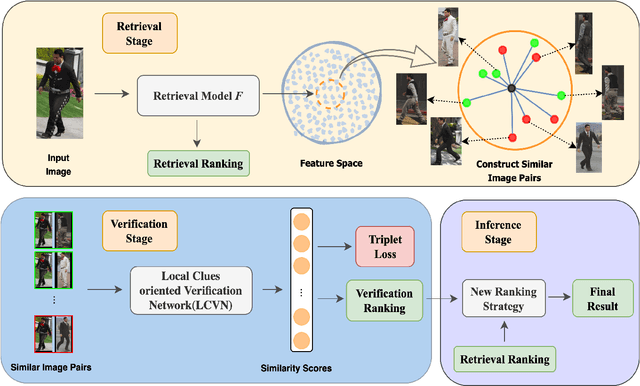
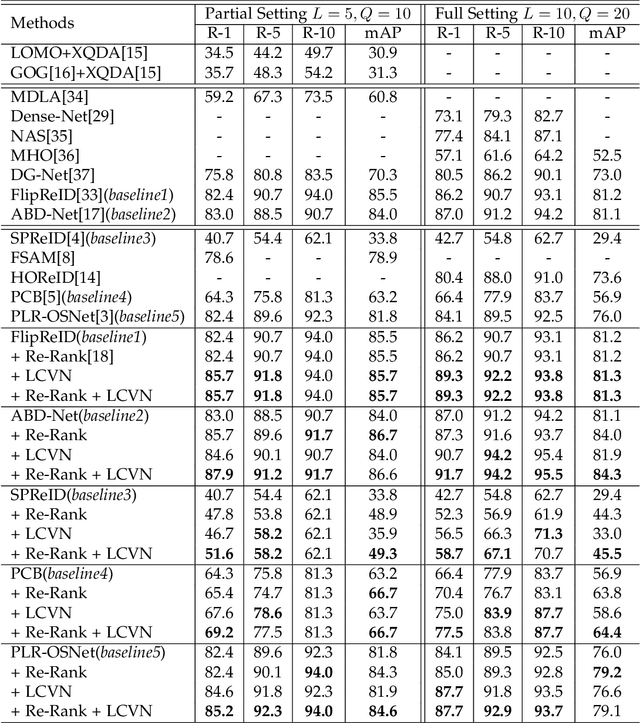
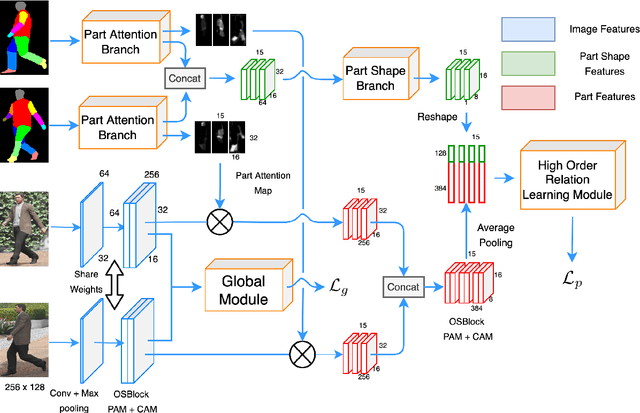

Cloth changing person re-identification(Re-ID) can work under more complicated scenarios with higher security than normal Re-ID and biometric techniques and is therefore extremely valuable in applications. Meanwhile, higher flexibility in appearance always leads to more similar-looking confusing images, which is the weakness of the widely used retrieval methods. In this work, we shed light on how to handle these similar images. Specifically, we propose a novel retrieval-verification framework. Given an image, the retrieval module can search for similar images quickly. Our proposed verification network will then compare the input image and the candidate images by contrasting those local details and give a similarity score. An innovative ranking strategy is also introduced to take a good balance between retrieval and verification results. Comprehensive experiments are conducted to show the effectiveness of our framework and its capability in improving the state-of-the-art methods remarkably on both synthetic and realistic datasets.
Chained-Tracker: Chaining Paired Attentive Regression Results for End-to-End Joint Multiple-Object Detection and Tracking
Jul 29, 2020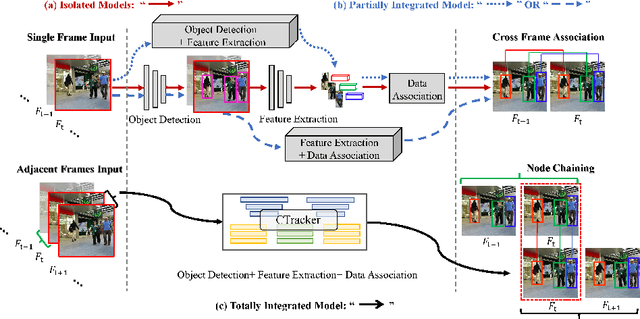

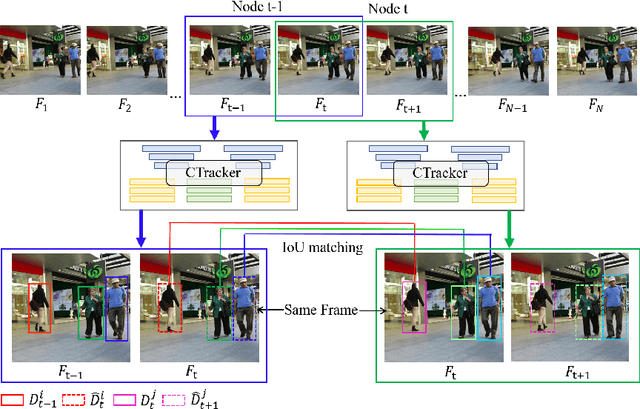
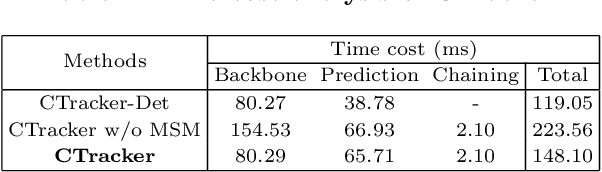
Existing Multiple-Object Tracking (MOT) methods either follow the tracking-by-detection paradigm to conduct object detection, feature extraction and data association separately, or have two of the three subtasks integrated to form a partially end-to-end solution. Going beyond these sub-optimal frameworks, we propose a simple online model named Chained-Tracker (CTracker), which naturally integrates all the three subtasks into an end-to-end solution (the first as far as we know). It chains paired bounding boxes regression results estimated from overlapping nodes, of which each node covers two adjacent frames. The paired regression is made attentive by object-attention (brought by a detection module) and identity-attention (ensured by an ID verification module). The two major novelties: chained structure and paired attentive regression, make CTracker simple, fast and effective, setting new MOTA records on MOT16 and MOT17 challenge datasets (67.6 and 66.6, respectively), without relying on any extra training data. The source code of CTracker can be found at: github.com/pjl1995/CTracker.
When Person Re-identification Meets Changing Clothes
Mar 16, 2020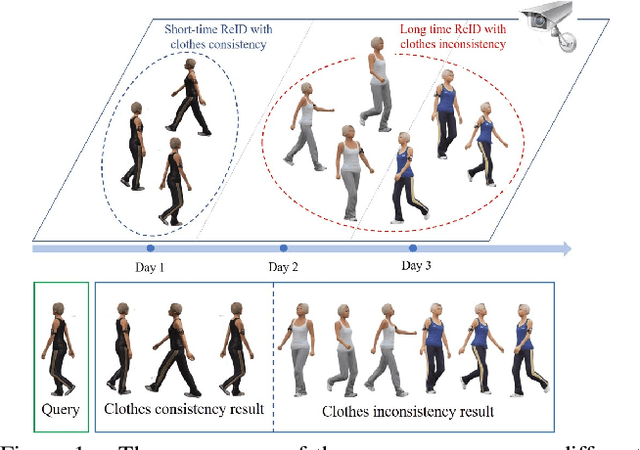
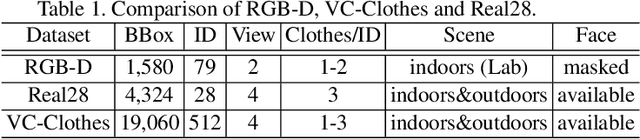

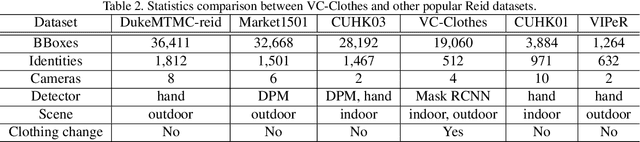
Person re-identification (Reid) is now an active research topic for AI-based video surveillance applications such as specific person search, but the practical issue that the target person(s) may change clothes (clothes inconsistency problem) has been overlooked for long. For the first time, this paper systematically studies this problem. We first overcome the difficulty of lack of suitable dataset, by collecting a small yet representative real dataset for testing whilst building a large realistic synthetic dataset for training and deeper studies. Facilitated by our new datasets, we are able to conduct various interesting new experiments for studying the influence of clothes inconsistency. We find that changing clothes makes Reid a much harder problem in the sense of bringing difficulties to learning effective representations and also challenges the generalization ability of previous Reid models to identify persons with unseen (new) clothes. Representative existing Reid models are adopted to show informative results on such a challenging setting, and we also provide some preliminary efforts on improving the robustness of existing models on handling the clothes inconsistency issue in the data. We believe that this study can be inspiring and helpful for encouraging more researches in this direction. The dataset is available on the project website: https://wanfb.github.io/dataset.html
Multiple Object Tracking by Flowing and Fusing
Jan 30, 2020

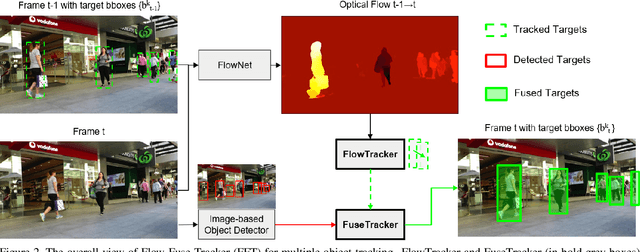

Most of Multiple Object Tracking (MOT) approaches compute individual target features for two subtasks: estimating target-wise motions and conducting pair-wise Re-Identification (Re-ID). Because of the indefinite number of targets among video frames, both subtasks are very difficult to scale up efficiently in end-to-end Deep Neural Networks (DNNs). In this paper, we design an end-to-end DNN tracking approach, Flow-Fuse-Tracker (FFT), that addresses the above issues with two efficient techniques: target flowing and target fusing. Specifically, in target flowing, a FlowTracker DNN module learns the indefinite number of target-wise motions jointly from pixel-level optical flows. In target fusing, a FuseTracker DNN module refines and fuses targets proposed by FlowTracker and frame-wise object detection, instead of trusting either of the two inaccurate sources of target proposal. Because FlowTracker can explore complex target-wise motion patterns and FuseTracker can refine and fuse targets from FlowTracker and detectors, our approach can achieve the state-of-the-art results on several MOT benchmarks. As an online MOT approach, FFT produced the top MOTA of 46.3 on the 2DMOT15, 56.5 on the MOT16, and 56.5 on the MOT17 tracking benchmarks, surpassing all the online and offline methods in existing publications.