 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization and Memorization in Rectified Flow
Mar 12, 2026Generative models based on the Flow Matching objective, particularly Rectified Flow, have emerged as a dominant paradigm for efficient, high-fidelity image synthesis. However, while existing research heavily prioritizes generation quality and architectural scaling, the underlying dynamics of how RF models memorize training data remain largely underexplored. In this paper, we systematically investigate the memorization behaviors of RF through the test statistics of Membership Inference Attacks (MIA). We progressively formulate three test statistics, culminating in a complexity-calibrated metric ($T_\text{mc\_cal}$) that successfully decouples intrinsic image spatial complexity from genuine memorization signals. This calibration yields a significant performance surge -- boosting attack AUC by up to 15\% and the privacy-critical TPR@1\%FPR metric by up to 45\% -- establishing the first non-trivial MIA specifically tailored for RF. Leveraging these refined metrics, we uncover a distinct temporal pattern: under standard uniform temporal training, a model's susceptibility to MIA strictly peaks at the integration midpoint, a phenomenon we justify via the network's forced deviation from linear approximations. Finally, we demonstrate that substituting uniform timestep sampling with a Symmetric Exponential (U-shaped) distribution effectively minimizes exposure to vulnerable intermediate timesteps. Extensive evaluations across three datasets confirm that this temporal regularization suppresses memorization while preserving generative fidelity.
Training Noise Token Pruning
Nov 27, 2024



In the present work we present Training Noise Token (TNT) Pruning for vision transformers. Our method relaxes the discrete token dropping condition to continuous additive noise, providing smooth optimization in training, while retaining discrete dropping computational gains in deployment settings. We provide theoretical connections to Rate-Distortion literature, and empirical evaluations on the ImageNet dataset using ViT and DeiT architectures demonstrating TNT's advantages over previous pruning methods.
Zero-shot Prompt-based Video Encoder for Surgical Gesture Recognition
Mar 28, 2024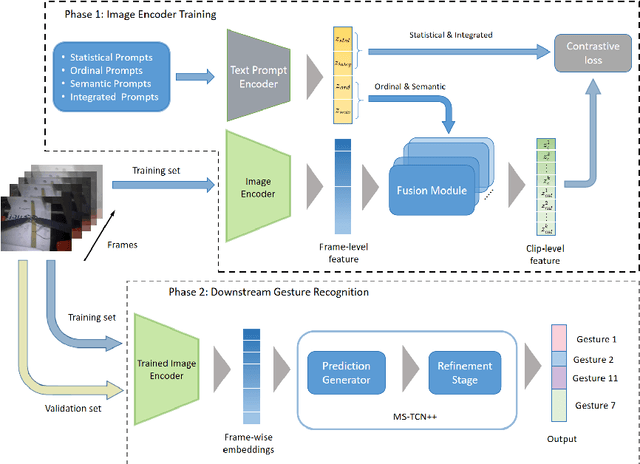



Purpose: Surgical video is an important data stream for gesture recognition. Thus, robust visual encoders for those data-streams is similarly important. Methods: Leveraging the Bridge-Prompt framework, we fine-tune a pre-trained vision-text model (CLIP) for gesture recognition in surgical videos. This can utilize extensive outside video data such as text, but also make use of label meta-data and weakly supervised contrastive losses. Results: Our experiments show that prompt-based video encoder outperforms standard encoders in surgical gesture recognition tasks. Notably, it displays strong performance in zero-shot scenarios, where gestures/tasks that were not provided during the encoder training phase are included in the prediction phase. Additionally, we measure the benefit of inclusion text descriptions in the feature extractor training schema. Conclusion: Bridge-Prompt and similar pre-trained+fine-tuned video encoder models present significant visual representation for surgical robotics, especially in gesture recognition tasks. Given the diverse range of surgical tasks (gestures), the ability of these models to zero-shot transfer without the need for any task (gesture) specific retraining makes them invaluable.