 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPFormer: Doubly-Stochastic Attention with Expected Sliced Transport Plans
Feb 11, 2025While self-attention has been instrumental in the success of Transformers, it can lead to over-concentration on a few tokens during training, resulting in suboptimal information flow. Enforcing doubly-stochastic constraints in attention matrices has been shown to improve structure and balance in attention distributions. However, existing methods rely on iterative Sinkhorn normalization, which is computationally costly. In this paper, we introduce a novel, fully parallelizable doubly-stochastic attention mechanism based on sliced optimal transport, leveraging Expected Sliced Transport Plans (ESP). Unlike prior approaches, our method enforces double stochasticity without iterative Sinkhorn normalization, significantly enhancing efficiency. To ensure differentiability, we incorporate a temperature-based soft sorting technique, enabling seamless integration into deep learning models. Experiments across multiple benchmark datasets, including image classification, point cloud classification, sentiment analysis, and neural machine translation, demonstrate that our enhanced attention regularization consistently improves performance across diverse applications.
Wireless Link Scheduling via Graph Representation Learning: A Comparative Study of Different Supervision Levels
Oct 04, 2021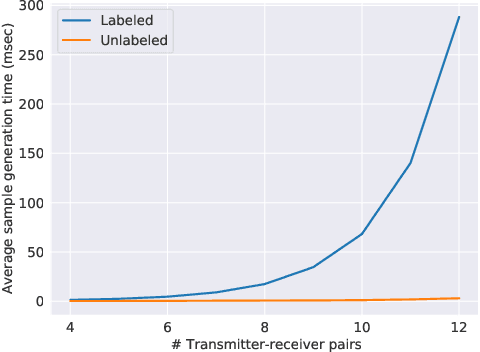

We consider the problem of binary power control, or link scheduling, in wireless interference networks, where the power control policy is trained using graph representation learning. We leverage the interference graph of the wireless network as an underlying topology for a graph neural network (GNN) backbone, which converts the channel matrix to a set of node embeddings for all transmitter-receiver pairs. We show how the node embeddings can be trained in several ways, including via supervised, unsupervised, and self-supervised learning, and we compare the impact of different supervision levels on the performance of these methods in terms of the system-level throughput, convergence behavior, sample efficiency, and generalization capability.
Set Representation Learning with Generalized Sliced-Wasserstein Embeddings
Mar 05, 2021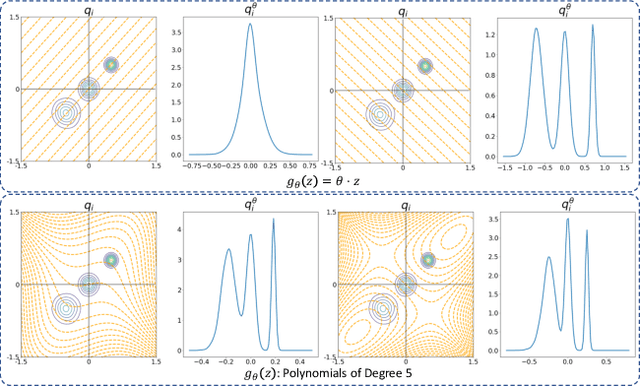

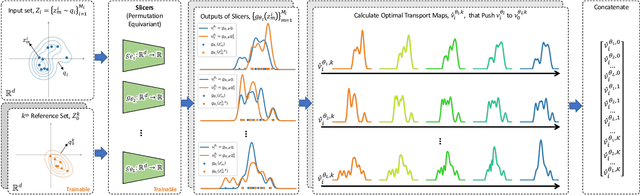
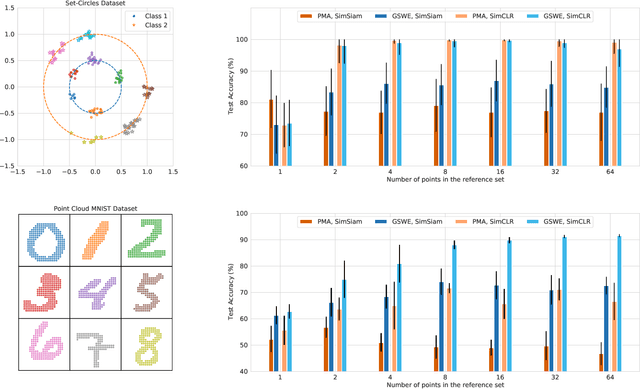
An increasing number of machine learning tasks deal with learning representations from set-structured data. Solutions to these problems involve the composition of permutation-equivariant modules (e.g., self-attention, or individual processing via feed-forward neural networks) and permutation-invariant modules (e.g., global average pooling, or pooling by multi-head attention). In this paper, we propose a geometrically-interpretable framework for learning representations from set-structured data, which is rooted in the optimal mass transportation problem. In particular, we treat elements of a set as samples from a probability measure and propose an exact Euclidean embedding for Generalized Sliced Wasserstein (GSW) distances to learn from set-structured data effectively. We evaluate our proposed framework on multiple supervised and unsupervised set learning tasks and demonstrate its superiority over state-of-the-art set representation learning approaches.
Contrastive Self-Supervised Learning for Wireless Power Control
Oct 22, 2020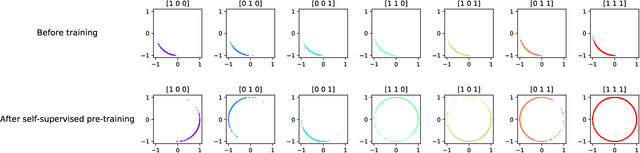
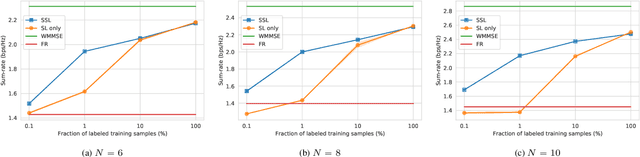
We propose a new approach for power control in wireless networks using self-supervised learning. We partition a multi-layer perceptron that takes as input the channel matrix and outputs the power control decisions into a backbone and a head, and we show how we can use contrastive learning to pre-train the backbone so that it produces similar embeddings at its output for similar channel matrices and vice versa, where similarity is defined in an information-theoretic sense by identifying the interference links that can be optimally treated as noise. The backbone and the head are then fine-tuned using a limited number of labeled samples. Simulation results show the effectiveness of the proposed approach, demonstrating significant gains over pure supervised learning methods in both sum-throughput and sample efficiency.
Graph Convolutional Value Decomposition in Multi-Agent Reinforcement Learning
Oct 09, 2020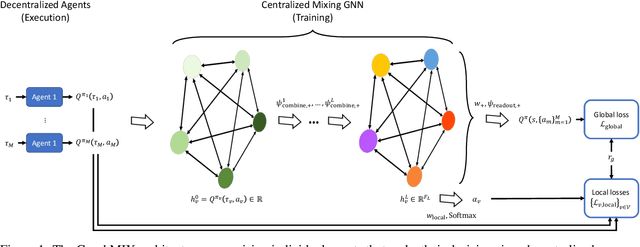


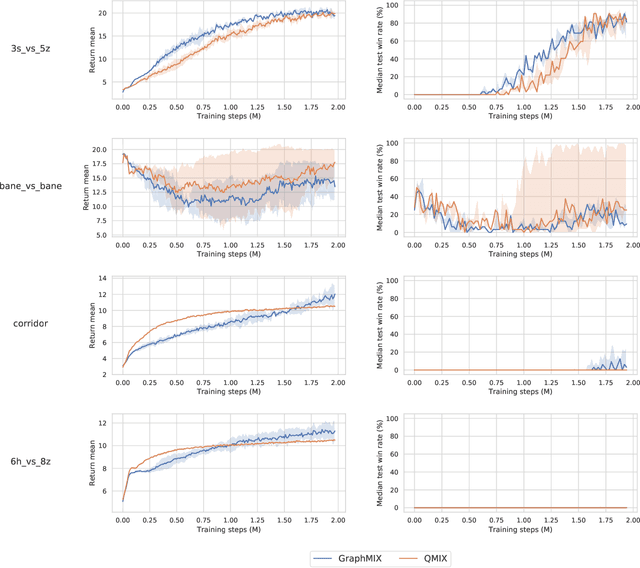
We propose a novel framework for value function factorization in multi-agent deep reinforcement learning using graph neural networks (GNNs). In particular, we consider the team of agents as the set of nodes of a complete directed graph, whose edge weights are governed by an attention mechanism. Building upon this underlying graph, we introduce a mixing GNN module, which is responsible for two tasks: i) factorizing the team state-action value function into individual per-agent observation-action value functions, and ii) explicit credit assignment to each agent in terms of fractions of the global team reward. Our approach, which we call GraphMIX, follows the centralized training and decentralized execution paradigm, enabling the agents to make their decisions independently once training is completed. Experimental results on the StarCraft II multi-agent challenge (SMAC) environment demonstrate the superiority of our proposed approach as compared to the state-of-the-art.
Wasserstein Embedding for Graph Learning
Jun 16, 2020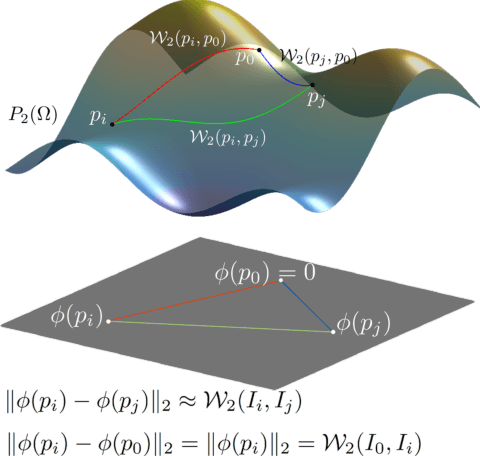
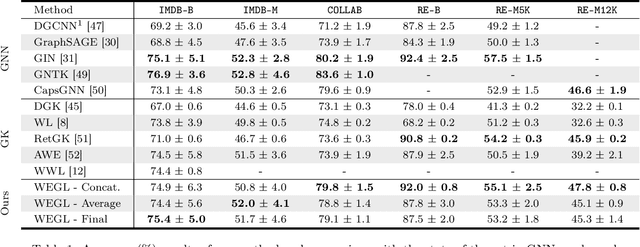
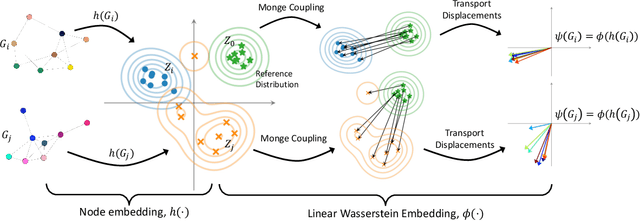
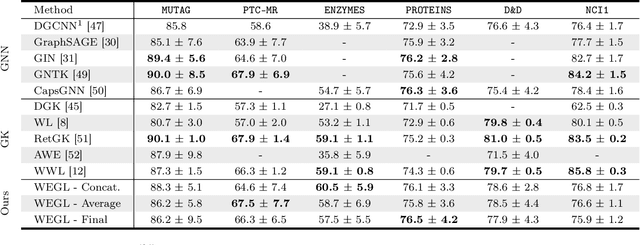
We present Wasserstein Embedding for Graph Learning (WEGL), a novel and fast framework for embedding entire graphs in a vector space, in which various machine learning models are applicable for graph-level prediction tasks. We leverage new insights on defining similarity between graphs as a function of the similarity between their node embedding distributions. Specifically, we use the Wasserstein distance to measure the dissimilarity between node embeddings of different graphs. Different from prior work, we avoid pairwise calculation of distances between graphs and reduce the computational complexity from quadratic to linear in the number of graphs. WEGL calculates Monge maps from a reference distribution to each node embedding and, based on these maps, creates a fixed-sized vector representation of the graph. We evaluate our new graph embedding approach on various benchmark graph-property prediction tasks, showing state-of-the-art classification performance, while having superior computational efficiency.
Wireless Power Control via Counterfactual Optimization of Graph Neural Networks
Feb 17, 2020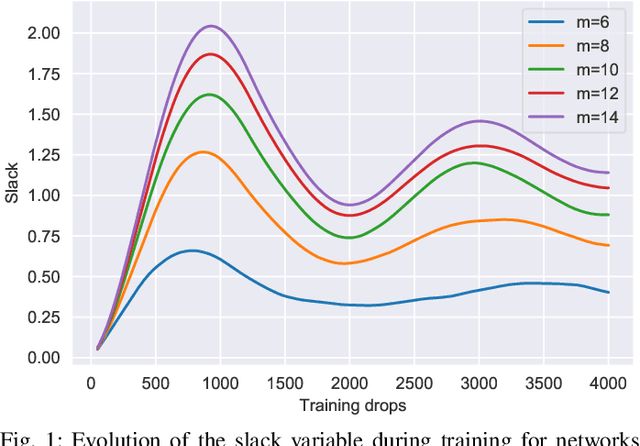
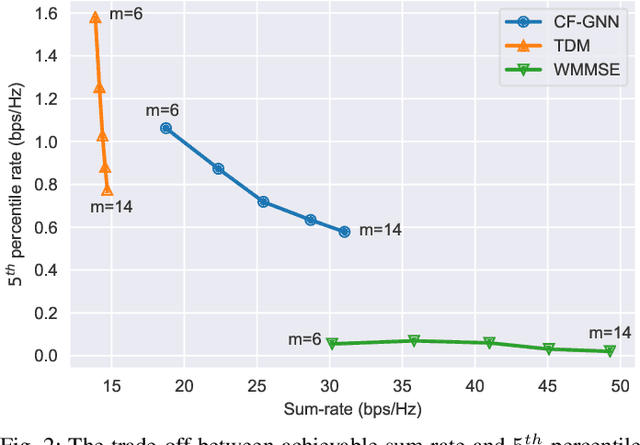
We consider the problem of downlink power control in wireless networks, consisting of multiple transmitter-receiver pairs communicating with each other over a single shared wireless medium. To mitigate the interference among concurrent transmissions, we leverage the network topology to create a graph neural network architecture, and we then use an unsupervised primal-dual counterfactual optimization approach to learn optimal power allocation decisions. We show how the counterfactual optimization technique allows us to guarantee a minimum rate constraint, which adapts to the network size, hence achieving the right balance between average and $5^{th}$ percentile user rates throughout a range of network configurations.
Resource Management in Wireless Networks via Multi-Agent Deep Reinforcement Learning
Feb 14, 2020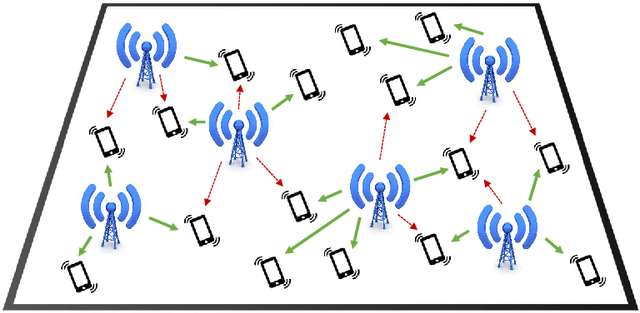
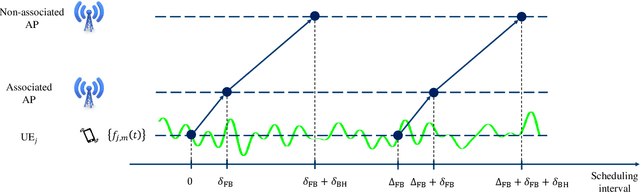
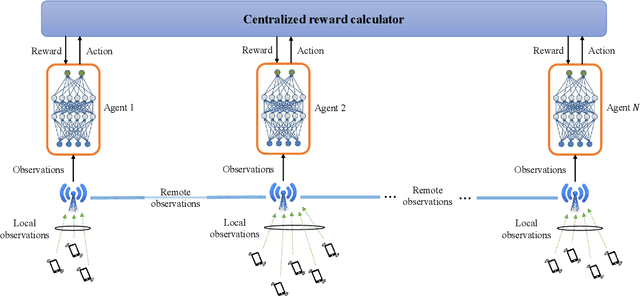
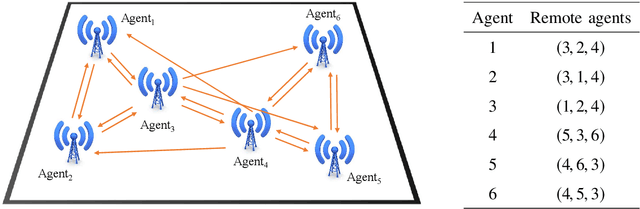
We propose a mechanism for distributed radio resource management using multi-agent deep reinforcement learning (RL) for interference mitigation in wireless networks. We equip each transmitter in the network with a deep RL agent, which receives partial delayed observations from its associated users, while also exchanging observations with its neighboring agents, and decides on which user to serve and what transmit power to use at each scheduling interval. Our proposed framework enables the agents to make decisions simultaneously and in a distributed manner, without any knowledge about the concurrent decisions of other agents. Moreover, our design of the agents' observation and action spaces is scalable, in the sense that an agent trained on a scenario with a specific number of transmitters and receivers can be readily applied to scenarios with different numbers of transmitters and/or receivers. Simulation results demonstrate the superiority of our proposed approach compared to decentralized baselines in terms of the tradeoff between average and $5^{th}$ percentile user rates, while achieving performance close to, and even in certain cases outperforming, that of a centralized information-theoretic scheduling algorithm. We also show that our trained agents are robust and maintain their performance gains when experiencing mismatches between training and testing deployments.
On the Communication Latency of Wireless Decentralized Learning
Feb 10, 2020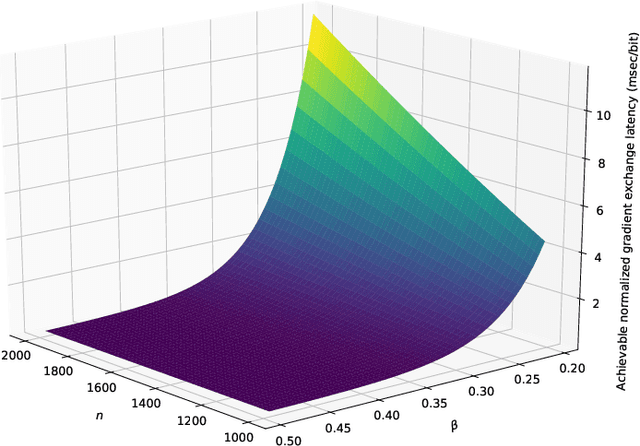
We consider a wireless network comprising $n$ nodes located within a circular area of radius $R$, which are participating in a decentralized learning algorithm to optimize a global objective function using their local datasets. To enable gradient exchanges across the network, we assume each node communicates only with a set of neighboring nodes, which are within a distance $R n^{-\beta}$ of itself, where $\beta\in(0,\frac{1}{2})$. We use tools from network information theory and random geometric graph theory to show that the communication delay for a single round of exchanging gradients on all the links throughout the network scales as $\mathcal{O}\left(\frac{n^{2-3\beta}}{\beta\log n}\right)$, increasing (at different rates) with both the number of nodes and the gradient exchange threshold distance.
Energy-Aware Multi-Server Mobile Edge Computing: A Deep Reinforcement Learning Approach
Dec 22, 2019

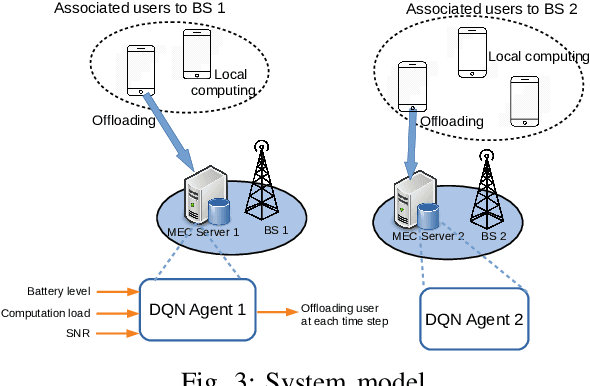
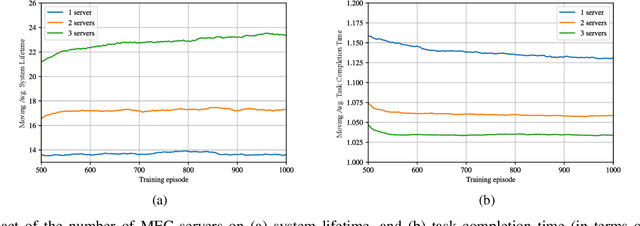
We investigate the problem of computation offloading in a mobile edge computing architecture, where multiple energy-constrained users compete to offload their computational tasks to multiple servers through a shared wireless medium. We propose a multi-agent deep reinforcement learning algorithm, where each server is equipped with an agent, observing the status of its associated users and selecting the best user for offloading at each step. We consider computation time (i.e., task completion time) and system lifetime as two key performance indicators, and we numerically demonstrate that our approach outperforms baseline algorithms in terms of the trade-off between computation time and system lifetime.