 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSBF: An Effective Representation to Augment Skeleton for Video-based Human Action Recognition
Apr 04, 2026Many modern video-based human action recognition (HAR) approaches use 2D skeleton as the intermediate representation in their prediction pipelines. Despite overall encouraging results, these approaches still struggle in many common scenes, mainly because the skeleton does not capture critical action-related information pertaining to the depth of the joints, contour of the human body, and interaction between the human and objects. To address this, we propose an effective approach to augment skeleton with a representation capturing action-related information in the pipeline of HAR. The representation, termed Scale-Body-Flow (SBF), consists of three distinct components, namely a scale map volume given by the scale (and hence depth information) of each joint, a body map outlining the human subject, and a flow map indicating human-object interaction given by pixel-wise optical flow values. To predict SBF, we further present SFSNet, a novel segmentation network supervised by the skeleton and optical flow without extra annotation overhead beyond the existing skeleton extraction. Extensive experiments across different datasets demonstrate that our pipeline based on SBF and SFSNet achieves significantly higher HAR accuracy with similar compactness and efficiency as compared with the state-of-the-art skeleton-only approaches.
Expanding mmWave Datasets for Human Pose Estimation with Unlabeled Data and LiDAR Datasets
Mar 15, 2026Current mmWave datasets for human pose estimation (HPE) are scarce and lack diversity in both point cloud (PC) attributes and human poses, severely hampering the generalization ability of their trained models. On the other hand, unlabeled mmWave HPE data and diverse LiDAR HPE datasets are readily available. We propose EMDUL, a novel approach to expand the volume and diversity of an existing mmWave dataset using unlabeled mmWave data and a LiDAR dataset. EMDUL trains a pseudo-label estimator to annotate the unlabeled mmWave data and is able to convert, or translate, a given annotated LiDAR PC to its mmWave counterpart. Expanded with both LiDAR-converted and pseudo-labeled mmWave PCs, our mmWave dataset significantly boosts the performance and generalization ability of all our HPE models, with substantial 15.1% and 18.9% error reductions for in-domain and out-of-domain settings, respectively.
RoboMirror: Understand Before You Imitate for Video to Humanoid Locomotion
Dec 30, 2025Humans learn locomotion through visual observation, interpreting visual content first before imitating actions. However, state-of-the-art humanoid locomotion systems rely on either curated motion capture trajectories or sparse text commands, leaving a critical gap between visual understanding and control. Text-to-motion methods suffer from semantic sparsity and staged pipeline errors, while video-based approaches only perform mechanical pose mimicry without genuine visual understanding. We propose RoboMirror, the first retargeting-free video-to-locomotion framework embodying "understand before you imitate". Leveraging VLMs, it distills raw egocentric/third-person videos into visual motion intents, which directly condition a diffusion-based policy to generate physically plausible, semantically aligned locomotion without explicit pose reconstruction or retargeting. Extensive experiments validate the effectiveness of RoboMirror, it enables telepresence via egocentric videos, drastically reduces third-person control latency by 80%, and achieves a 3.7% higher task success rate than baselines. By reframing humanoid control around video understanding, we bridge the visual understanding and action gap.
LoRaCompass: Robust Reinforcement Learning to Efficiently Search for a LoRa Tag
Nov 14, 2025


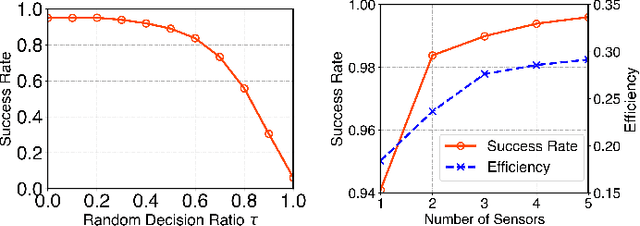
The Long-Range (LoRa) protocol, known for its extensive range and low power, has increasingly been adopted in tags worn by mentally incapacitated persons (MIPs) and others at risk of going missing. We study the sequential decision-making process for a mobile sensor to locate a periodically broadcasting LoRa tag with the fewest moves (hops) in general, unknown environments, guided by the received signal strength indicator (RSSI). While existing methods leverage reinforcement learning for search, they remain vulnerable to domain shift and signal fluctuation, resulting in cascading decision errors that culminate in substantial localization inaccuracies. To bridge this gap, we propose LoRaCompass, a reinforcement learning model designed to achieve robust and efficient search for a LoRa tag. For exploitation under domain shift and signal fluctuation, LoRaCompass learns a robust spatial representation from RSSI to maximize the probability of moving closer to a tag, via a spatially-aware feature extractor and a policy distillation loss function. It further introduces an exploration function inspired by the upper confidence bound (UCB) that guides the sensor toward the tag with increasing confidence. We have validated LoRaCompass in ground-based and drone-assisted scenarios within diverse unseen environments covering an area of over 80km^2. It has demonstrated high success rate (>90%) in locating the tag within 100m proximity (a 40% improvement over existing methods) and high efficiency with a search path length (in hops) that scales linearly with the initial distance.
Continuous Semi-Implicit Models
Jun 07, 2025Semi-implicit distributions have shown great promise in variational inference and generative modeling. Hierarchical semi-implicit models, which stack multiple semi-implicit layers, enhance the expressiveness of semi-implicit distributions and can be used to accelerate diffusion models given pretrained score networks. However, their sequential training often suffers from slow convergence. In this paper, we introduce CoSIM, a continuous semi-implicit model that extends hierarchical semi-implicit models into a continuous framework. By incorporating a continuous transition kernel, CoSIM enables efficient, simulation-free training. Furthermore, we show that CoSIM achieves consistency with a carefully designed transition kernel, offering a novel approach for multistep distillation of generative models at the distributional level. Extensive experiments on image generation demonstrate that CoSIM performs on par or better than existing diffusion model acceleration methods, achieving superior performance on FD-DINOv2.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
M$^3$-Impute: Mask-guided Representation Learning for Missing Value Imputation
Oct 11, 2024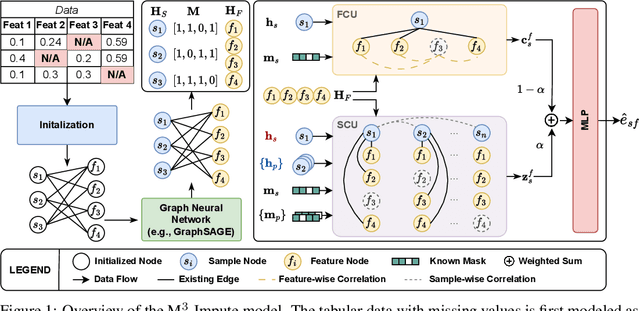
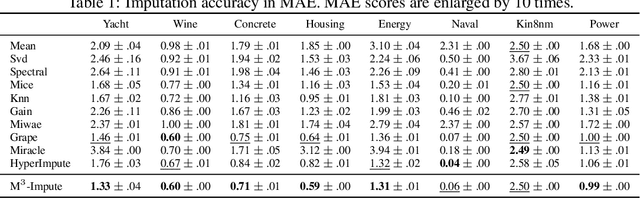
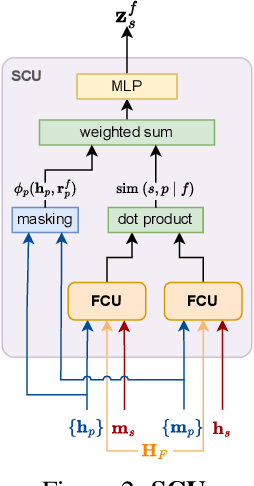
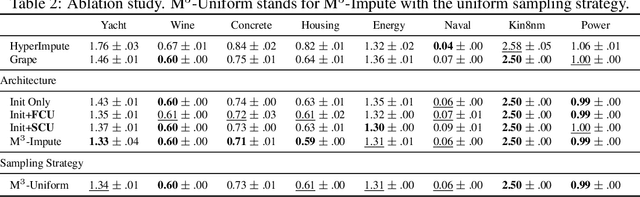
Missing values are a common problem that poses significant challenges to data analysis and machine learning. This problem necessitates the development of an effective imputation method to fill in the missing values accurately, thereby enhancing the overall quality and utility of the datasets. Existing imputation methods, however, fall short of explicitly considering the `missingness' information in the data during the embedding initialization stage and modeling the entangled feature and sample correlations during the learning process, thus leading to inferior performance. We propose M$^3$-Impute, which aims to explicitly leverage the missingness information and such correlations with novel masking schemes. M$^3$-Impute first models the data as a bipartite graph and uses a graph neural network to learn node embeddings, where the refined embedding initialization process directly incorporates the missingness information. They are then optimized through M$^3$-Impute's novel feature correlation unit (FRU) and sample correlation unit (SRU) that effectively captures feature and sample correlations for imputation. Experiment results on 25 benchmark datasets under three different missingness settings show the effectiveness of M$^3$-Impute by achieving 20 best and 4 second-best MAE scores on average.
Revisiting Referring Expression Comprehension Evaluation in the Era of Large Multimodal Models
Jun 24, 2024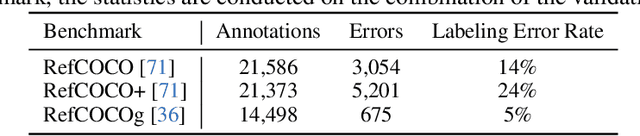
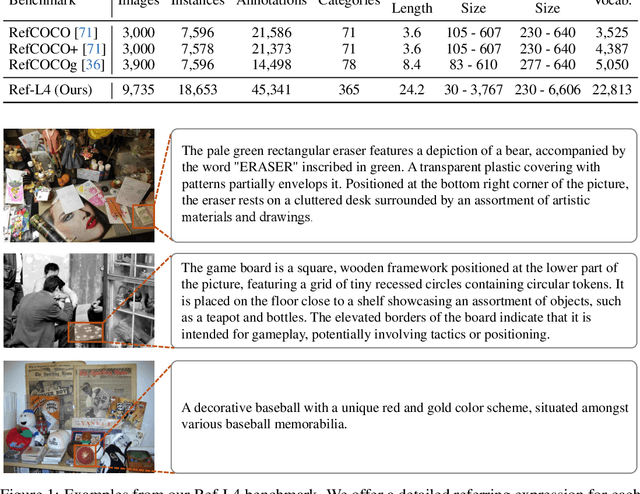
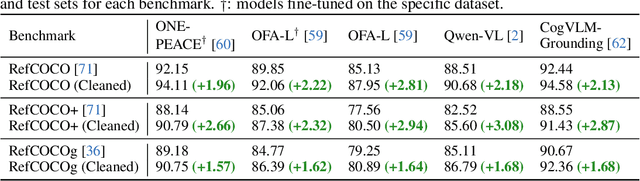
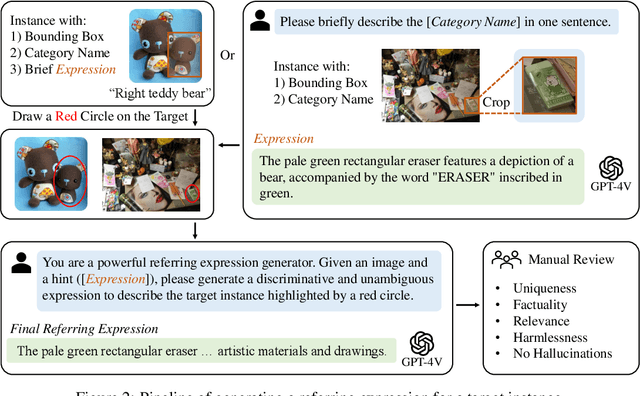
Referring expression comprehension (REC) involves localizing a target instance based on a textual description. Recent advancements in REC have been driven by large multimodal models (LMMs) like CogVLM, which achieved 92.44% accuracy on RefCOCO. However, this study questions whether existing benchmarks such as RefCOCO, RefCOCO+, and RefCOCOg, capture LMMs' comprehensive capabilities. We begin with a manual examination of these benchmarks, revealing high labeling error rates: 14% in RefCOCO, 24% in RefCOCO+, and 5% in RefCOCOg, which undermines the authenticity of evaluations. We address this by excluding problematic instances and reevaluating several LMMs capable of handling the REC task, showing significant accuracy improvements, thus highlighting the impact of benchmark noise. In response, we introduce Ref-L4, a comprehensive REC benchmark, specifically designed to evaluate modern REC models. Ref-L4 is distinguished by four key features: 1) a substantial sample size with 45,341 annotations; 2) a diverse range of object categories with 365 distinct types and varying instance scales from 30 to 3,767; 3) lengthy referring expressions averaging 24.2 words; and 4) an extensive vocabulary comprising 22,813 unique words. We evaluate a total of 24 large models on Ref-L4 and provide valuable insights. The cleaned versions of RefCOCO, RefCOCO+, and RefCOCOg, as well as our Ref-L4 benchmark and evaluation code, are available at https://github.com/JierunChen/Ref-L4.
Elevator, Escalator or Neither? Classifying Pedestrian Conveyor State Using Inertial Navigation System
May 06, 2024



Classifying a pedestrian in one of the three conveyor states of "elevator," "escalator" and "neither" is fundamental to many applications such as indoor localization and people flow analysis. We estimate, for the first time, the pedestrian conveyor state given the inertial navigation system (INS) readings of accelerometer, gyroscope and magnetometer sampled from the phone. Our problem is challenging because the INS signals of the conveyor state are coupled and perturbed by unpredictable arbitrary human actions, confusing the decision process. We propose ELESON, a novel, effective and lightweight INS-based deep learning approach to classify whether a pedestrian is in an elevator, escalator or neither. ELESON utilizes a motion feature extractor to decouple the conveyor state from human action in the feature space, and a magnetic feature extractor to account for the speed difference between elevator and escalator. Given the results of the extractors, it employs an evidential state classifier to estimate the confidence of the pedestrian states. Based on extensive experiments conducted on twenty hours of real pedestrian data, we demonstrate that ELESON outperforms significantly the state-of-the-art approaches (where combined INS signals of both the conveyor state and human actions are processed together), with 15% classification improvement in F1 score, stronger confidence discriminability with 10% increase in AUROC (Area Under the Receiver Operating Characteristics), and low computational and memory requirements on smartphones.
Single Domain Generalization for Crowd Counting
Mar 14, 2024Current image-based crowd counting widely employs density map regression due to its promising results. However, the method often suffers from severe performance degradation when tested on data from unseen scenarios. To address this so-called "domain shift" problem, we investigate single domain generalization (SDG) for crowd counting. The existing SDG approaches are mainly for classification and segmentation, and can hardly be extended to our case due to its regression nature and label ambiguity (i.e., ambiguous pixel-level ground truths). We propose MPCount, a novel SDG approach effective even for narrow source distribution. Reconstructing diverse features for density map regression with a single memory bank, MPCount retains only domain-invariant representations using a content error mask and attention consistency loss. It further introduces patch-wise classification as an auxiliary task to boost the robustness of density prediction to achieve highly accurate labels. Through extensive experiments on different datasets, MPCount is shown to significantly improve counting accuracy compared to the state of the art under diverse scenarios unobserved in the training data of narrow source distribution. Code is available at https://github.com/Shimmer93/MPCount.