 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSBF: An Effective Representation to Augment Skeleton for Video-based Human Action Recognition
Apr 04, 2026Many modern video-based human action recognition (HAR) approaches use 2D skeleton as the intermediate representation in their prediction pipelines. Despite overall encouraging results, these approaches still struggle in many common scenes, mainly because the skeleton does not capture critical action-related information pertaining to the depth of the joints, contour of the human body, and interaction between the human and objects. To address this, we propose an effective approach to augment skeleton with a representation capturing action-related information in the pipeline of HAR. The representation, termed Scale-Body-Flow (SBF), consists of three distinct components, namely a scale map volume given by the scale (and hence depth information) of each joint, a body map outlining the human subject, and a flow map indicating human-object interaction given by pixel-wise optical flow values. To predict SBF, we further present SFSNet, a novel segmentation network supervised by the skeleton and optical flow without extra annotation overhead beyond the existing skeleton extraction. Extensive experiments across different datasets demonstrate that our pipeline based on SBF and SFSNet achieves significantly higher HAR accuracy with similar compactness and efficiency as compared with the state-of-the-art skeleton-only approaches.
Expanding mmWave Datasets for Human Pose Estimation with Unlabeled Data and LiDAR Datasets
Mar 15, 2026Current mmWave datasets for human pose estimation (HPE) are scarce and lack diversity in both point cloud (PC) attributes and human poses, severely hampering the generalization ability of their trained models. On the other hand, unlabeled mmWave HPE data and diverse LiDAR HPE datasets are readily available. We propose EMDUL, a novel approach to expand the volume and diversity of an existing mmWave dataset using unlabeled mmWave data and a LiDAR dataset. EMDUL trains a pseudo-label estimator to annotate the unlabeled mmWave data and is able to convert, or translate, a given annotated LiDAR PC to its mmWave counterpart. Expanded with both LiDAR-converted and pseudo-labeled mmWave PCs, our mmWave dataset significantly boosts the performance and generalization ability of all our HPE models, with substantial 15.1% and 18.9% error reductions for in-domain and out-of-domain settings, respectively.
Revisiting Referring Expression Comprehension Evaluation in the Era of Large Multimodal Models
Jun 24, 2024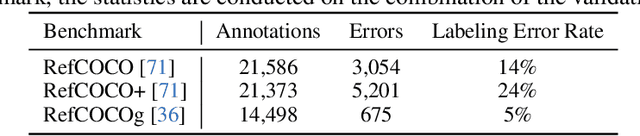
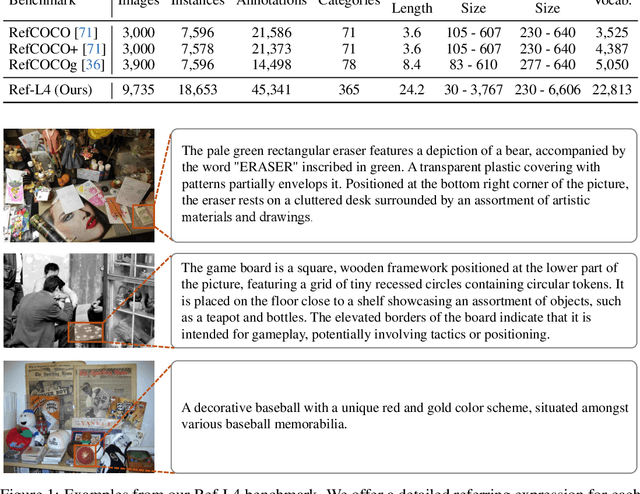
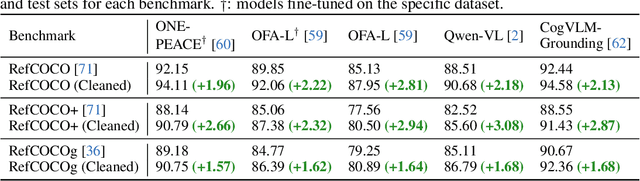
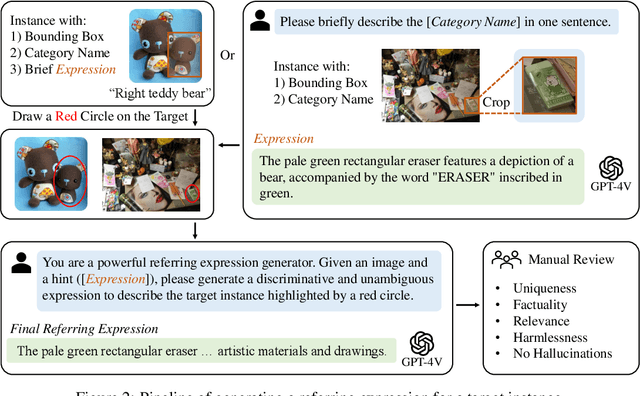
Referring expression comprehension (REC) involves localizing a target instance based on a textual description. Recent advancements in REC have been driven by large multimodal models (LMMs) like CogVLM, which achieved 92.44% accuracy on RefCOCO. However, this study questions whether existing benchmarks such as RefCOCO, RefCOCO+, and RefCOCOg, capture LMMs' comprehensive capabilities. We begin with a manual examination of these benchmarks, revealing high labeling error rates: 14% in RefCOCO, 24% in RefCOCO+, and 5% in RefCOCOg, which undermines the authenticity of evaluations. We address this by excluding problematic instances and reevaluating several LMMs capable of handling the REC task, showing significant accuracy improvements, thus highlighting the impact of benchmark noise. In response, we introduce Ref-L4, a comprehensive REC benchmark, specifically designed to evaluate modern REC models. Ref-L4 is distinguished by four key features: 1) a substantial sample size with 45,341 annotations; 2) a diverse range of object categories with 365 distinct types and varying instance scales from 30 to 3,767; 3) lengthy referring expressions averaging 24.2 words; and 4) an extensive vocabulary comprising 22,813 unique words. We evaluate a total of 24 large models on Ref-L4 and provide valuable insights. The cleaned versions of RefCOCO, RefCOCO+, and RefCOCOg, as well as our Ref-L4 benchmark and evaluation code, are available at https://github.com/JierunChen/Ref-L4.
Single Domain Generalization for Crowd Counting
Mar 14, 2024Current image-based crowd counting widely employs density map regression due to its promising results. However, the method often suffers from severe performance degradation when tested on data from unseen scenarios. To address this so-called "domain shift" problem, we investigate single domain generalization (SDG) for crowd counting. The existing SDG approaches are mainly for classification and segmentation, and can hardly be extended to our case due to its regression nature and label ambiguity (i.e., ambiguous pixel-level ground truths). We propose MPCount, a novel SDG approach effective even for narrow source distribution. Reconstructing diverse features for density map regression with a single memory bank, MPCount retains only domain-invariant representations using a content error mask and attention consistency loss. It further introduces patch-wise classification as an auxiliary task to boost the robustness of density prediction to achieve highly accurate labels. Through extensive experiments on different datasets, MPCount is shown to significantly improve counting accuracy compared to the state of the art under diverse scenarios unobserved in the training data of narrow source distribution. Code is available at https://github.com/Shimmer93/MPCount.