 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching According to Students' Aptitude: Personalized Mathematics Tutoring via Persona-, Memory-, and Forgetting-Aware LLMs
Nov 19, 2025Large Language Models (LLMs) are increasingly integrated into intelligent tutoring systems to provide human-like and adaptive instruction. However, most existing approaches fail to capture how students' knowledge evolves dynamically across their proficiencies, conceptual gaps, and forgetting patterns. This challenge is particularly acute in mathematics tutoring, where effective instruction requires fine-grained scaffolding precisely calibrated to each student's mastery level and cognitive retention. To address this issue, we propose TASA (Teaching According to Students' Aptitude), a student-aware tutoring framework that integrates persona, memory, and forgetting dynamics for personalized mathematics learning. Specifically, TASA maintains a structured student persona capturing proficiency profiles and an event memory recording prior learning interactions. By incorporating a continuous forgetting curve with knowledge tracing, TASA dynamically updates each student's mastery state and generates contextually appropriate, difficulty-calibrated questions and explanations. Empirical results demonstrate that TASA achieves superior learning outcomes and more adaptive tutoring behavior compared to representative baselines, underscoring the importance of modeling temporal forgetting and learner profiles in LLM-based tutoring systems.
HyP-ASO: A Hybrid Policy-based Adaptive Search Optimization Framework for Large-Scale Integer Linear Programs
Sep 19, 2025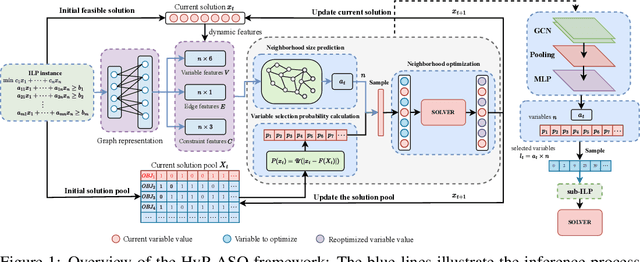

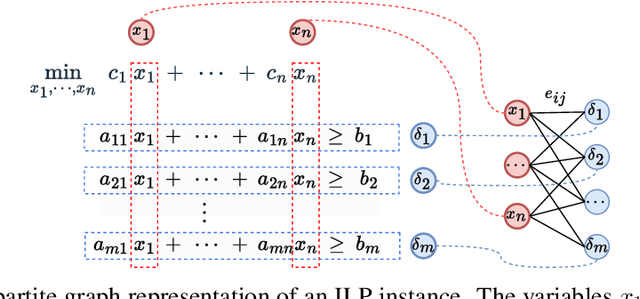
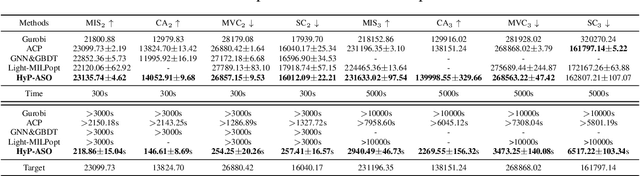
Directly solving large-scale Integer Linear Programs (ILPs) using traditional solvers is slow due to their NP-hard nature. While recent frameworks based on Large Neighborhood Search (LNS) can accelerate the solving process, their performance is often constrained by the difficulty in generating sufficiently effective neighborhoods. To address this challenge, we propose HyP-ASO, a hybrid policy-based adaptive search optimization framework that combines a customized formula with deep Reinforcement Learning (RL). The formula leverages feasible solutions to calculate the selection probabilities for each variable in the neighborhood generation process, and the RL policy network predicts the neighborhood size. Extensive experiments demonstrate that HyP-ASO significantly outperforms existing LNS-based approaches for large-scale ILPs. Additional experiments show it is lightweight and highly scalable, making it well-suited for solving large-scale ILPs.
Active Domain Knowledge Acquisition with \$100 Budget: Enhancing LLMs via Cost-Efficient, Expert-Involved Interaction in Sensitive Domains
Aug 24, 2025Large Language Models (LLMs) have demonstrated an impressive level of general knowledge. However, they often struggle in highly specialized and cost-sensitive domains such as drug discovery and rare disease research due to the lack of expert knowledge. In this paper, we propose a novel framework (PU-ADKA) designed to efficiently enhance domain-specific LLMs by actively engaging domain experts within a fixed budget. Unlike traditional fine-tuning approaches, PU-ADKA selectively identifies and queries the most appropriate expert from a team, taking into account each expert's availability, knowledge boundaries, and consultation costs. We train PU-ADKA using simulations on PubMed data and validate it through both controlled expert interactions and real-world deployment with a drug development team, demonstrating its effectiveness in enhancing LLM performance in specialized domains under strict budget constraints. In addition to outlining our methodological innovations and experimental results, we introduce a new benchmark dataset, CKAD, for cost-effective LLM domain knowledge acquisition to foster further research in this challenging area.
Eyepiece-free pupil-optimized holographic near-eye displays
Jul 30, 2025Computer-generated holography (CGH) represents a transformative visualization approach for next-generation immersive virtual and augmented reality (VR/AR) displays, enabling precise wavefront modulation and naturally providing comprehensive physiological depth cues without the need for bulky optical assemblies. Despite significant advancements in computational algorithms enhancing image quality and achieving real-time generation, practical implementations of holographic near-eye displays (NEDs) continue to face substantial challenges arising from finite and dynamically varying pupil apertures, which degrade image quality and compromise user experience. In this study, we introduce an eyepiece-free pupil-optimized holographic NED. Our proposed method employs a customized spherical phase modulation strategy to generate multiple viewpoints within the pupil, entirely eliminating the dependence on conventional optical eyepieces. Through the joint optimization of amplitude and phase distributions across these viewpoints, the method markedly mitigates image degradation due to finite pupil sampling and resolves inapparent depth cues induced by the spherical phase. The demonstrated method signifies a substantial advancement toward the realization of compact, lightweight, and flexible holographic NED systems, fulfilling stringent requirements for future VR/AR display technologies.
What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark for Essential Virtual Agent Capabilities
Jun 10, 2025
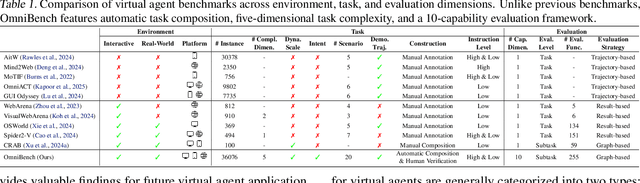

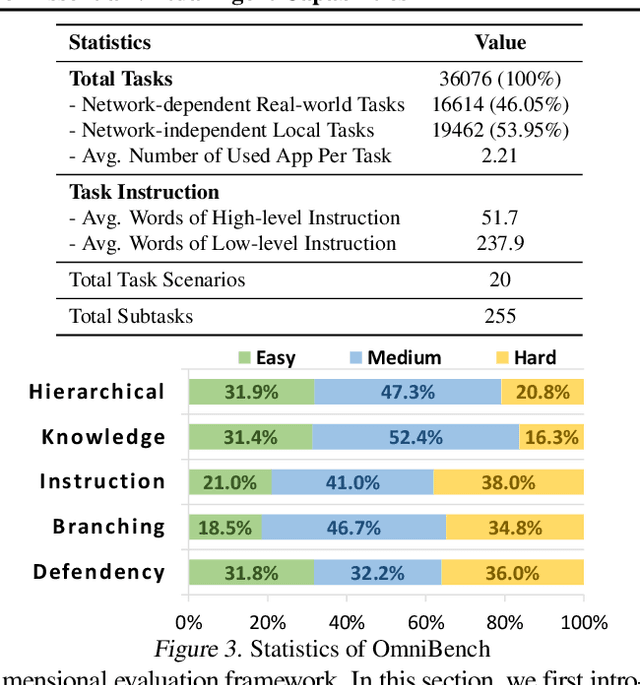
As multimodal large language models (MLLMs) advance, MLLM-based virtual agents have demonstrated remarkable performance. However, existing benchmarks face significant limitations, including uncontrollable task complexity, extensive manual annotation with limited scenarios, and a lack of multidimensional evaluation. In response to these challenges, we introduce OmniBench, a self-generating, cross-platform, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91\% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements. Our project is available at https://omni-bench.github.io/.
FocusDiff: Advancing Fine-Grained Text-Image Alignment for Autoregressive Visual Generation through RL
Jun 05, 2025Recent studies extend the autoregression paradigm to text-to-image generation, achieving performance comparable to diffusion models. However, our new PairComp benchmark -- featuring test cases of paired prompts with similar syntax but different fine-grained semantics -- reveals that existing models struggle with fine-grained text-image alignment thus failing to realize precise control over visual tokens. To address this, we propose FocusDiff, which enhances fine-grained text-image semantic alignment by focusing on subtle differences between similar text-image pairs. We construct a new dataset of paired texts and images with similar overall expressions but distinct local semantics, further introducing a novel reinforcement learning algorithm to emphasize such fine-grained semantic differences for desired image generation. Our approach achieves state-of-the-art performance on existing text-to-image benchmarks and significantly outperforms prior methods on PairComp.
WeatherGen: A Unified Diverse Weather Generator for LiDAR Point Clouds via Spider Mamba Diffusion
Apr 18, 2025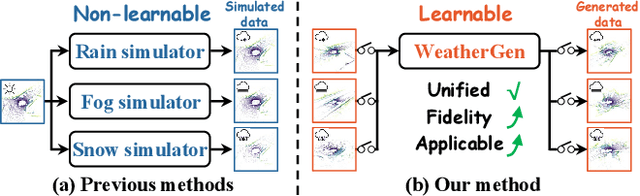

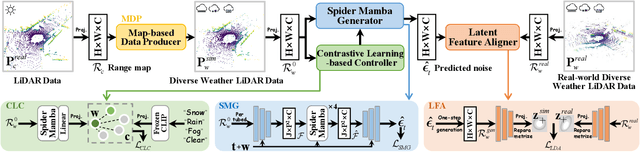

3D scene perception demands a large amount of adverse-weather LiDAR data, yet the cost of LiDAR data collection presents a significant scaling-up challenge. To this end, a series of LiDAR simulators have been proposed. Yet, they can only simulate a single adverse weather with a single physical model, and the fidelity of the generated data is quite limited. This paper presents WeatherGen, the first unified diverse-weather LiDAR data diffusion generation framework, significantly improving fidelity. Specifically, we first design a map-based data producer, which can provide a vast amount of high-quality diverse-weather data for training purposes. Then, we utilize the diffusion-denoising paradigm to construct a diffusion model. Among them, we propose a spider mamba generator to restore the disturbed diverse weather data gradually. The spider mamba models the feature interactions by scanning the LiDAR beam circle or central ray, excellently maintaining the physical structure of the LiDAR data. Subsequently, following the generator to transfer real-world knowledge, we design a latent feature aligner. Afterward, we devise a contrastive learning-based controller, which equips weather control signals with compact semantic knowledge through language supervision, guiding the diffusion model to generate more discriminative data. Extensive evaluations demonstrate the high generation quality of WeatherGen. Through WeatherGen, we construct the mini-weather dataset, promoting the performance of the downstream task under adverse weather conditions. Code is available: https://github.com/wuyang98/weathergen
Benchmarking Multimodal CoT Reward Model Stepwise by Visual Program
Apr 09, 2025Recent advancements in reward signal usage for Large Language Models (LLMs) are remarkable. However, significant challenges exist when transitioning reward signal to the multimodal domain, including labor-intensive annotations, over-reliance on one-step rewards, and inadequate evaluation. To address these issues, we propose SVIP, a novel approach to train a step-level multi-dimensional Chain-of-Thought~(CoT) reward model automatically. It generates code for solving visual tasks and transforms the analysis of code blocks into the evaluation of CoT step as training samples. Then, we train SVIP-Reward model using a multi-head attention mechanism called TriAtt-CoT. The advantages of SVIP-Reward are evident throughout the entire process of MLLM. We also introduce a benchmark for CoT reward model training and testing. Experimental results demonstrate that SVIP-Reward improves MLLM performance across training and inference-time scaling, yielding better results on benchmarks while reducing hallucinations and enhancing reasoning ability.
Boosting Virtual Agent Learning and Reasoning: A Step-wise, Multi-dimensional, and Generalist Reward Model with Benchmark
Mar 24, 2025The development of Generalist Virtual Agents (GVAs) powered by Multimodal Large Language Models (MLLMs) has shown significant promise in autonomous task execution. However, current training paradigms face critical limitations, including reliance on outcome supervision and labor-intensive human annotations. To address these challenges, we propose Similar, a Step-wise Multi-dimensional Generalist Reward Model, which offers fine-grained signals for agent training and can choose better action for inference-time scaling. Specifically, we begin by systematically defining five dimensions for evaluating agent actions. Building on this framework, we design an MCTS-P algorithm to automatically collect and annotate step-wise, five-dimensional agent execution data. Using this data, we train Similar with the Triple-M strategy. Furthermore, we introduce the first benchmark in the virtual agent domain for step-wise, multi-dimensional reward model training and evaluation, named SRM. This benchmark consists of two components: SRMTrain, which serves as the training set for Similar, and SRMEval, a manually selected test set for evaluating the reward model. Experimental results demonstrate that Similar, through its step-wise, multi-dimensional assessment and synergistic gain, provides GVAs with effective intermediate signals during both training and inference-time scaling. The code is available at https://github.com/Galery23/Similar-v1.
Vulnerability of Text-to-Image Models to Prompt Template Stealing: A Differential Evolution Approach
Feb 20, 2025Prompt trading has emerged as a significant intellectual property concern in recent years, where vendors entice users by showcasing sample images before selling prompt templates that can generate similar images. This work investigates a critical security vulnerability: attackers can steal prompt templates using only a limited number of sample images. To investigate this threat, we introduce Prism, a prompt-stealing benchmark consisting of 50 templates and 450 images, organized into Easy and Hard difficulty levels. To identify the vulnerabity of VLMs to prompt stealing, we propose EvoStealer, a novel template stealing method that operates without model fine-tuning by leveraging differential evolution algorithms. The system first initializes population sets using multimodal large language models (MLLMs) based on predefined patterns, then iteratively generates enhanced offspring through MLLMs. During evolution, EvoStealer identifies common features across offspring to derive generalized templates. Our comprehensive evaluation conducted across open-source (INTERNVL2-26B) and closed-source models (GPT-4o and GPT-4o-mini) demonstrates that EvoStealer's stolen templates can reproduce images highly similar to originals and effectively generalize to other subjects, significantly outperforming baseline methods with an average improvement of over 10%. Moreover, our cost analysis reveals that EvoStealer achieves template stealing with negligible computational expenses. Our code and dataset are available at https://github.com/whitepagewu/evostealer.