 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsightTok: Improving Text and Face Fidelity in Discrete Tokenization for Autoregressive Image Generation
May 14, 2026Text and faces are among the most perceptually salient and practically important patterns in visual generation, yet they remain challenging for autoregressive generators built on discrete tokenization. A central bottleneck is the tokenizer: aggressive downsampling and quantization often discard the fine-grained structures needed to preserve readable glyphs and distinctive facial features. We attribute this gap to standard discrete-tokenizer objectives being weakly aligned with text legibility and facial fidelity, as these objectives typically optimize generic reconstruction while compressing diverse content uniformly. To address this, we propose InsightTok, a simple yet effective discrete visual tokenization framework that enhances text and face fidelity through localized, content-aware perceptual losses. With a compact 16k codebook and a 16x downsampling rate, InsightTok significantly outperforms prior tokenizers in text and face reconstruction without compromising general reconstruction quality. These gains consistently transfer to autoregressive image generation in InsightAR, producing images with clearer text and more faithful facial details. Overall, our results highlight the potential of specialized supervision in tokenizer training for advancing discrete image generation.
Spatia: Video Generation with Updatable Spatial Memory
Dec 17, 2025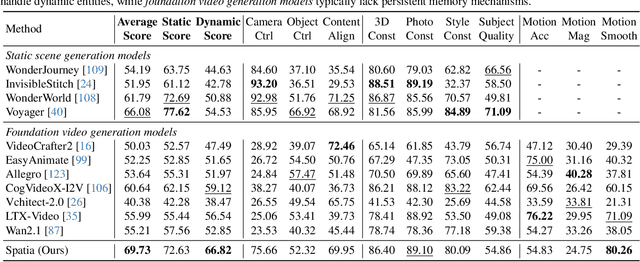
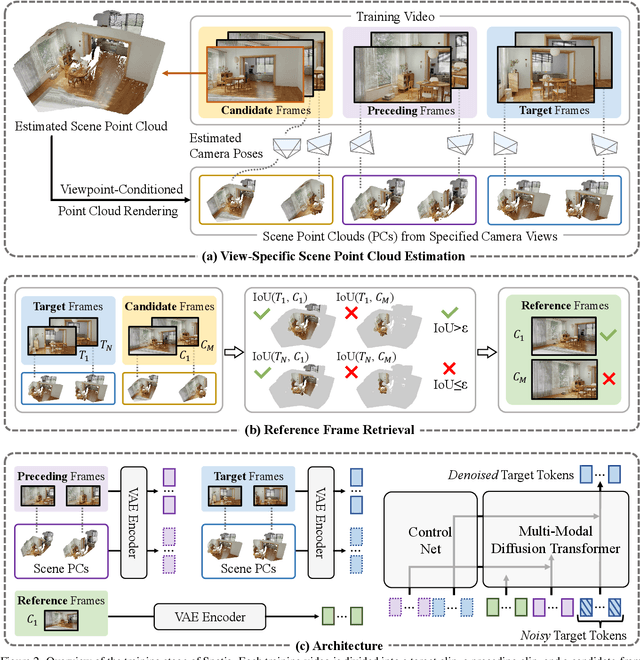

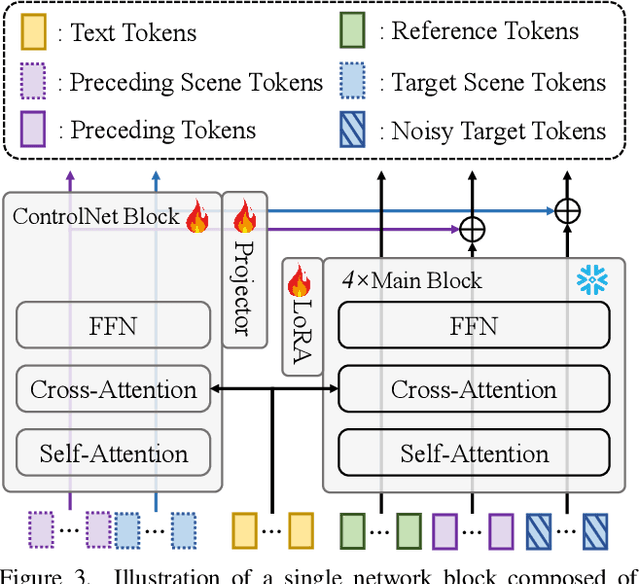
Existing video generation models struggle to maintain long-term spatial and temporal consistency due to the dense, high-dimensional nature of video signals. To overcome this limitation, we propose Spatia, a spatial memory-aware video generation framework that explicitly preserves a 3D scene point cloud as persistent spatial memory. Spatia iteratively generates video clips conditioned on this spatial memory and continuously updates it through visual SLAM. This dynamic-static disentanglement design enhances spatial consistency throughout the generation process while preserving the model's ability to produce realistic dynamic entities. Furthermore, Spatia enables applications such as explicit camera control and 3D-aware interactive editing, providing a geometrically grounded framework for scalable, memory-driven video generation.
From Virtual Games to Real-World Play
Jun 23, 2025



We introduce RealPlay, a neural network-based real-world game engine that enables interactive video generation from user control signals. Unlike prior works focused on game-style visuals, RealPlay aims to produce photorealistic, temporally consistent video sequences that resemble real-world footage. It operates in an interactive loop: users observe a generated scene, issue a control command, and receive a short video chunk in response. To enable such realistic and responsive generation, we address key challenges including iterative chunk-wise prediction for low-latency feedback, temporal consistency across iterations, and accurate control response. RealPlay is trained on a combination of labeled game data and unlabeled real-world videos, without requiring real-world action annotations. Notably, we observe two forms of generalization: (1) control transfer-RealPlay effectively maps control signals from virtual to real-world scenarios; and (2) entity transfer-although training labels originate solely from a car racing game, RealPlay generalizes to control diverse real-world entities, including bicycles and pedestrians, beyond vehicles. Project page can be found: https://wenqsun.github.io/RealPlay/
Vulnerability of Text-to-Image Models to Prompt Template Stealing: A Differential Evolution Approach
Feb 20, 2025Prompt trading has emerged as a significant intellectual property concern in recent years, where vendors entice users by showcasing sample images before selling prompt templates that can generate similar images. This work investigates a critical security vulnerability: attackers can steal prompt templates using only a limited number of sample images. To investigate this threat, we introduce Prism, a prompt-stealing benchmark consisting of 50 templates and 450 images, organized into Easy and Hard difficulty levels. To identify the vulnerabity of VLMs to prompt stealing, we propose EvoStealer, a novel template stealing method that operates without model fine-tuning by leveraging differential evolution algorithms. The system first initializes population sets using multimodal large language models (MLLMs) based on predefined patterns, then iteratively generates enhanced offspring through MLLMs. During evolution, EvoStealer identifies common features across offspring to derive generalized templates. Our comprehensive evaluation conducted across open-source (INTERNVL2-26B) and closed-source models (GPT-4o and GPT-4o-mini) demonstrates that EvoStealer's stolen templates can reproduce images highly similar to originals and effectively generalize to other subjects, significantly outperforming baseline methods with an average improvement of over 10%. Moreover, our cost analysis reveals that EvoStealer achieves template stealing with negligible computational expenses. Our code and dataset are available at https://github.com/whitepagewu/evostealer.
Revisiting Referring Expression Comprehension Evaluation in the Era of Large Multimodal Models
Jun 24, 2024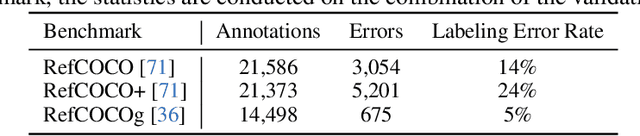
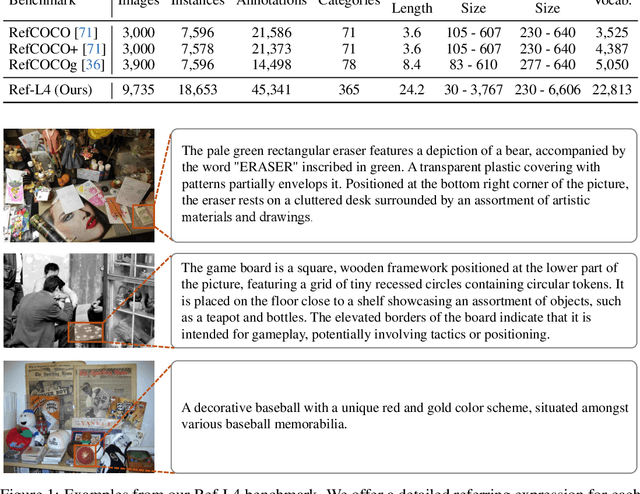
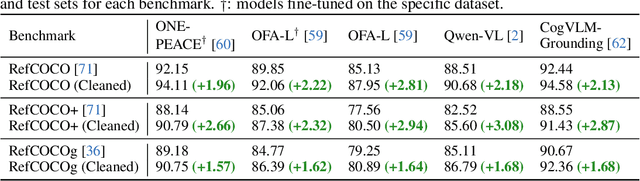
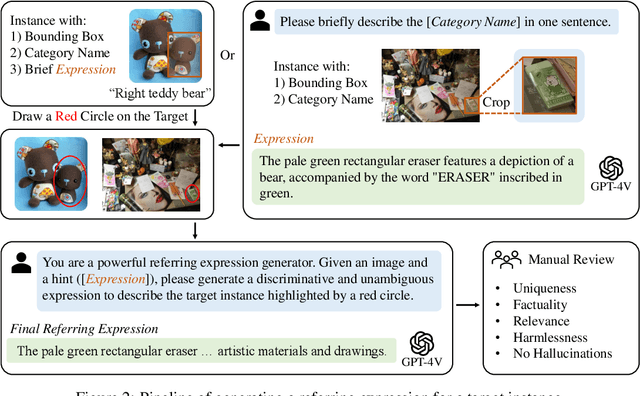
Referring expression comprehension (REC) involves localizing a target instance based on a textual description. Recent advancements in REC have been driven by large multimodal models (LMMs) like CogVLM, which achieved 92.44% accuracy on RefCOCO. However, this study questions whether existing benchmarks such as RefCOCO, RefCOCO+, and RefCOCOg, capture LMMs' comprehensive capabilities. We begin with a manual examination of these benchmarks, revealing high labeling error rates: 14% in RefCOCO, 24% in RefCOCO+, and 5% in RefCOCOg, which undermines the authenticity of evaluations. We address this by excluding problematic instances and reevaluating several LMMs capable of handling the REC task, showing significant accuracy improvements, thus highlighting the impact of benchmark noise. In response, we introduce Ref-L4, a comprehensive REC benchmark, specifically designed to evaluate modern REC models. Ref-L4 is distinguished by four key features: 1) a substantial sample size with 45,341 annotations; 2) a diverse range of object categories with 365 distinct types and varying instance scales from 30 to 3,767; 3) lengthy referring expressions averaging 24.2 words; and 4) an extensive vocabulary comprising 22,813 unique words. We evaluate a total of 24 large models on Ref-L4 and provide valuable insights. The cleaned versions of RefCOCO, RefCOCO+, and RefCOCOg, as well as our Ref-L4 benchmark and evaluation code, are available at https://github.com/JierunChen/Ref-L4.
MAGIC: Detecting Advanced Persistent Threats via Masked Graph Representation Learning
Oct 15, 2023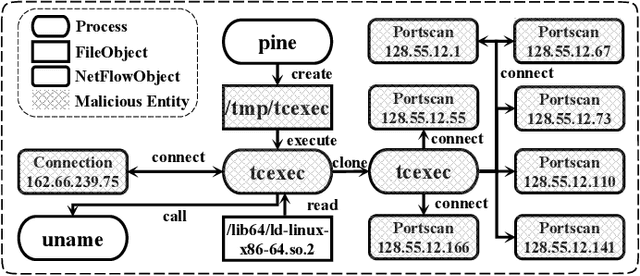



Advance Persistent Threats (APTs), adopted by most delicate attackers, are becoming increasing common and pose great threat to various enterprises and institutions. Data provenance analysis on provenance graphs has emerged as a common approach in APT detection. However, previous works have exhibited several shortcomings: (1) requiring attack-containing data and a priori knowledge of APTs, (2) failing in extracting the rich contextual information buried within provenance graphs and (3) becoming impracticable due to their prohibitive computation overhead and memory consumption. In this paper, we introduce MAGIC, a novel and flexible self-supervised APT detection approach capable of performing multi-granularity detection under different level of supervision. MAGIC leverages masked graph representation learning to model benign system entities and behaviors, performing efficient deep feature extraction and structure abstraction on provenance graphs. By ferreting out anomalous system behaviors via outlier detection methods, MAGIC is able to perform both system entity level and batched log level APT detection. MAGIC is specially designed to handle concept drift with a model adaption mechanism and successfully applies to universal conditions and detection scenarios. We evaluate MAGIC on three widely-used datasets, including both real-world and simulated attacks. Evaluation results indicate that MAGIC achieves promising detection results in all scenarios and shows enormous advantage over state-of-the-art APT detection approaches in performance overhead.
RAIN: Your Language Models Can Align Themselves without Finetuning
Sep 13, 2023Large language models (LLMs) often demonstrate inconsistencies with human preferences. Previous research gathered human preference data and then aligned the pre-trained models using reinforcement learning or instruction tuning, the so-called finetuning step. In contrast, aligning frozen LLMs without any extra data is more appealing. This work explores the potential of the latter setting. We discover that by integrating self-evaluation and rewind mechanisms, unaligned LLMs can directly produce responses consistent with human preferences via self-boosting. We introduce a novel inference method, Rewindable Auto-regressive INference (RAIN), that allows pre-trained LLMs to evaluate their own generation and use the evaluation results to guide backward rewind and forward generation for AI safety. Notably, RAIN operates without the need of extra data for model alignment and abstains from any training, gradient computation, or parameter updates; during the self-evaluation phase, the model receives guidance on which human preference to align with through a fixed-template prompt, eliminating the need to modify the initial prompt. Experimental results evaluated by GPT-4 and humans demonstrate the effectiveness of RAIN: on the HH dataset, RAIN improves the harmlessness rate of LLaMA 30B over vanilla inference from 82% to 97%, while maintaining the helpfulness rate. Under the leading adversarial attack llm-attacks on Vicuna 33B, RAIN establishes a new defense baseline by reducing the attack success rate from 94% to 19%.
Tree-based Search Graph for Approximate Nearest Neighbor Search
Jan 10, 2022

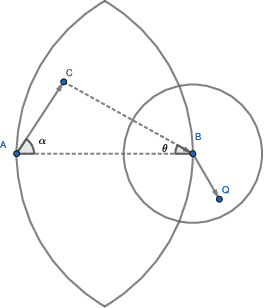
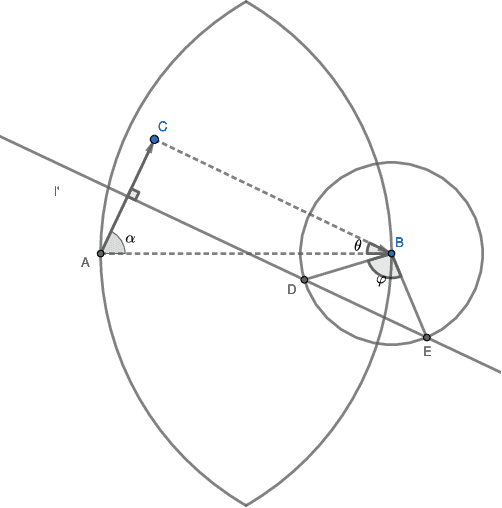
Nearest neighbor search supports important applications in many domains, such as database, machine learning, computer vision. Since the computational cost for accurate search is too high, the community turned to the research of approximate nearest neighbor search (ANNS). Among them, graph-based algorithm is one of the most important branches. Research by Fu et al. shows that the algorithms based on Monotonic Search Network (MSNET), such as NSG and NSSG, have achieved the state-of-the-art search performance in efficiency. The MSNET is dedicated to achieving monotonic search with minimal out-degree of nodes to pursue high efficiency. However, the current MSNET designs did not optimize the probability of the monotonic search, and the lower bound of the probability is only 50%. If they fail in monotonic search stage, they have to suffer tremendous backtracking cost to achieve the required accuracy. This will cause performance problems in search efficiency. To address this problem, we propose (r,p)-MSNET, which achieves guaranteed probability on monotonic search. Due to the high building complexity of a strict (r,p)-MSNET, we propose TBSG, which is an approximation with low complexity. Experiment conducted on four million-scaled datasets show that TBSG outperforms existing state-of-the-art graph-based algorithms in search efficiency. Our code has been released on Github.