 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-Fuzz: Finding Memory Errors in Deep Learning Frameworks
Feb 13, 2026GPU memory errors are a critical threat to deep learning (DL) frameworks, leading to crashes or even security issues. We introduce GPU-Fuzz, a fuzzer locating these issues efficiently by modeling operator parameters as formal constraints. GPU-Fuzz utilizes a constraint solver to generate test cases that systematically probe error-prone boundary conditions in GPU kernels. Applied to PyTorch, TensorFlow, and PaddlePaddle, we uncovered 13 unknown bugs, demonstrating the effectiveness of GPU-Fuzz in finding memory errors.
Improving Denoising Diffusion Models via Simultaneous Estimation of Image and Noise
Oct 26, 2023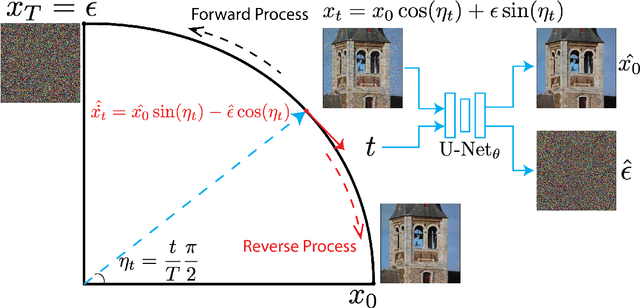

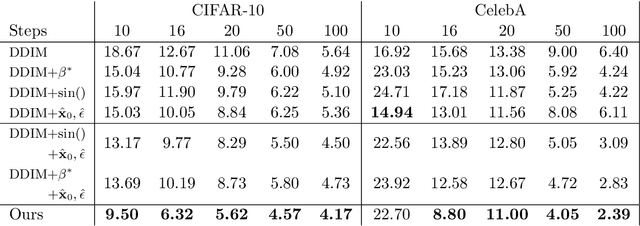
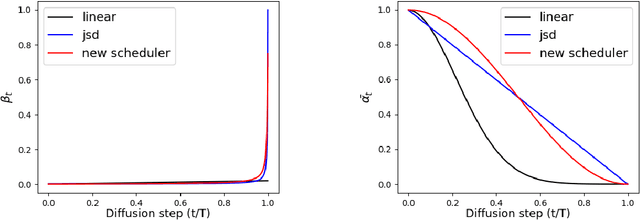
This paper introduces two key contributions aimed at improving the speed and quality of images generated through inverse diffusion processes. The first contribution involves reparameterizing the diffusion process in terms of the angle on a quarter-circular arc between the image and noise, specifically setting the conventional $\displaystyle \sqrt{\bar{\alpha}}=\cos(\eta)$. This reparameterization eliminates two singularities and allows for the expression of diffusion evolution as a well-behaved ordinary differential equation (ODE). In turn, this allows higher order ODE solvers such as Runge-Kutta methods to be used effectively. The second contribution is to directly estimate both the image ($\mathbf{x}_0$) and noise ($\mathbf{\epsilon}$) using our network, which enables more stable calculations of the update step in the inverse diffusion steps, as accurate estimation of both the image and noise are crucial at different stages of the process. Together with these changes, our model achieves faster generation, with the ability to converge on high-quality images more quickly, and higher quality of the generated images, as measured by metrics such as Frechet Inception Distance (FID), spatial Frechet Inception Distance (sFID), precision, and recall.
Multiscale Representation for Real-Time Anti-Aliasing Neural Rendering
Apr 20, 2023



The rendering scheme in neural radiance field (NeRF) is effective in rendering a pixel by casting a ray into the scene. However, NeRF yields blurred rendering results when the training images are captured at non-uniform scales, and produces aliasing artifacts if the test images are taken in distant views. To address this issue, Mip-NeRF proposes a multiscale representation as a conical frustum to encode scale information. Nevertheless, this approach is only suitable for offline rendering since it relies on integrated positional encoding (IPE) to query a multilayer perceptron (MLP). To overcome this limitation, we propose mip voxel grids (Mip-VoG), an explicit multiscale representation with a deferred architecture for real-time anti-aliasing rendering. Our approach includes a density Mip-VoG for scene geometry and a feature Mip-VoG with a small MLP for view-dependent color. Mip-VoG encodes scene scale using the level of detail (LOD) derived from ray differentials and uses quadrilinear interpolation to map a queried 3D location to its features and density from two neighboring downsampled voxel grids. To our knowledge, our approach is the first to offer multiscale training and real-time anti-aliasing rendering simultaneously. We conducted experiments on multiscale datasets, and the results show that our approach outperforms state-of-the-art real-time rendering baselines.
Open Set Recognition using Vision Transformer with an Additional Detection Head
Mar 16, 2022

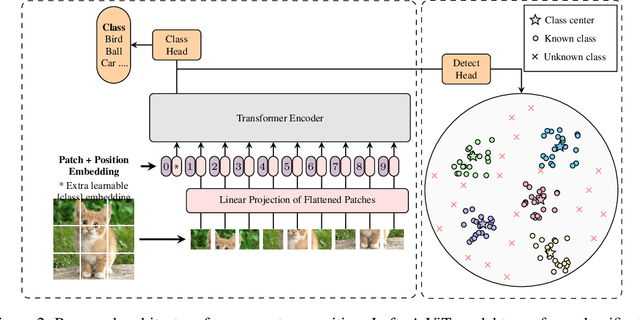

Deep neural networks have demonstrated prominent capacities for image classification tasks in a closed set setting, where the test data come from the same distribution as the training data. However, in a more realistic open set scenario, traditional classifiers with incomplete knowledge cannot tackle test data that are not from the training classes. Open set recognition (OSR) aims to address this problem by both identifying unknown classes and distinguishing known classes simultaneously. In this paper, we propose a novel approach to OSR that is based on the vision transformer (ViT) technique. Specifically, our approach employs two separate training stages. First, a ViT model is trained to perform closed set classification. Then, an additional detection head is attached to the embedded features extracted by the ViT, trained to force the representations of known data to class-specific clusters compactly. Test examples are identified as known or unknown based on their distance to the cluster centers. To the best of our knowledge, this is the first time to leverage ViT for the purpose of OSR, and our extensive evaluation against several OSR benchmark datasets reveals that our approach significantly outperforms other baseline methods and obtains new state-of-the-art performance.