 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Red Agent Policy from Observations for Neurosymbolic Autonomous Cyber Agents
Jun 16, 2026With sophisticated cyber-attacks becoming increasingly prevalent, modern networks require intelligent autonomous cyber-defense agents trained via Reinforcement Learning (RL). These agents employ neurosymbolic approaches such as behavior trees with learning-enabled components (LECs) to learn, reason, adapt, and implement security rules while maintaining critical operations. However, these autonomous networks are partially observable systems, i.e., the cyber-attacker's (red agent's) actions are not observable, making it difficult for the defender to predict red actions, learn red policies, or assess the attacker's intrusion levels. To address this, we propose a Policy Learning Technique using imitation learning to learn policies for partially observable RL agents with discrete states and discrete actions. We apply this technique in an autonomous cyber environment to predict red agent's actions from network observations and defender actions. Integrated with a neurosymbolic cyber-defense agent, our method effectively handles different red policies and achieves high prediction accuracy across diverse simulated scenarios.
Reward Shaping and Action Masking for Compositional Tasks using Behavior Trees and LLMs
May 07, 2026Decomposing complex tasks into a sequence of simpler subtasks can improve learning efficiency for an autonomous agent. Reinforcement learning (RL) can be used to optimize agent policies to complete subtasks, but requires well-defined subtask rewards and benefits from action masking. Recent work uses large language models (LLMs) to automate reward shaping and action masking, however none of them fully address reactivity to subtask failure and modularity to varying objects for compositional tasks. To overcome these challenges, we develop masking reward behavior tree (MRBT), a symbolic structure used as a reactive and modular reward and action mask function. We design an MRBT template and derive logical specifications to construct and verify MRBTs for a sequence of object-interaction subtasks. Further, we develop an automated pipeline that uses an LLM to generate MRBTs robust to varying task objects, an SMT-solver to verify correctness of specifications, and a neurosymbolic RL loop to train agents on compositional tasks. Experiments demonstrate successful generation and refinement of five MRBTs, consistently improving training efficiency and task success rates over baselines and MRBTs without action masking. We further highlight three advantages of MRBTs: transferability, modularity, and verifiability.
Defining and Benchmarking a Data-Centric Design Space for Brain Graph Construction
Aug 17, 2025The construction of brain graphs from functional Magnetic Resonance Imaging (fMRI) data plays a crucial role in enabling graph machine learning for neuroimaging. However, current practices often rely on rigid pipelines that overlook critical data-centric choices in how brain graphs are constructed. In this work, we adopt a Data-Centric AI perspective and systematically define and benchmark a data-centric design space for brain graph construction, constrasting with primarily model-centric prior work. We organize this design space into three stages: temporal signal processing, topology extraction, and graph featurization. Our contributions lie less in novel components and more in evaluating how combinations of existing and modified techniques influence downstream performance. Specifically, we study high-amplitude BOLD signal filtering, sparsification and unification strategies for connectivity, alternative correlation metrics, and multi-view node and edge features, such as incorporating lagged dynamics. Experiments on the HCP1200 and ABIDE datasets show that thoughtful data-centric configurations consistently improve classification accuracy over standard pipelines. These findings highlight the critical role of upstream data decisions and underscore the importance of systematically exploring the data-centric design space for graph-based neuroimaging. Our code is available at https://github.com/GeQinwen/DataCentricBrainGraphs.
Learning Backbones: Sparsifying Graphs through Zero Forcing for Effective Graph-Based Learning
Feb 24, 2025This paper introduces a novel framework for graph sparsification that preserves the essential learning attributes of original graphs, improving computational efficiency and reducing complexity in learning algorithms. We refer to these sparse graphs as "learning backbones". Our approach leverages the zero-forcing (ZF) phenomenon, a dynamic process on graphs with applications in network control. The key idea is to generate a tree from the original graph that retains critical dynamical properties. By correlating these properties with learning attributes, we construct effective learning backbones. We evaluate the performance of our ZF-based backbones in graph classification tasks across eight datasets and six baseline models. The results demonstrate that our method outperforms existing techniques. Additionally, we explore extensions using node distance metrics to further enhance the framework's utility.
Resilient Peer-to-peer Learning based on Adaptive Aggregation
Jan 08, 2025


Collaborative learning in peer-to-peer networks offers the benefits of distributed learning while mitigating the risks associated with single points of failure inherent in centralized servers. However, adversarial workers pose potential threats by attempting to inject malicious information into the network. Thus, ensuring the resilience of peer-to-peer learning emerges as a pivotal research objective. The challenge is exacerbated in the presence of non-convex loss functions and non-iid data distributions. This paper introduces a resilient aggregation technique tailored for such scenarios, aimed at fostering similarity among peers' learning processes. The aggregation weights are determined through an optimization procedure, and use the loss function computed using the neighbor's models and individual private data, thereby addressing concerns regarding data privacy in distributed machine learning. Theoretical analysis demonstrates convergence of parameters with non-convex loss functions and non-iid data distributions. Empirical evaluations across three distinct machine learning tasks support the claims. The empirical findings, which encompass a range of diverse attack models, also demonstrate improved accuracy when compared to existing methodologies.
* 11 pages
Out-of-Distribution Detection for Neurosymbolic Autonomous Cyber Agents
Dec 03, 2024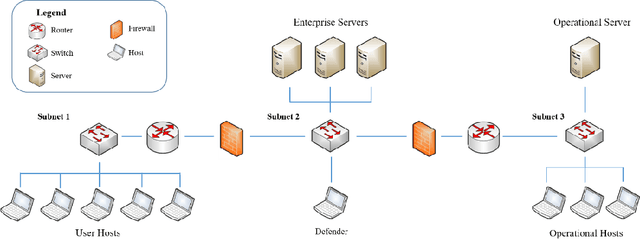
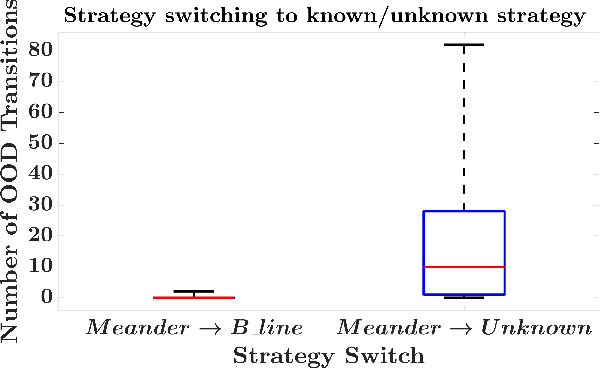

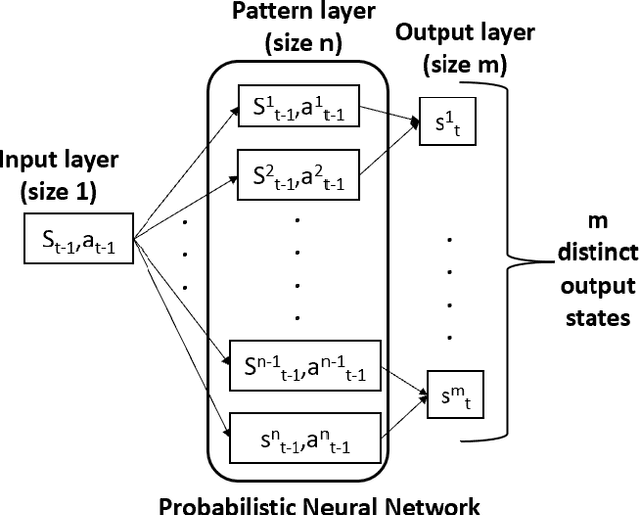
Autonomous agents for cyber applications take advantage of modern defense techniques by adopting intelligent agents with conventional and learning-enabled components. These intelligent agents are trained via reinforcement learning (RL) algorithms, and can learn, adapt to, reason about and deploy security rules to defend networked computer systems while maintaining critical operational workflows. However, the knowledge available during training about the state of the operational network and its environment may be limited. The agents should be trustworthy so that they can reliably detect situations they cannot handle, and hand them over to cyber experts. In this work, we develop an out-of-distribution (OOD) Monitoring algorithm that uses a Probabilistic Neural Network (PNN) to detect anomalous or OOD situations of RL-based agents with discrete states and discrete actions. To demonstrate the effectiveness of the proposed approach, we integrate the OOD monitoring algorithm with a neurosymbolic autonomous cyber agent that uses behavior trees with learning-enabled components. We evaluate the proposed approach in a simulated cyber environment under different adversarial strategies. Experimental results over a large number of episodes illustrate the overall efficiency of our proposed approach.
Shrinking POMCP: A Framework for Real-Time UAV Search and Rescue
Nov 20, 2024



Efficient path optimization for drones in search and rescue operations faces challenges, including limited visibility, time constraints, and complex information gathering in urban environments. We present a comprehensive approach to optimize UAV-based search and rescue operations in neighborhood areas, utilizing both a 3D AirSim-ROS2 simulator and a 2D simulator. The path planning problem is formulated as a partially observable Markov decision process (POMDP), and we propose a novel ``Shrinking POMCP'' approach to address time constraints. In the AirSim environment, we integrate our approach with a probabilistic world model for belief maintenance and a neurosymbolic navigator for obstacle avoidance. The 2D simulator employs surrogate ROS2 nodes with equivalent functionality. We compare trajectories generated by different approaches in the 2D simulator and evaluate performance across various belief types in the 3D AirSim-ROS simulator. Experimental results from both simulators demonstrate that our proposed shrinking POMCP solution achieves significant improvements in search times compared to alternative methods, showcasing its potential for enhancing the efficiency of UAV-assisted search and rescue operations.
Designing Robust Cyber-Defense Agents with Evolving Behavior Trees
Oct 21, 2024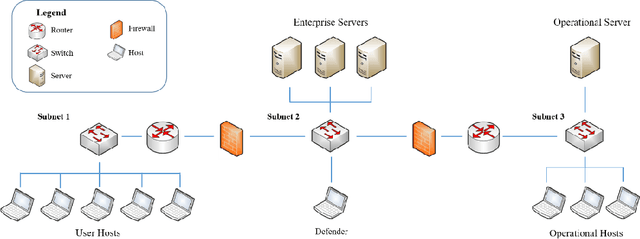
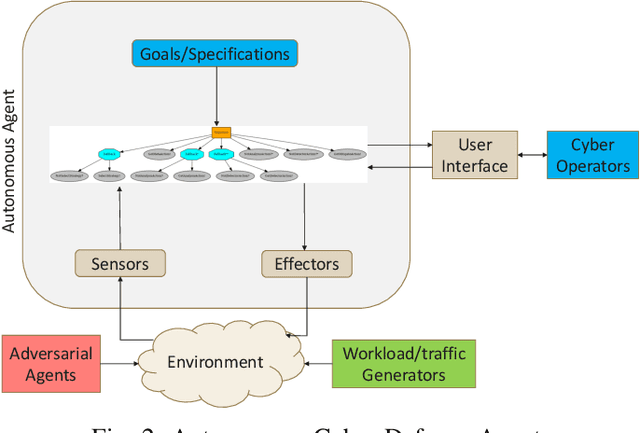
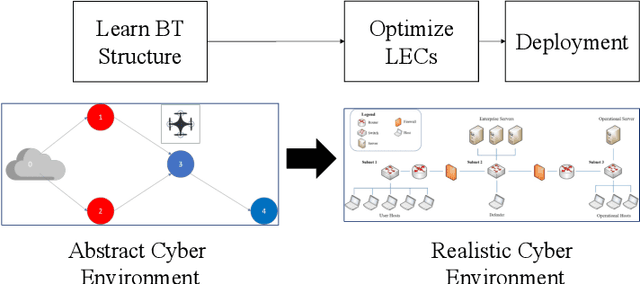

Modern network defense can benefit from the use of autonomous systems, offloading tedious and time-consuming work to agents with standard and learning-enabled components. These agents, operating on critical network infrastructure, need to be robust and trustworthy to ensure defense against adaptive cyber-attackers and, simultaneously, provide explanations for their actions and network activity. However, learning-enabled components typically use models, such as deep neural networks, that are not transparent in their high-level decision-making leading to assurance challenges. Additionally, cyber-defense agents must execute complex long-term defense tasks in a reactive manner that involve coordination of multiple interdependent subtasks. Behavior trees are known to be successful in modelling interpretable, reactive, and modular agent policies with learning-enabled components. In this paper, we develop an approach to design autonomous cyber defense agents using behavior trees with learning-enabled components, which we refer to as Evolving Behavior Trees (EBTs). We learn the structure of an EBT with a novel abstract cyber environment and optimize learning-enabled components for deployment. The learning-enabled components are optimized for adapting to various cyber-attacks and deploying security mechanisms. The learned EBT structure is evaluated in a simulated cyber environment, where it effectively mitigates threats and enhances network visibility. For deployment, we develop a software architecture for evaluating EBT-based agents in computer network defense scenarios. Our results demonstrate that the EBT-based agent is robust to adaptive cyber-attacks and provides high-level explanations for interpreting its decisions and actions.
A Property Encoder for Graph Neural Networks
Sep 17, 2024



Graph machine learning, particularly using graph neural networks, fundamentally relies on node features. Nevertheless, numerous real-world systems, such as social and biological networks, often lack node features due to various reasons, including privacy concerns, incomplete or missing data, and limitations in data collection. In such scenarios, researchers typically resort to methods like structural and positional encoding to construct node features. However, the length of such features is contingent on the maximum value within the property being encoded, for example, the highest node degree, which can be exceedingly large in applications like scale-free networks. Furthermore, these encoding schemes are limited to categorical data and might not be able to encode metrics returning other type of values. In this paper, we introduce a novel, universally applicable encoder, termed PropEnc, which constructs expressive node embedding from any given graph metric. PropEnc leverages histogram construction combined with reverse index encoding, offering a flexible method for node features initialization. It supports flexible encoding in terms of both dimensionality and type of input, demonstrating its effectiveness across diverse applications. PropEnc allows encoding metrics in low-dimensional space which effectively avoids the issue of sparsity and enhances the efficiency of the models. We show that \emph{PropEnc} can construct node features that either exactly replicate one-hot encoding or closely approximate indices under various settings. Our extensive evaluations in graph classification setting across multiple social networks that lack node features support our hypothesis. The empirical results conclusively demonstrate that PropEnc is both an efficient and effective mechanism for constructing node features from diverse set of graph metrics.
Improving Graph Machine Learning Performance Through Feature Augmentation Based on Network Control Theory
May 03, 2024Network control theory (NCT) offers a robust analytical framework for understanding the influence of network topology on dynamic behaviors, enabling researchers to decipher how certain patterns of external control measures can steer system dynamics towards desired states. Distinguished from other structure-function methodologies, NCT's predictive capabilities can be coupled with deploying Graph Neural Networks (GNNs), which have demonstrated exceptional utility in various network-based learning tasks. However, the performance of GNNs heavily relies on the expressiveness of node features, and the lack of node features can greatly degrade their performance. Furthermore, many real-world systems may lack node-level information, posing a challenge for GNNs.To tackle this challenge, we introduce a novel approach, NCT-based Enhanced Feature Augmentation (NCT-EFA), that assimilates average controllability, along with other centrality indices, into the feature augmentation pipeline to enhance GNNs performance. Our evaluation of NCT-EFA, on six benchmark GNN models across two experimental setting. solely employing average controllability and in combination with additional centrality metrics. showcases an improved performance reaching as high as 11%. Our results demonstrate that incorporating NCT into feature enrichment can substantively extend the applicability and heighten the performance of GNNs in scenarios where node-level information is unavailable.