 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized White Matter Bundle Segmentation for Early Childhood
Feb 04, 2026White matter segmentation methods from diffusion magnetic resonance imaging range from streamline clustering-based approaches to bundle mask delineation, but none have proposed a pediatric-specific approach. We hypothesize that a deep learning model with a similar approach to TractSeg will improve similarity between an algorithm-generated mask and an expert-labeled ground truth. Given a cohort of 56 manually labelled white matter bundles, we take inspiration from TractSeg's 2D UNet architecture, and we modify inputs to match bundle definitions as determined by pediatric experts, evaluation to use k fold cross validation, the loss function to masked Dice loss. We evaluate Dice score, volume overlap, and volume overreach of 16 major regions of interest compared to the expert labeled dataset. To test whether our approach offers statistically significant improvements over TractSeg, we compare Dice voxels, volume overlap, and adjacency voxels with a Wilcoxon signed rank test followed by false discovery rate correction. We find statistical significance across all bundles for all metrics with one exception in volume overlap. After we run TractSeg and our model, we combine their output masks into a 60 label atlas to evaluate if TractSeg and our model combined can generate a robust, individualized atlas, and observe smoothed, continuous masks in cases that TractSeg did not produce an anatomically plausible output. With the improvement of white matter pathway segmentation masks, we can further understand neurodevelopment on a population level scale, and we can produce reliable estimates of individualized anatomy in pediatric white matter diseases and disorders.
IntraStyler: Exemplar-based Style Synthesis for Cross-modality Domain Adaptation
Jan 01, 2026Image-level domain alignment is the de facto approach for unsupervised domain adaptation, where unpaired image translation is used to minimize the domain gap. Prior studies mainly focus on the domain shift between the source and target domains, whereas the intra-domain variability remains under-explored. To address the latter, an effective strategy is to diversify the styles of the synthetic target domain data during image translation. However, previous methods typically require intra-domain variations to be pre-specified for style synthesis, which may be impractical. In this paper, we propose an exemplar-based style synthesis method named IntraStyler, which can capture diverse intra-domain styles without any prior knowledge. Specifically, IntraStyler uses an exemplar image to guide the style synthesis such that the output style matches the exemplar style. To extract the style-only features, we introduce a style encoder to learn styles discriminatively based on contrastive learning. We evaluate the proposed method on the largest public dataset for cross-modality domain adaptation, CrossMoDA 2023. Our experiments show the efficacy of our method in controllable style synthesis and the benefits of diverse synthetic data for downstream segmentation. Code is available at https://github.com/han-liu/IntraStyler.
Fully Differentiable dMRI Streamline Propagation in PyTorch
Nov 17, 2025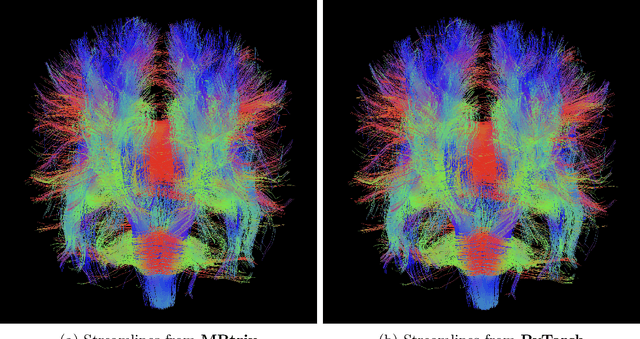



Diffusion MRI (dMRI) provides a distinctive means to probe the microstructural architecture of living tissue, facilitating applications such as brain connectivity analysis, modeling across multiple conditions, and the estimation of macrostructural features. Tractography, which emerged in the final years of the 20th century and accelerated in the early 21st century, is a technique for visualizing white matter pathways in the brain using dMRI. Most diffusion tractography methods rely on procedural streamline propagators or global energy minimization methods. Although recent advancements in deep learning have enabled tasks that were previously challenging, existing tractography approaches are often non-differentiable, limiting their integration in end-to-end learning frameworks. While progress has been made in representing streamlines in differentiable frameworks, no existing method offers fully differentiable propagation. In this work, we propose a fully differentiable solution that retains numerical fidelity with a leading streamline algorithm. The key is that our PyTorch-engineered streamline propagator has no components that block gradient flow, making it fully differentiable. We show that our method matches standard propagators while remaining differentiable. By translating streamline propagation into a differentiable PyTorch framework, we enable deeper integration of tractography into deep learning workflows, laying the foundation for a new category of macrostructural reasoning that is not only computationally robust but also scientifically rigorous.
Pedicle Screw Pairing and Registration for Screw Pose Estimation from Dual C-arm Images Using CAD Models
Nov 07, 2025Accurate matching of pedicle screws in both anteroposterior (AP) and lateral (LAT) images is critical for successful spinal decompression and stabilization during surgery. However, establishing screw correspondence, especially in LAT views, remains a significant clinical challenge. This paper introduces a method to address pedicle screw correspondence and pose estimation from dual C-arm images. By comparing screw combinations, the approach demonstrates consistent accuracy in both pairing and registration tasks. The method also employs 2D-3D alignment with screw CAD 3D models to accurately pair and estimate screw pose from dual views. Our results show that the correct screw combination consistently outperforms incorrect pairings across all test cases, even prior to registration. After registration, the correct combination further enhances alignment between projections and images, significantly reducing projection error. This approach shows promise for improving surgical outcomes in spinal procedures by providing reliable feedback on screw positioning.
2D/3D Registration of Acetabular Hip Implants Under Perspective Projection and Fully Differentiable Ellipse Fitting
Mar 10, 2025



This paper presents a novel method for estimating the orientation and the position of acetabular hip implants in total hip arthroplasty using full anterior-posterior hip fluoroscopy images. Our method accounts for distortions induced in the fluoroscope geometry, estimating acetabular component pose by creating a forward model of the perspective projection and implementing differentiable ellipse fitting for the similarity of our estimation from the ground truth. This approach enables precise estimation of the implant's rotation (anteversion, inclination) and the translation under the fluoroscope induced deformation. Experimental results from both numerically simulated and digitally reconstructed radiograph environments demonstrate high accuracy with minimal computational demands, offering enhanced precision and applicability in clinical and surgical settings.
Better Pose Initialization for Fast and Robust 2D/3D Pelvis Registration
Mar 10, 2025



This paper presents an approach for improving 2D/3D pelvis registration in optimization-based pose estimators using a learned initialization function. Current methods often fail to converge to the optimal solution when initialized naively. We find that even a coarse initializer greatly improves pose estimator accuracy, and improves overall computational efficiency. This approach proves to be effective also in challenging cases under more extreme pose variation. Experimental validation demonstrates that our method consistently achieves robust and accurate registration, enhancing the reliability of 2D/3D registration for clinical applications.
Scale-up Unlearnable Examples Learning with High-Performance Computing
Jan 10, 2025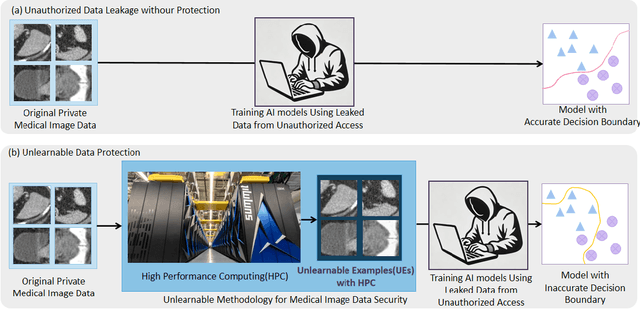
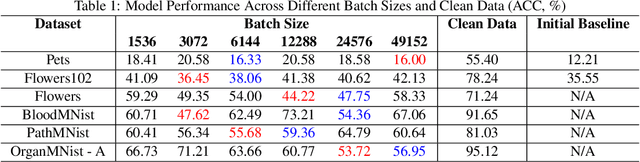
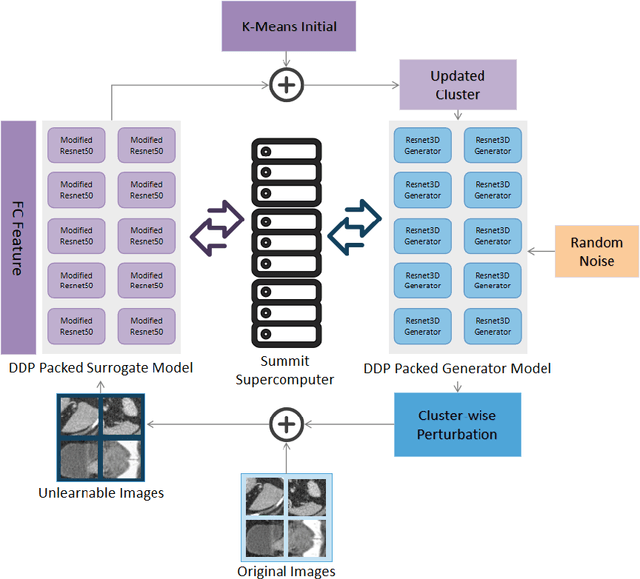
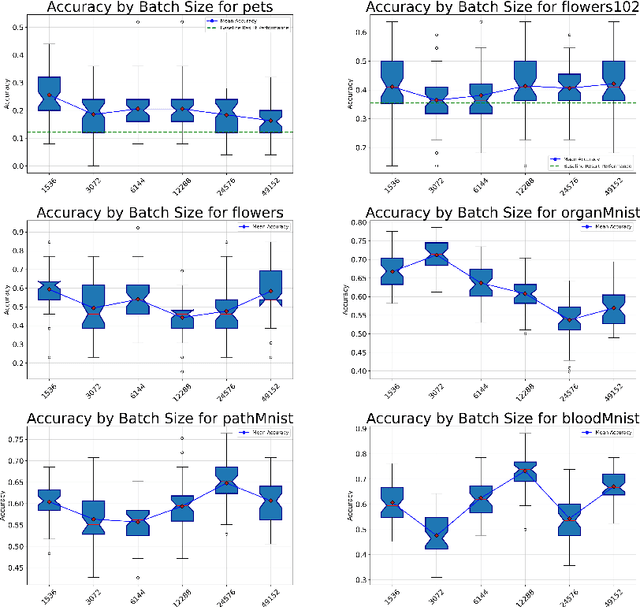
Recent advancements in AI models are structured to retain user interactions, which could inadvertently include sensitive healthcare data. In the healthcare field, particularly when radiologists use AI-driven diagnostic tools hosted on online platforms, there is a risk that medical imaging data may be repurposed for future AI training without explicit consent, spotlighting critical privacy and intellectual property concerns around healthcare data usage. Addressing these privacy challenges, a novel approach known as Unlearnable Examples (UEs) has been introduced, aiming to make data unlearnable to deep learning models. A prominent method within this area, called Unlearnable Clustering (UC), has shown improved UE performance with larger batch sizes but was previously limited by computational resources. To push the boundaries of UE performance with theoretically unlimited resources, we scaled up UC learning across various datasets using Distributed Data Parallel (DDP) training on the Summit supercomputer. Our goal was to examine UE efficacy at high-performance computing (HPC) levels to prevent unauthorized learning and enhance data security, particularly exploring the impact of batch size on UE's unlearnability. Utilizing the robust computational capabilities of the Summit, extensive experiments were conducted on diverse datasets such as Pets, MedMNist, Flowers, and Flowers102. Our findings reveal that both overly large and overly small batch sizes can lead to performance instability and affect accuracy. However, the relationship between batch size and unlearnability varied across datasets, highlighting the necessity for tailored batch size strategies to achieve optimal data protection. Our results underscore the critical role of selecting appropriate batch sizes based on the specific characteristics of each dataset to prevent learning and ensure data security in deep learning applications.
Training Noise Token Pruning
Nov 27, 2024



In the present work we present Training Noise Token (TNT) Pruning for vision transformers. Our method relaxes the discrete token dropping condition to continuous additive noise, providing smooth optimization in training, while retaining discrete dropping computational gains in deployment settings. We provide theoretical connections to Rate-Distortion literature, and empirical evaluations on the ImageNet dataset using ViT and DeiT architectures demonstrating TNT's advantages over previous pruning methods.
MICCAI-CDMRI 2023 QuantConn Challenge Findings on Achieving Robust Quantitative Connectivity through Harmonized Preprocessing of Diffusion MRI
Nov 14, 2024



White matter alterations are increasingly implicated in neurological diseases and their progression. International-scale studies use diffusion-weighted magnetic resonance imaging (DW-MRI) to qualitatively identify changes in white matter microstructure and connectivity. Yet, quantitative analysis of DW-MRI data is hindered by inconsistencies stemming from varying acquisition protocols. There is a pressing need to harmonize the preprocessing of DW-MRI datasets to ensure the derivation of robust quantitative diffusion metrics across acquisitions. In the MICCAI-CDMRI 2023 QuantConn challenge, participants were provided raw data from the same individuals collected on the same scanner but with two different acquisitions and tasked with preprocessing the DW-MRI to minimize acquisition differences while retaining biological variation. Submissions are evaluated on the reproducibility and comparability of cross-acquisition bundle-wise microstructure measures, bundle shape features, and connectomics. The key innovations of the QuantConn challenge are that (1) we assess bundles and tractography in the context of harmonization for the first time, (2) we assess connectomics in the context of harmonization for the first time, and (3) we have 10x additional subjects over prior harmonization challenge, MUSHAC and 100x over SuperMUDI. We find that bundle surface area, fractional anisotropy, connectome assortativity, betweenness centrality, edge count, modularity, nodal strength, and participation coefficient measures are most biased by acquisition and that machine learning voxel-wise correction, RISH mapping, and NeSH methods effectively reduce these biases. In addition, microstructure measures AD, MD, RD, bundle length, connectome density, efficiency, and path length are least biased by these acquisition differences.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2024/019
Brain age identification from diffusion MRI synergistically predicts neurodegenerative disease
Oct 29, 2024



Estimated brain age from magnetic resonance image (MRI) and its deviation from chronological age can provide early insights into potential neurodegenerative diseases, supporting early detection and implementation of prevention strategies. Diffusion MRI (dMRI), a widely used modality for brain age estimation, presents an opportunity to build an earlier biomarker for neurodegenerative disease prediction because it captures subtle microstructural changes that precede more perceptible macrostructural changes. However, the coexistence of macro- and micro-structural information in dMRI raises the question of whether current dMRI-based brain age estimation models are leveraging the intended microstructural information or if they inadvertently rely on the macrostructural information. To develop a microstructure-specific brain age, we propose a method for brain age identification from dMRI that minimizes the model's use of macrostructural information by non-rigidly registering all images to a standard template. Imaging data from 13,398 participants across 12 datasets were used for the training and evaluation. We compare our brain age models, trained with and without macrostructural information minimized, with an architecturally similar T1-weighted (T1w) MRI-based brain age model and two state-of-the-art T1w MRI-based brain age models that primarily use macrostructural information. We observe difference between our dMRI-based brain age and T1w MRI-based brain age across stages of neurodegeneration, with dMRI-based brain age being older than T1w MRI-based brain age in participants transitioning from cognitively normal (CN) to mild cognitive impairment (MCI), but younger in participants already diagnosed with Alzheimer's disease (AD). Approximately 4 years before MCI diagnosis, dMRI-based brain age yields better performance than T1w MRI-based brain ages in predicting transition from CN to MCI.