 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Depth in Surgical Vision Foundation Models: An Empirical Study of RGB-D Pre-training
Jan 26, 2026Vision foundation models (VFMs) have emerged as powerful tools for surgical scene understanding. However, current approaches predominantly rely on unimodal RGB pre-training, overlooking the complex 3D geometry inherent to surgical environments. Although several architectures support multimodal or geometry-aware inputs in general computer vision, the benefits of incorporating depth information in surgical settings remain underexplored. We conduct a large-scale empirical study comparing eight ViT-based VFMs that differ in pre-training domain, learning objective, and input modality (RGB vs. RGB-D). For pre-training, we use a curated dataset of 1.4 million robotic surgical images paired with depth maps generated from an off-the-shelf network. We evaluate these models under both frozen-backbone and end-to-end fine-tuning protocols across eight surgical datasets spanning object detection, segmentation, depth estimation, and pose estimation. Our experiments yield several consistent findings. Models incorporating explicit geometric tokenization, such as MultiMAE, substantially outperform unimodal baselines across all tasks. Notably, geometric-aware pre-training enables remarkable data efficiency: models fine-tuned on just 25% of labeled data consistently surpass RGB-only models trained on the full dataset. Importantly, these gains require no architectural or runtime changes at inference; depth is used only during pre-training, making adoption straightforward. These findings suggest that multimodal pre-training offers a viable path towards building more capable surgical vision systems.
A Supervised Autonomous Resection and Retraction Framework for Transurethral Enucleation of the Prostatic Median Lobe
Nov 11, 2025Concentric tube robots (CTRs) offer dexterous motion at millimeter scales, enabling minimally invasive procedures through natural orifices. This work presents a coordinated model-based resection planner and learning-based retraction network that work together to enable semi-autonomous tissue resection using a dual-arm transurethral concentric tube robot (the Virtuoso). The resection planner operates directly on segmented CT volumes of prostate phantoms, automatically generating tool trajectories for a three-phase median lobe resection workflow: left/median trough resection, right/median trough resection, and median blunt dissection. The retraction network, PushCVAE, trained on surgeon demonstrations, generates retractions according to the procedural phase. The procedure is executed under Level-3 (supervised) autonomy on a prostate phantom composed of hydrogel materials that replicate the mechanical and cutting properties of tissue. As a feasibility study, we demonstrate that our combined autonomous system achieves a 97.1% resection of the targeted volume of the median lobe. Our study establishes a foundation for image-guided autonomy in transurethral robotic surgery and represents a first step toward fully automated minimally-invasive prostate enucleation.
Neural-Augmented Kelvinlet: Real-Time Soft Tissue Deformation with Multiple Graspers
Jun 06, 2025Fast and accurate simulation of soft tissue deformation is a critical factor for surgical robotics and medical training. In this paper, we introduce a novel physics-informed neural simulator that approximates soft tissue deformations in a realistic and real-time manner. Our framework integrates Kelvinlet-based priors into neural simulators, making it the first approach to leverage Kelvinlets for residual learning and regularization in data-driven soft tissue modeling. By incorporating large-scale Finite Element Method (FEM) simulations of both linear and nonlinear soft tissue responses, our method improves neural network predictions across diverse architectures, enhancing accuracy and physical consistency while maintaining low latency for real-time performance. We demonstrate the effectiveness of our approach by performing accurate surgical maneuvers that simulate the use of standard laparoscopic tissue grasping tools with high fidelity. These results establish Kelvinlet-augmented learning as a powerful and efficient strategy for real-time, physics-aware soft tissue simulation in surgical applications.
From Monocular Vision to Autonomous Action: Guiding Tumor Resection via 3D Reconstruction
Mar 20, 2025Surgical automation requires precise guidance and understanding of the scene. Current methods in the literature rely on bulky depth cameras to create maps of the anatomy, however this does not translate well to space-limited clinical applications. Monocular cameras are small and allow minimally invasive surgeries in tight spaces but additional processing is required to generate 3D scene understanding. We propose a 3D mapping pipeline that uses only RGB images to create segmented point clouds of the target anatomy. To ensure the most precise reconstruction, we compare different structure from motion algorithms' performance on mapping the central airway obstructions, and test the pipeline on a downstream task of tumor resection. In several metrics, including post-procedure tissue model evaluation, our pipeline performs comparably to RGB-D cameras and, in some cases, even surpasses their performance. These promising results demonstrate that automation guidance can be achieved in minimally invasive procedures with monocular cameras. This study is a step toward the complete autonomy of surgical robots.
Multi-Modal Gesture Recognition from Video and Surgical Tool Pose Information via Motion Invariants
Mar 19, 2025Recognizing surgical gestures in real-time is a stepping stone towards automated activity recognition, skill assessment, intra-operative assistance, and eventually surgical automation. The current robotic surgical systems provide us with rich multi-modal data such as video and kinematics. While some recent works in multi-modal neural networks learn the relationships between vision and kinematics data, current approaches treat kinematics information as independent signals, with no underlying relation between tool-tip poses. However, instrument poses are geometrically related, and the underlying geometry can aid neural networks in learning gesture representation. Therefore, we propose combining motion invariant measures (curvature and torsion) with vision and kinematics data using a relational graph network to capture the underlying relations between different data streams. We show that gesture recognition improves when combining invariant signals with tool position, achieving 90.3\% frame-wise accuracy on the JIGSAWS suturing dataset. Our results show that motion invariant signals coupled with position are better representations of gesture motion compared to traditional position and quaternion representations. Our results highlight the need for geometric-aware modeling of kinematics for gesture recognition.
Sensorless Remote Center of Motion Misalignment Estimation
Mar 17, 2025

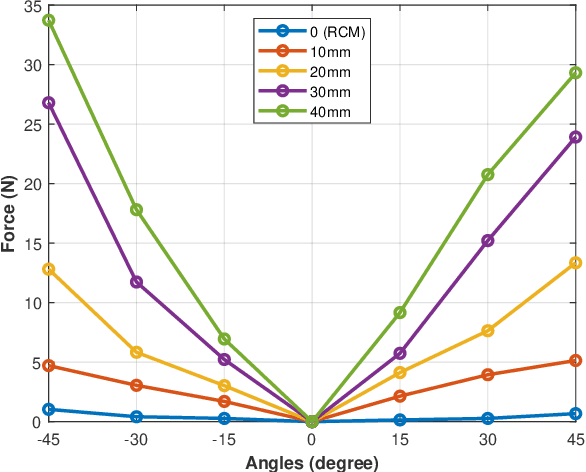

Laparoscopic surgery constrains instrument motion around a fixed pivot point at the incision into a patient to minimize tissue trauma. Surgical robots achieve this through either hardware to software-based remote center of motion (RCM) constraints. However, accurate RCM alignment is difficult due to manual trocar placement, patient motion, and tissue deformation. Misalignment between the robot's RCM point and the patient incision site can cause unsafe forces at the incision site. This paper presents a sensorless force estimation-based framework for dynamically assessing and optimizing RCM misalignment in robotic surgery. Our experiments demonstrate that misalignment exceeding 20 mm can generate large enough forces to potentially damage tissue, emphasizing the need for precise RCM positioning. For misalignment $D\geq $ 20 mm, our optimization algorithm estimates the RCM offset with an absolute error within 5 mm. Accurate RCM misalignment estimation is a step toward automated RCM misalignment compensation, enhancing safety and reducing tissue damage in robotic-assisted laparoscopic surgery.
Deformable Registration Framework for Augmented Reality-based Surgical Guidance in Head and Neck Tumor Resection
Mar 11, 2025Head and neck squamous cell carcinoma (HNSCC) has one of the highest rates of recurrence cases among solid malignancies. Recurrence rates can be reduced by improving positive margins localization. Frozen section analysis (FSA) of resected specimens is the gold standard for intraoperative margin assessment. However, because of the complex 3D anatomy and the significant shrinkage of resected specimens, accurate margin relocation from specimen back onto the resection site based on FSA results remains challenging. We propose a novel deformable registration framework that uses both the pre-resection upper surface and the post-resection site of the specimen to incorporate thickness information into the registration process. The proposed method significantly improves target registration error (TRE), demonstrating enhanced adaptability to thicker specimens. In tongue specimens, the proposed framework improved TRE by up to 33% as compared to prior deformable registration. Notably, tongue specimens exhibit complex 3D anatomies and hold the highest clinical significance compared to other head and neck specimens from the buccal and skin. We analyzed distinct deformation behaviors in different specimens, highlighting the need for tailored deformation strategies. To further aid intraoperative visualization, we also integrated this framework with an augmented reality-based auto-alignment system. The combined system can accurately and automatically overlay the deformed 3D specimen mesh with positive margin annotation onto the resection site. With a pilot study of the AR guided framework involving two surgeons, the integrated system improved the surgeons' average target relocation error from 9.8 cm to 4.8 cm.
EndoPBR: Material and Lighting Estimation for Photorealistic Surgical Simulations via Physically-based Rendering
Feb 28, 2025The lack of labeled datasets in 3D vision for surgical scenes inhibits the development of robust 3D reconstruction algorithms in the medical domain. Despite the popularity of Neural Radiance Fields and 3D Gaussian Splatting in the general computer vision community, these systems have yet to find consistent success in surgical scenes due to challenges such as non-stationary lighting and non-Lambertian surfaces. As a result, the need for labeled surgical datasets continues to grow. In this work, we introduce a differentiable rendering framework for material and lighting estimation from endoscopic images and known geometry. Compared to previous approaches that model lighting and material jointly as radiance, we explicitly disentangle these scene properties for robust and photorealistic novel view synthesis. To disambiguate the training process, we formulate domain-specific properties inherent in surgical scenes. Specifically, we model the scene lighting as a simple spotlight and material properties as a bidirectional reflectance distribution function, parameterized by a neural network. By grounding color predictions in the rendering equation, we can generate photorealistic images at arbitrary camera poses. We evaluate our method with various sequences from the Colonoscopy 3D Video Dataset and show that our method produces competitive novel view synthesis results compared with other approaches. Furthermore, we demonstrate that synthetic data can be used to develop 3D vision algorithms by finetuning a depth estimation model with our rendered outputs. Overall, we see that the depth estimation performance is on par with fine-tuning with the original real images.
Gravity Compensation of the dVRK-Si Patient Side Manipulator based on Dynamic Model Identification
Jan 31, 2025The da Vinci Research Kit (dVRK, also known as dVRK Classic) is an open-source teleoperated surgical robotic system whose hardware is obtained from the first generation da Vinci Surgical System (Intuitive, Sunnyvale, CA, USA). The dVRK has greatly facilitated research in robot-assisted surgery over the past decade and helped researchers address multiple major challenges in this domain. Recently, the dVRK-Si system, a new version of the dVRK which uses mechanical components from the da Vinci Si Surgical System, became available to the community. The major difference between the first generation da Vinci and the da Vinci Si is in the structural upgrade of the Patient Side Manipulator (PSM). Because of this upgrade, the gravity of the dVRK-Si PSM can no longer be ignored as in the dVRK Classic. The high gravity offset may lead to relatively low control accuracy and longer response time. In addition, although substantial progress has been made in addressing the dynamic model identification problem for the dVRK Classic, further research is required on model-based control for the dVRK-Si, due to differences in mechanical components and the demand for enhanced control performance. To address these problems, in this work, we present (1) a novel full kinematic model of the dVRK-Si PSM, and (2) a gravity compensation approach based on the dynamic model identification.
A Hybrid Model and Learning-Based Force Estimation Framework for Surgical Robots
Sep 30, 2024



Haptic feedback to the surgeon during robotic surgery would enable safer and more immersive surgeries but estimating tissue interaction forces at the tips of robotically controlled surgical instruments has proven challenging. Few existing surgical robots can measure interaction forces directly and the additional sensor may limit the life of instruments. We present a hybrid model and learning-based framework for force estimation for the Patient Side Manipulators (PSM) of a da Vinci Research Kit (dVRK). The model-based component identifies the dynamic parameters of the robot and estimates free-space joint torque, while the learning-based component compensates for environmental factors, such as the additional torque caused by trocar interaction between the PSM instrument and the patient's body wall. We evaluate our method in an abdominal phantom and achieve an error in force estimation of under 10% normalized root-mean-squared error. We show that by using a model-based method to perform dynamics identification, we reduce reliance on the training data covering the entire workspace. Although originally developed for the dVRK, the proposed method is a generalizable framework for other compliant surgical robots. The code is available at https://github.com/vu-maple-lab/dvrk_force_estimation.