 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUNA: Linear Universal Neural Attention with Generalization Guarantees
Dec 08, 2025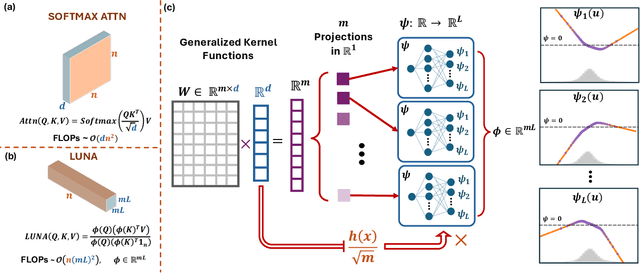
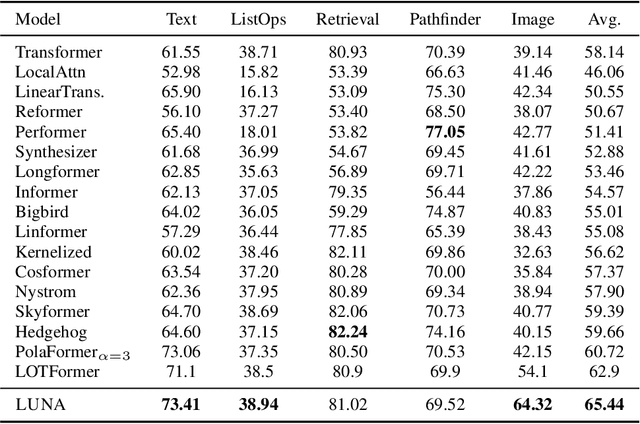
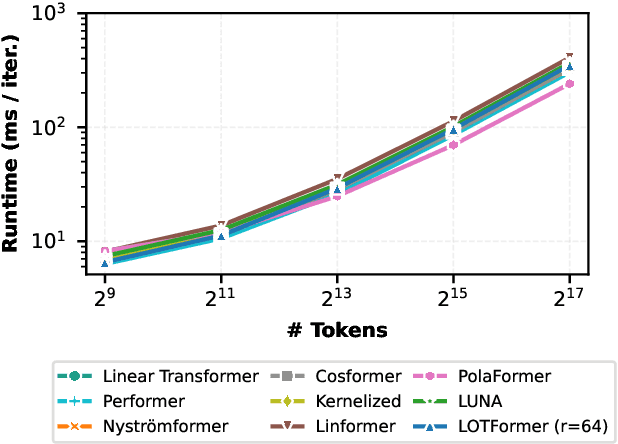
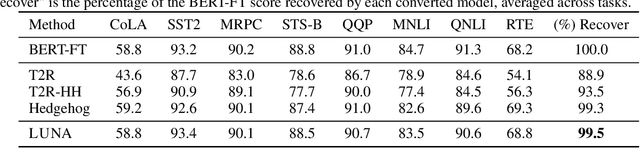
Scaling attention faces a critical bottleneck: the $\mathcal{O}(n^2)$ quadratic computational cost of softmax attention, which limits its application in long-sequence domains. While linear attention mechanisms reduce this cost to $\mathcal{O}(n)$, they typically rely on fixed random feature maps, such as random Fourier features or hand-crafted functions. This reliance on static, data-agnostic kernels creates a fundamental trade-off, forcing practitioners to sacrifice significant model accuracy for computational efficiency. We introduce \textsc{LUNA}, a kernelized linear attention mechanism that eliminates this trade-off, retaining linear cost while matching and surpassing the accuracy of quadratic attention. \textsc{LUNA} is built on the key insight that the kernel feature map itself should be learned rather than fixed a priori. By parameterizing the kernel, \textsc{LUNA} learns a feature basis tailored to the specific data and task, overcoming the expressive limitations of fixed-feature methods. \textsc{Luna} implements this with a learnable feature map that induces a positive-definite kernel and admits a streaming form, yielding linear time and memory scaling in the sequence length. Empirical evaluations validate our approach across diverse settings. On the Long Range Arena (LRA), \textsc{Luna} achieves state-of-the-art average accuracy among efficient Transformers under compute parity, using the same parameter count, training steps, and approximate FLOPs. \textsc{Luna} also excels at post-hoc conversion: replacing softmax in fine-tuned BERT and ViT-B/16 checkpoints and briefly fine-tuning recovers most of the original performance, substantially outperforming fixed linearizations.
Neural-Augmented Kelvinlet: Real-Time Soft Tissue Deformation with Multiple Graspers
Jun 06, 2025Fast and accurate simulation of soft tissue deformation is a critical factor for surgical robotics and medical training. In this paper, we introduce a novel physics-informed neural simulator that approximates soft tissue deformations in a realistic and real-time manner. Our framework integrates Kelvinlet-based priors into neural simulators, making it the first approach to leverage Kelvinlets for residual learning and regularization in data-driven soft tissue modeling. By incorporating large-scale Finite Element Method (FEM) simulations of both linear and nonlinear soft tissue responses, our method improves neural network predictions across diverse architectures, enhancing accuracy and physical consistency while maintaining low latency for real-time performance. We demonstrate the effectiveness of our approach by performing accurate surgical maneuvers that simulate the use of standard laparoscopic tissue grasping tools with high fidelity. These results establish Kelvinlet-augmented learning as a powerful and efficient strategy for real-time, physics-aware soft tissue simulation in surgical applications.
ESPFormer: Doubly-Stochastic Attention with Expected Sliced Transport Plans
Feb 11, 2025While self-attention has been instrumental in the success of Transformers, it can lead to over-concentration on a few tokens during training, resulting in suboptimal information flow. Enforcing doubly-stochastic constraints in attention matrices has been shown to improve structure and balance in attention distributions. However, existing methods rely on iterative Sinkhorn normalization, which is computationally costly. In this paper, we introduce a novel, fully parallelizable doubly-stochastic attention mechanism based on sliced optimal transport, leveraging Expected Sliced Transport Plans (ESP). Unlike prior approaches, our method enforces double stochasticity without iterative Sinkhorn normalization, significantly enhancing efficiency. To ensure differentiability, we incorporate a temperature-based soft sorting technique, enabling seamless integration into deep learning models. Experiments across multiple benchmark datasets, including image classification, point cloud classification, sentiment analysis, and neural machine translation, demonstrate that our enhanced attention regularization consistently improves performance across diverse applications.
Understanding Learning with Sliced-Wasserstein Requires Rethinking Informative Slices
Nov 16, 2024The practical applications of Wasserstein distances (WDs) are constrained by their sample and computational complexities. Sliced-Wasserstein distances (SWDs) provide a workaround by projecting distributions onto one-dimensional subspaces, leveraging the more efficient, closed-form WDs for one-dimensional distributions. However, in high dimensions, most random projections become uninformative due to the concentration of measure phenomenon. Although several SWD variants have been proposed to focus on \textit{informative} slices, they often introduce additional complexity, numerical instability, and compromise desirable theoretical (metric) properties of SWD. Amidst the growing literature that focuses on directly modifying the slicing distribution, which often face challenges, we revisit the classical Sliced-Wasserstein and propose instead to rescale the 1D Wasserstein to make all slices equally informative. Importantly, we show that with an appropriate data assumption and notion of \textit{slice informativeness}, rescaling for all individual slices simplifies to \textbf{a single global scaling factor} on the SWD. This, in turn, translates to the standard learning rate search for gradient-based learning in common machine learning workflows. We perform extensive experiments across various machine learning tasks showing that the classical SWD, when properly configured, can often match or surpass the performance of more complex variants. We then answer the following question: "Is Sliced-Wasserstein all you need for common learning tasks?"
Linear Spherical Sliced Optimal Transport: A Fast Metric for Comparing Spherical Data
Nov 09, 2024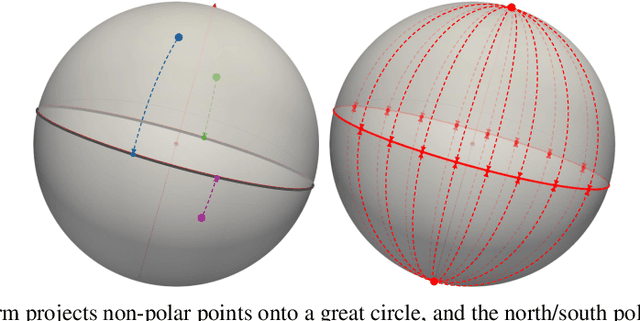
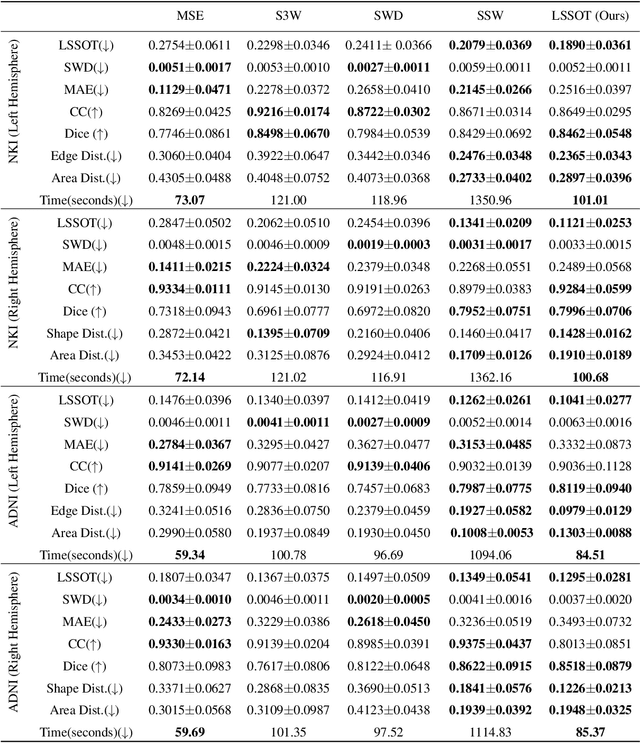
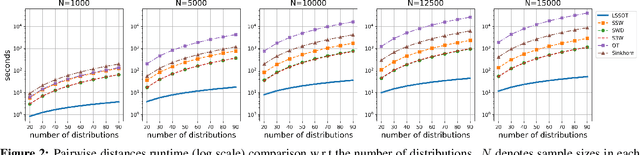
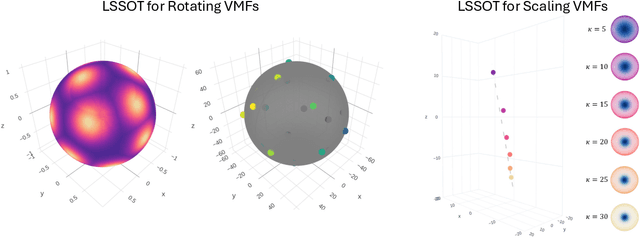
Efficient comparison of spherical probability distributions becomes important in fields such as computer vision, geosciences, and medicine. Sliced optimal transport distances, such as spherical and stereographic spherical sliced Wasserstein distances, have recently been developed to address this need. These methods reduce the computational burden of optimal transport by slicing hyperspheres into one-dimensional projections, i.e., lines or circles. Concurrently, linear optimal transport has been proposed to embed distributions into \( L^2 \) spaces, where the \( L^2 \) distance approximates the optimal transport distance, thereby simplifying comparisons across multiple distributions. In this work, we introduce the Linear Spherical Sliced Optimal Transport (LSSOT) framework, which utilizes slicing to embed spherical distributions into \( L^2 \) spaces while preserving their intrinsic geometry, offering a computationally efficient metric for spherical probability measures. We establish the metricity of LSSOT and demonstrate its superior computational efficiency in applications such as cortical surface registration, 3D point cloud interpolation via gradient flow, and shape embedding. Our results demonstrate the significant computational benefits and high accuracy of LSSOT in these applications.
Expected Sliced Transport Plans
Oct 17, 2024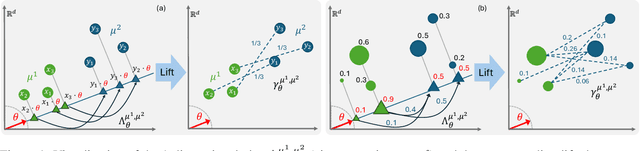
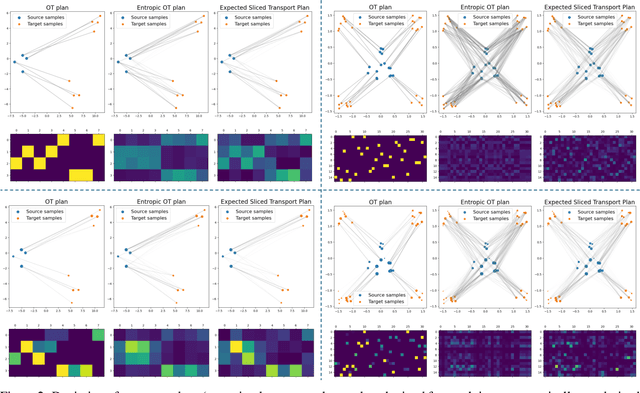
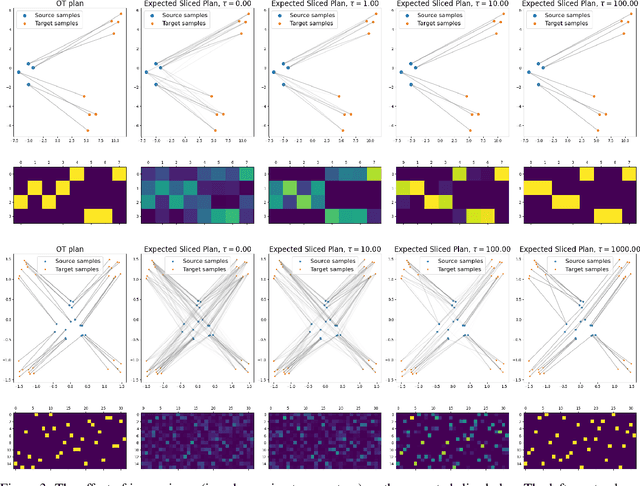

The optimal transport (OT) problem has gained significant traction in modern machine learning for its ability to: (1) provide versatile metrics, such as Wasserstein distances and their variants, and (2) determine optimal couplings between probability measures. To reduce the computational complexity of OT solvers, methods like entropic regularization and sliced optimal transport have been proposed. The sliced OT framework improves efficiency by comparing one-dimensional projections (slices) of high-dimensional distributions. However, despite their computational efficiency, sliced-Wasserstein approaches lack a transportation plan between the input measures, limiting their use in scenarios requiring explicit coupling. In this paper, we address two key questions: Can a transportation plan be constructed between two probability measures using the sliced transport framework? If so, can this plan be used to define a metric between the measures? We propose a "lifting" operation to extend one-dimensional optimal transport plans back to the original space of the measures. By computing the expectation of these lifted plans, we derive a new transportation plan, termed expected sliced transport (EST) plans. We prove that using the EST plan to weight the sum of the individual Euclidean costs for moving from one point to another results in a valid metric between the input discrete probability measures. We demonstrate the connection between our approach and the recently proposed min-SWGG, along with illustrative numerical examples that support our theoretical findings.
One Category One Prompt: Dataset Distillation using Diffusion Models
Mar 11, 2024



The extensive amounts of data required for training deep neural networks pose significant challenges on storage and transmission fronts. Dataset distillation has emerged as a promising technique to condense the information of massive datasets into a much smaller yet representative set of synthetic samples. However, traditional dataset distillation approaches often struggle to scale effectively with high-resolution images and more complex architectures due to the limitations in bi-level optimization. Recently, several works have proposed exploiting knowledge distillation with decoupled optimization schemes to scale up dataset distillation. Although these methods effectively address the scalability issue, they rely on extensive image augmentations requiring the storage of soft labels for augmented images. In this paper, we introduce Dataset Distillation using Diffusion Models (D3M) as a novel paradigm for dataset distillation, leveraging recent advancements in generative text-to-image foundation models. Our approach utilizes textual inversion, a technique for fine-tuning text-to-image generative models, to create concise and informative representations for large datasets. By employing these learned text prompts, we can efficiently store and infer new samples for introducing data variability within a fixed memory budget. We show the effectiveness of our method through extensive experiments across various computer vision benchmark datasets with different memory budgets.
Efficient Solvers for Partial Gromov-Wasserstein
Feb 06, 2024



The partial Gromov-Wasserstein (PGW) problem facilitates the comparison of measures with unequal masses residing in potentially distinct metric spaces, thereby enabling unbalanced and partial matching across these spaces. In this paper, we demonstrate that the PGW problem can be transformed into a variant of the Gromov-Wasserstein problem, akin to the conversion of the partial optimal transport problem into an optimal transport problem. This transformation leads to two new solvers, mathematically and computationally equivalent, based on the Frank-Wolfe algorithm, that provide efficient solutions to the PGW problem. We further establish that the PGW problem constitutes a metric for metric measure spaces. Finally, we validate the effectiveness of our proposed solvers in terms of computation time and performance on shape-matching and positive-unlabeled learning problems, comparing them against existing baselines.
Stereographic Spherical Sliced Wasserstein Distances
Feb 04, 2024



Comparing spherical probability distributions is of great interest in various fields, including geology, medical domains, computer vision, and deep representation learning. The utility of optimal transport-based distances, such as the Wasserstein distance, for comparing probability measures has spurred active research in developing computationally efficient variations of these distances for spherical probability measures. This paper introduces a high-speed and highly parallelizable distance for comparing spherical measures using the stereographic projection and the generalized Radon transform, which we refer to as the Stereographic Spherical Sliced Wasserstein (S3W) distance. We carefully address the distance distortion caused by the stereographic projection and provide an extensive theoretical analysis of our proposed metric and its rotationally invariant variation. Finally, we evaluate the performance of the proposed metrics and compare them with recent baselines in terms of both speed and accuracy through a wide range of numerical studies, including gradient flows and self-supervised learning.
Equivariant vs. Invariant Layers: A Comparison of Backbone and Pooling for Point Cloud Classification
Jun 08, 2023Learning from set-structured data, such as point clouds, has gained significant attention from the community. Geometric deep learning provides a blueprint for designing effective set neural networks by incorporating permutation symmetry. Of our interest are permutation invariant networks, which are composed of a permutation equivariant backbone, permutation invariant global pooling, and regression/classification head. While existing literature has focused on improving permutation equivariant backbones, the impact of global pooling is often overlooked. In this paper, we examine the interplay between permutation equivariant backbones and permutation invariant global pooling on three benchmark point cloud classification datasets. Our findings reveal that: 1) complex pooling methods, such as transport-based or attention-based poolings, can significantly boost the performance of simple backbones, but the benefits diminish for more complex backbones, 2) even complex backbones can benefit from pooling layers in low data scenarios, 3) surprisingly, the choice of pooling layers can have a more significant impact on the model's performance than adjusting the width and depth of the backbone, and 4) pairwise combination of pooling layers can significantly improve the performance of a fixed backbone. Our comprehensive study provides insights for practitioners to design better permutation invariant set neural networks.