 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices
Jan 13, 2026Recent advances in diffusion transformers (DiTs) have set new standards in image generation, yet remain impractical for on-device deployment due to their high computational and memory costs. In this work, we present an efficient DiT framework tailored for mobile and edge devices that achieves transformer-level generation quality under strict resource constraints. Our design combines three key components. First, we propose a compact DiT architecture with an adaptive global-local sparse attention mechanism that balances global context modeling and local detail preservation. Second, we propose an elastic training framework that jointly optimizes sub-DiTs of varying capacities within a unified supernetwork, allowing a single model to dynamically adjust for efficient inference across different hardware. Finally, we develop Knowledge-Guided Distribution Matching Distillation, a step-distillation pipeline that integrates the DMD objective with knowledge transfer from few-step teacher models, producing high-fidelity and low-latency generation (e.g., 4-step) suitable for real-time on-device use. Together, these contributions enable scalable, efficient, and high-quality diffusion models for deployment on diverse hardware.
MF-VITON: High-Fidelity Mask-Free Virtual Try-On with Minimal Input
Mar 11, 2025Recent advancements in Virtual Try-On (VITON) have significantly improved image realism and garment detail preservation, driven by powerful text-to-image (T2I) diffusion models. However, existing methods often rely on user-provided masks, introducing complexity and performance degradation due to imperfect inputs, as shown in Fig.1(a). To address this, we propose a Mask-Free VITON (MF-VITON) framework that achieves realistic VITON using only a single person image and a target garment, eliminating the requirement for auxiliary masks. Our approach introduces a novel two-stage pipeline: (1) We leverage existing Mask-based VITON models to synthesize a high-quality dataset. This dataset contains diverse, realistic pairs of person images and corresponding garments, augmented with varied backgrounds to mimic real-world scenarios. (2) The pre-trained Mask-based model is fine-tuned on the generated dataset, enabling garment transfer without mask dependencies. This stage simplifies the input requirements while preserving garment texture and shape fidelity. Our framework achieves state-of-the-art (SOTA) performance regarding garment transfer accuracy and visual realism. Notably, the proposed Mask-Free model significantly outperforms existing Mask-based approaches, setting a new benchmark and demonstrating a substantial lead over previous approaches. For more details, visit our project page: https://zhenchenwan.github.io/MF-VITON/.
Uncertainty Quantification in Stereo Matching
Dec 24, 2024



Stereo matching plays a crucial role in various applications, where understanding uncertainty can enhance both safety and reliability. Despite this, the estimation and analysis of uncertainty in stereo matching have been largely overlooked. Previous works often provide limited interpretations of uncertainty and struggle to separate it effectively into data (aleatoric) and model (epistemic) components. This disentanglement is essential, as it allows for a clearer understanding of the underlying sources of error, enhancing both prediction confidence and decision-making processes. In this paper, we propose a new framework for stereo matching and its uncertainty quantification. We adopt Bayes risk as a measure of uncertainty and estimate data and model uncertainty separately. Experiments are conducted on four stereo benchmarks, and the results demonstrate that our method can estimate uncertainty accurately and efficiently. Furthermore, we apply our uncertainty method to improve prediction accuracy by selecting data points with small uncertainties, which reflects the accuracy of our estimated uncertainty. The codes are publicly available at https://github.com/RussRobin/Uncertainty.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
AniFaceDiff: High-Fidelity Face Reenactment via Facial Parametric Conditioned Diffusion Models
Jun 19, 2024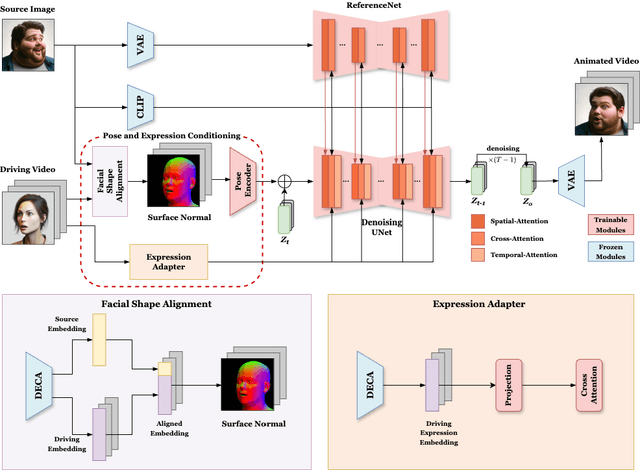
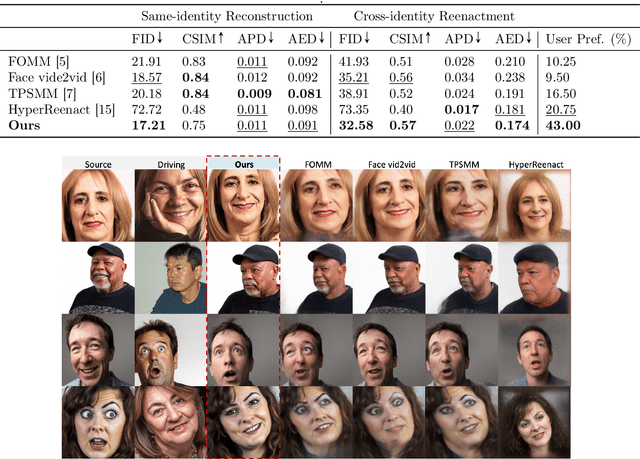
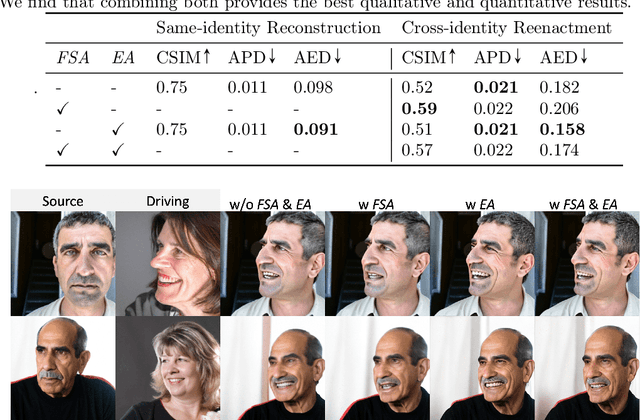

Face reenactment refers to the process of transferring the pose and facial expressions from a reference (driving) video onto a static facial (source) image while maintaining the original identity of the source image. Previous research in this domain has made significant progress by training controllable deep generative models to generate faces based on specific identity, pose and expression conditions. However, the mechanisms used in these methods to control pose and expression often inadvertently introduce identity information from the driving video, while also causing a loss of expression-related details. This paper proposes a new method based on Stable Diffusion, called AniFaceDiff, incorporating a new conditioning module for high-fidelity face reenactment. First, we propose an enhanced 2D facial snapshot conditioning approach by facial shape alignment to prevent the inclusion of identity information from the driving video. Then, we introduce an expression adapter conditioning mechanism to address the potential loss of expression-related information. Our approach effectively preserves pose and expression fidelity from the driving video while retaining the identity and fine details of the source image. Through experiments on the VoxCeleb dataset, we demonstrate that our method achieves state-of-the-art results in face reenactment, showcasing superior image quality, identity preservation, and expression accuracy, especially for cross-identity scenarios. Considering the ethical concerns surrounding potential misuse, we analyze the implications of our method, evaluate current state-of-the-art deepfake detectors, and identify their shortcomings to guide future research.
Stochastic Diffusion: A Diffusion Probabilistic Model for Stochastic Time Series Forecasting
Jun 05, 2024Recent innovations in diffusion probabilistic models have paved the way for significant progress in image, text and audio generation, leading to their applications in generative time series forecasting. However, leveraging such abilities to model highly stochastic time series data remains a challenge. In this paper, we propose a novel Stochastic Diffusion (StochDiff) model which learns data-driven prior knowledge at each time step by utilizing the representational power of the stochastic latent spaces to model the variability of the multivariate time series data. The learnt prior knowledge helps the model to capture complex temporal dynamics and the inherent uncertainty of the data. This improves its ability to model highly stochastic time series data. Through extensive experiments on real-world datasets, we demonstrate the effectiveness of our proposed model on stochastic time series forecasting. Additionally, we showcase an application of our model for real-world surgical guidance, highlighting its potential to benefit the medical community.
STBA: Towards Evaluating the Robustness of DNNs for Query-Limited Black-box Scenario
Mar 30, 2024



Many attack techniques have been proposed to explore the vulnerability of DNNs and further help to improve their robustness. Despite the significant progress made recently, existing black-box attack methods still suffer from unsatisfactory performance due to the vast number of queries needed to optimize desired perturbations. Besides, the other critical challenge is that adversarial examples built in a noise-adding manner are abnormal and struggle to successfully attack robust models, whose robustness is enhanced by adversarial training against small perturbations. There is no doubt that these two issues mentioned above will significantly increase the risk of exposure and result in a failure to dig deeply into the vulnerability of DNNs. Hence, it is necessary to evaluate DNNs' fragility sufficiently under query-limited settings in a non-additional way. In this paper, we propose the Spatial Transform Black-box Attack (STBA), a novel framework to craft formidable adversarial examples in the query-limited scenario. Specifically, STBA introduces a flow field to the high-frequency part of clean images to generate adversarial examples and adopts the following two processes to enhance their naturalness and significantly improve the query efficiency: a) we apply an estimated flow field to the high-frequency part of clean images to generate adversarial examples instead of introducing external noise to the benign image, and b) we leverage an efficient gradient estimation method based on a batch of samples to optimize such an ideal flow field under query-limited settings. Compared to existing score-based black-box baselines, extensive experiments indicated that STBA could effectively improve the imperceptibility of the adversarial examples and remarkably boost the attack success rate under query-limited settings.
Multiscale Representation for Real-Time Anti-Aliasing Neural Rendering
Apr 20, 2023



The rendering scheme in neural radiance field (NeRF) is effective in rendering a pixel by casting a ray into the scene. However, NeRF yields blurred rendering results when the training images are captured at non-uniform scales, and produces aliasing artifacts if the test images are taken in distant views. To address this issue, Mip-NeRF proposes a multiscale representation as a conical frustum to encode scale information. Nevertheless, this approach is only suitable for offline rendering since it relies on integrated positional encoding (IPE) to query a multilayer perceptron (MLP). To overcome this limitation, we propose mip voxel grids (Mip-VoG), an explicit multiscale representation with a deferred architecture for real-time anti-aliasing rendering. Our approach includes a density Mip-VoG for scene geometry and a feature Mip-VoG with a small MLP for view-dependent color. Mip-VoG encodes scene scale using the level of detail (LOD) derived from ray differentials and uses quadrilinear interpolation to map a queried 3D location to its features and density from two neighboring downsampled voxel grids. To our knowledge, our approach is the first to offer multiscale training and real-time anti-aliasing rendering simultaneously. We conducted experiments on multiscale datasets, and the results show that our approach outperforms state-of-the-art real-time rendering baselines.