 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA State-Augmented Approach for Learning Optimal Resource Management Decisions in Wireless Networks
Nov 09, 2022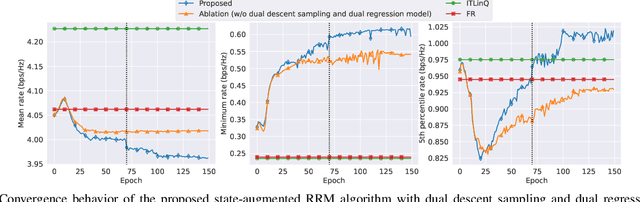
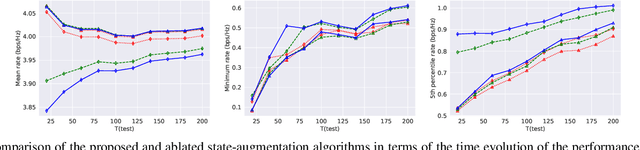
We consider a radio resource management (RRM) problem in a multi-user wireless network, where the goal is to optimize a network-wide utility function subject to constraints on the ergodic average performance of users. We propose a state-augmented parameterization for the RRM policy, where alongside the instantaneous network states, the RRM policy takes as input the set of dual variables corresponding to the constraints. We provide theoretical justification for the feasibility and near-optimality of the RRM decisions generated by the proposed state-augmented algorithm. Focusing on the power allocation problem with RRM policies parameterized by a graph neural network (GNN) and dual variables sampled from the dual descent dynamics, we numerically demonstrate that the proposed approach achieves a superior trade-off between mean, minimum, and 5th percentile rates than baseline methods.
State-Augmented Learnable Algorithms for Resource Management in Wireless Networks
Jul 05, 2022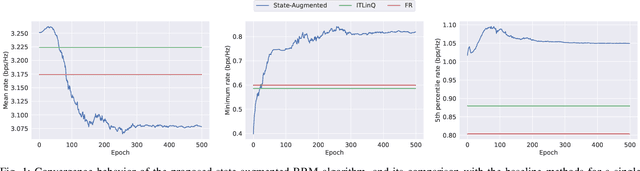
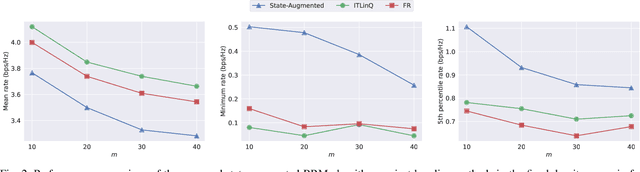
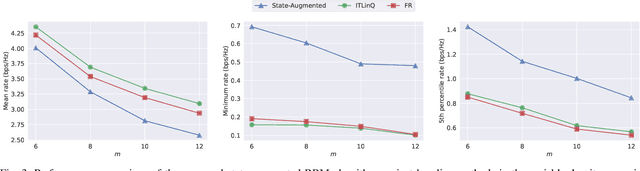
We consider resource management problems in multi-user wireless networks, which can be cast as optimizing a network-wide utility function, subject to constraints on the long-term average performance of users across the network. We propose a state-augmented algorithm for solving the aforementioned radio resource management (RRM) problems, where, alongside the instantaneous network state, the RRM policy takes as input the set of dual variables corresponding to the constraints, which evolve depending on how much the constraints are violated during execution. We theoretically show that the proposed state-augmented algorithm leads to feasible and near-optimal RRM decisions. Moreover, focusing on the problem of wireless power control using graph neural network (GNN) parameterizations, we demonstrate the superiority of the proposed RRM algorithm over baseline methods across a suite of numerical experiments.
Learning Resilient Radio Resource Management Policies with Graph Neural Networks
Mar 07, 2022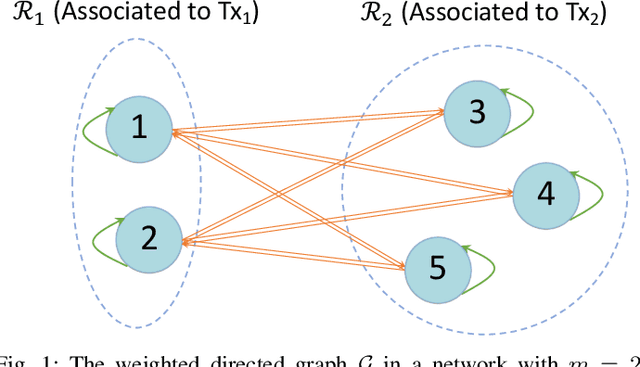
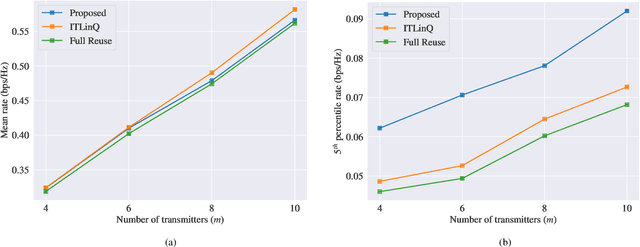
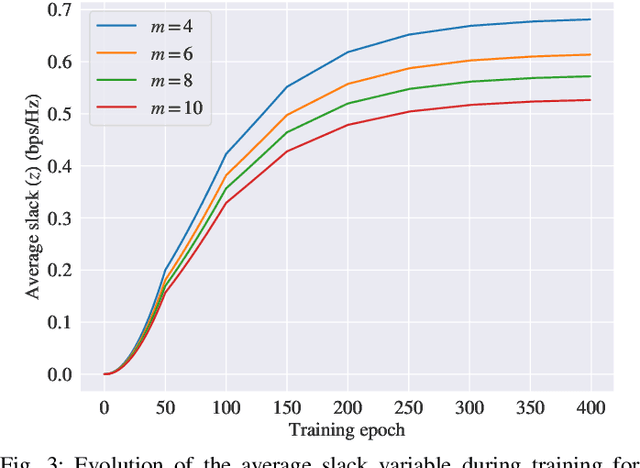
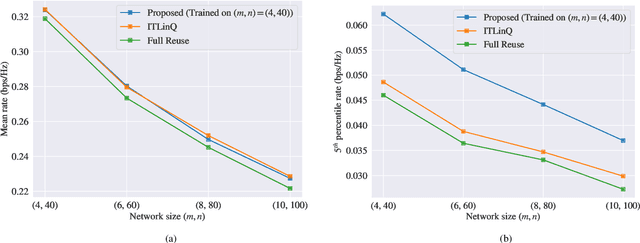
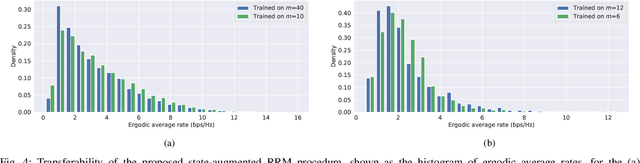
We consider the problems of downlink user selection and power control in wireless networks, comprising multiple transmitters and receivers communicating with each other over a shared wireless medium. To achieve a high aggregate rate, while ensuring fairness across all the receivers, we formulate a resilient radio resource management (RRM) policy optimization problem with per-user minimum-capacity constraints that adapt to the underlying network conditions via learnable slack variables. We reformulate the problem in the Lagrangian dual domain, and show that we can parameterize the user selection and power control policies using a finite set of parameters, which can be trained alongside the slack and dual variables via an unsupervised primal-dual approach thanks to a provably small duality gap. We use a scalable and permutation-equivariant graph neural network (GNN) architecture to parameterize the RRM policies based on a graph topology derived from the instantaneous channel conditions. Through experimental results, we verify that the minimum-capacity constraints adapt to the underlying network configurations and channel conditions. We further demonstrate that, thanks to such adaptation, our proposed method achieves a superior tradeoff between the average rate and the 5th percentile rate -- a metric that quantifies the level of fairness in the resource allocation decisions -- as compared to baseline algorithms.
Communication-Control Co-design in Wireless Edge Industrial Systems
Feb 08, 2022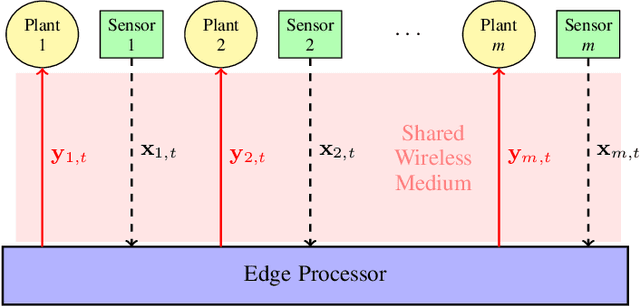
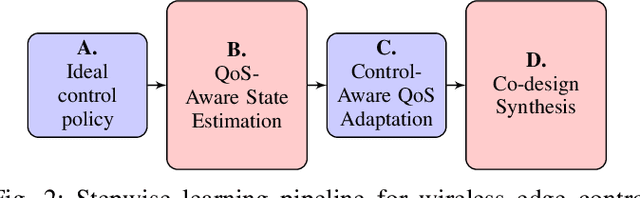

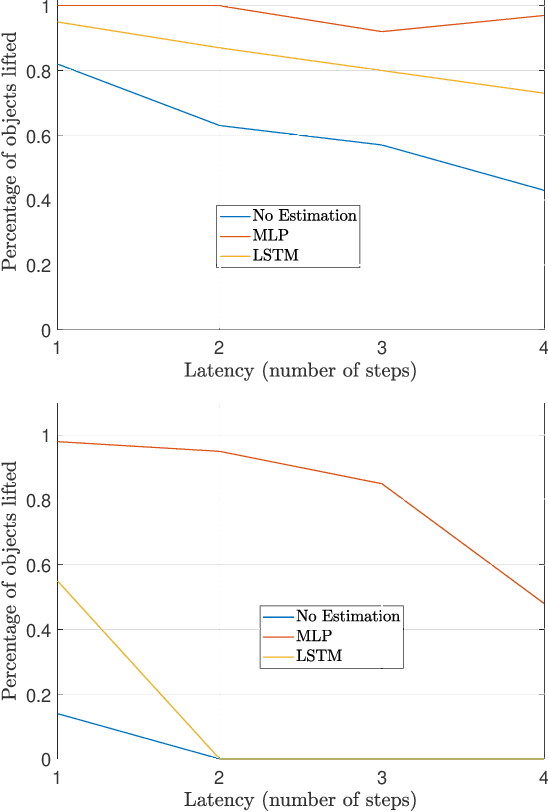
We consider the problem of controlling a series of industrial systems, such as industrial robotics, in a factory environment over a shared wireless channel leveraging edge computing capabilities. The wireless control system model supports the offloading of computational intensive functions, such as perception workloads, to an edge server. However, wireless communications is prone to packet loss and latency and can lead to instability or task failure if the link is not kept sufficiently reliable. Because maintaining high reliability and low latency at all times prohibits scalability due to resource limitations, we propose a communication-control co-design paradigm that varies the network quality of service (QoS) and resulting control actions to the dynamic needs of each plant. We further propose a modular learning framework to solve the complex learning task without knowledge of plant or communication models in a series of learning steps and demonstrate its effectiveness in learning resource-efficient co-design policies in a robotic conveyor belt task.
Graph Reinforcement Learning for Wireless Control Systems: Large-Scale Resource Allocation over Interference Channels
Jan 24, 2022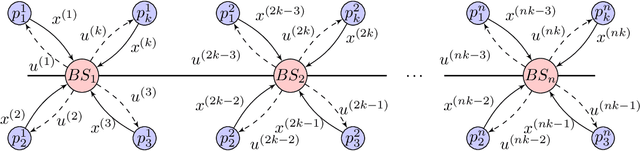
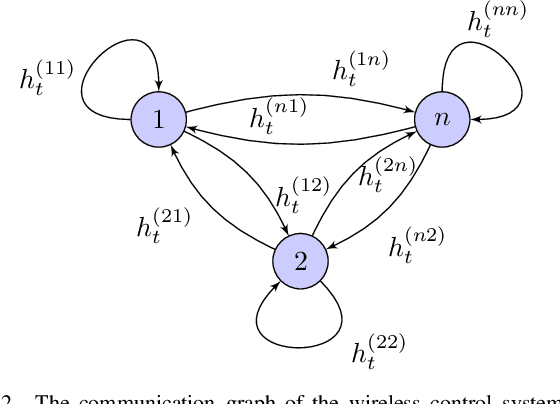
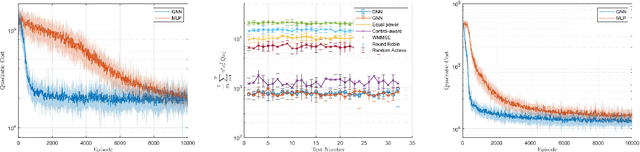
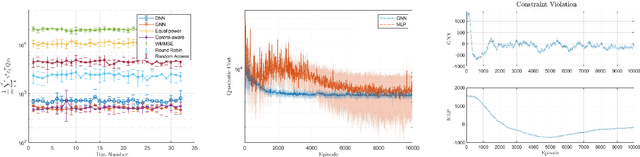
Modern control systems routinely employ wireless networks to exchange information between spatially distributed plants, actuators and sensors. With wireless networks defined by random, rapidly changing transmission conditions that challenge assumptions commonly held in the design of control systems, proper allocation of communication resources is essential to achieve reliable operation. Designing resource allocation policies, however, is challenging, motivating recent works to successfully exploit deep learning and deep reinforcement learning techniques to design resource allocation and scheduling policies for wireless control systems. As the number of learnable parameters in a neural network grows with the size of the input signal, deep reinforcement learning algorithms may fail to scale, limiting the immediate generalization of such scheduling and resource allocation policies to large-scale systems. The interference and fading patterns among plants and controllers in the network, on the other hand, induce a time-varying communication graph that can be used to construct policy representations based on graph neural networks (GNNs), with the number of learnable parameters now independent of the number of plants in the network. That invariance to the number of nodes is key to design scalable and transferable resource allocation policies, which can be trained with reinforcement learning. Through extensive numerical experiments we show that the proposed graph reinforcement learning approach yields policies that not only outperform baseline solutions and deep reinforcement learning based policies in large-scale systems, but that can also be transferred across networks of varying size.
Stable and Transferable Wireless Resource Allocation Policies via Manifold Neural Networks
Oct 10, 2021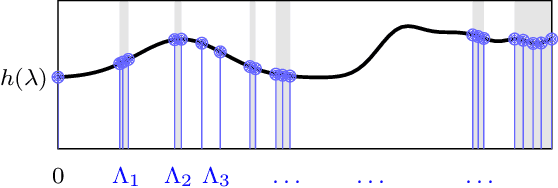
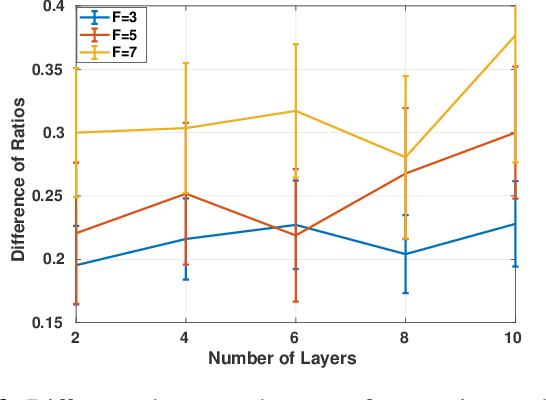
We consider the problem of resource allocation in large scale wireless networks. When contextualizing wireless network structures as graphs, we can model the limits of very large wireless systems as manifolds. To solve the problem in the machine learning framework, we propose the use of Manifold Neural Networks (MNNs) as a policy parametrization. In this work, we prove the stability of MNN resource allocation policies under the absolute perturbations to the Laplace-Beltrami operator of the manifold, representing system noise and dynamics present in wireless systems. These results establish the use of MNNs in achieving stable and transferable allocation policies for large scale wireless networks. We verify our results in numerical simulations that show superior performance relative to baseline methods.
Learning Decentralized Wireless Resource Allocations with Graph Neural Networks
Jul 03, 2021
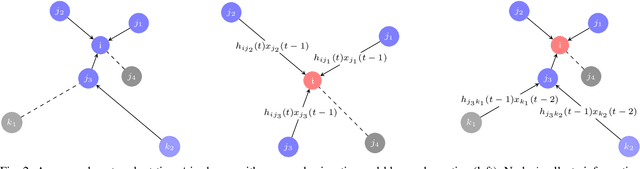
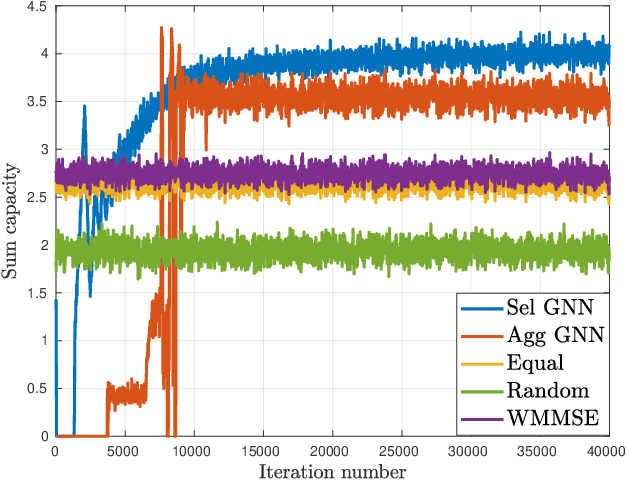
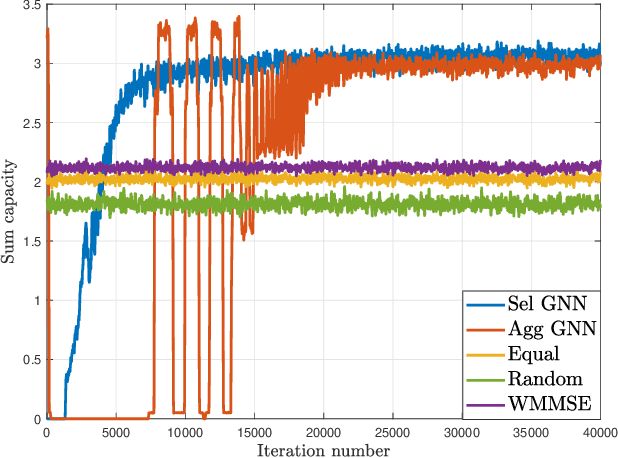
We consider the broad class of decentralized optimal resource allocation problems in wireless networks, which can be formulated as a constrained statistical learning problems with a localized information structure. We develop the use of Aggregation Graph Neural Networks (Agg-GNNs), which process a sequence of delayed and potentially asynchronous graph aggregated state information obtained locally at each transmitter from multi-hop neighbors. We further utilize model-free primal-dual learning methods to optimize performance subject to constraints in the presence of delay and asynchrony inherent to decentralized networks. We demonstrate a permutation equivariance property of the resulting resource allocation policy that can be shown to facilitate transference to dynamic network configurations. The proposed framework is validated with numerical simulations that exhibit superior performance to baseline strategies.
Unsupervised Learning for Asynchronous Resource Allocation in Ad-hoc Wireless Networks
Nov 05, 2020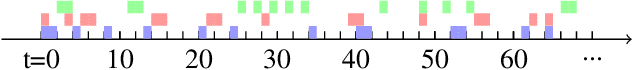
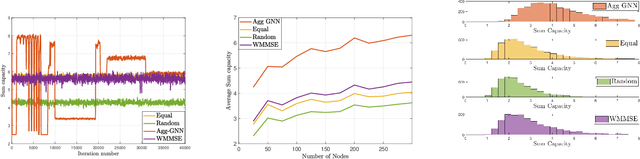
We consider optimal resource allocation problems under asynchronous wireless network setting. Without explicit model knowledge, we design an unsupervised learning method based on Aggregation Graph Neural Networks (Agg-GNNs). Depending on the localized aggregated information structure on each network node, the method can be learned globally and asynchronously while implemented locally. We capture the asynchrony by modeling the activation pattern as a characteristic of each node and train a policy-based resource allocation method. We also propose a permutation invariance property which indicates the transferability of the trained Agg-GNN. We finally verify our strategy by numerical simulations compared with baseline methods.
Resource Allocation via Model-Free Deep Learning in Free Space Optical Networks
Jul 27, 2020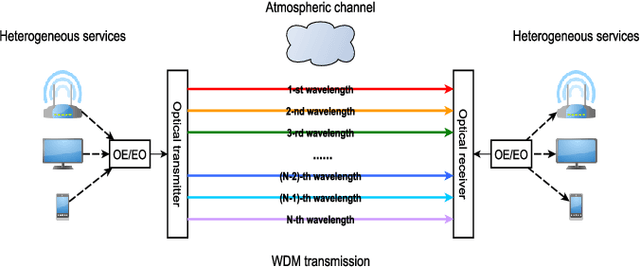
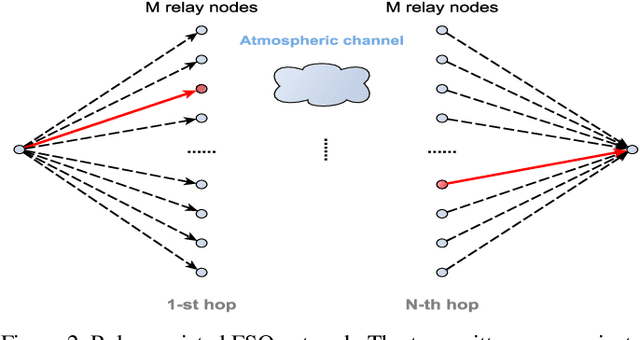
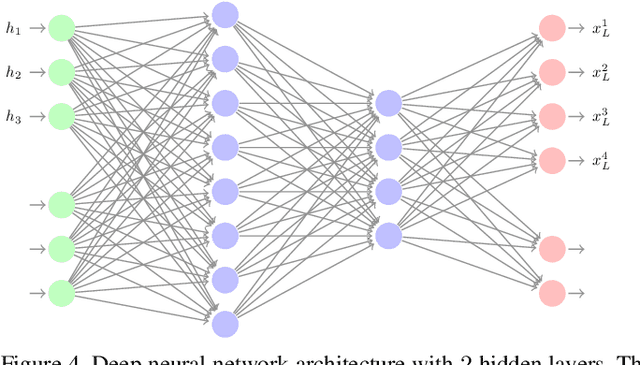
This paper investigates the general problem of resource allocation for mitigating channel fading effects in Free Space Optical (FSO) networks. The resource allocation problem is modelled with a constrained stochastic optimization framework, which we exemplify with problems in power adaptation and relay selection. Under this framework, we develop two algorithms to solve FSO resource allocation problems. We first present the Stochastic Dual Gradient algorithm that solves the problem exactly by exploiting the null duality gap but whose implementation necessarily requires explicit and accurate system models. As an alternative we present the Primal-Dual Deep Learning algorithm, which parametrizes the resource allocation policy with Deep Neural Networks (DNNs) and optimizes via a primal-dual method. The parametrized resource allocation problem incurs only a small loss of optimality due to the strong representational power of DNNs, and can be moreover implemented in an unsupervised manner without knowledge of system models. Numerical experiments are performed to exhibit superior performance of proposed algorithms compared to baseline methods in a variety of resource allocation problems in FSO networks, including both continuous power allocation and binary relay selection.
Resource Allocation via Graph Neural Networks in Free Space Optical Fronthaul Networks
Jun 26, 2020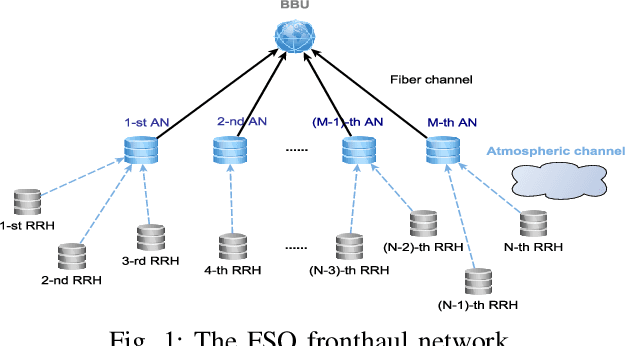
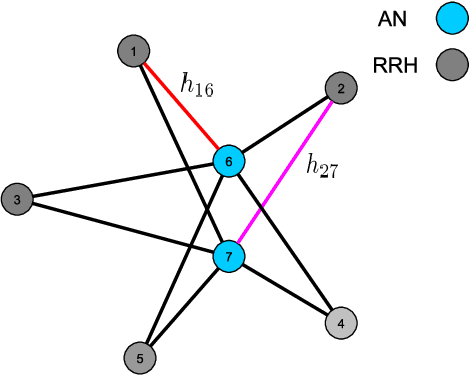
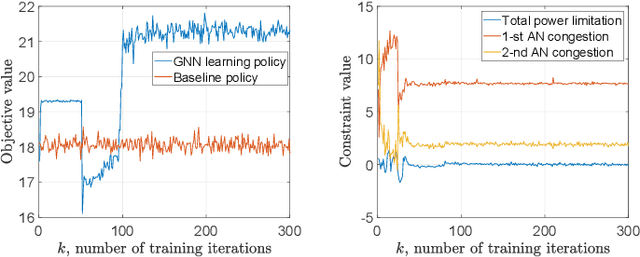
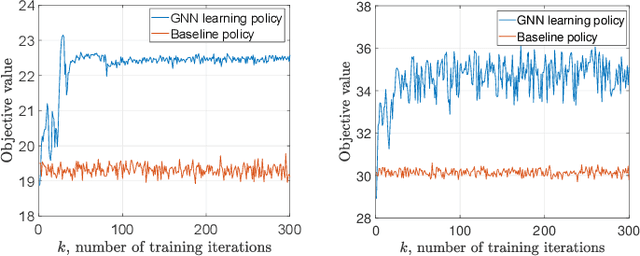
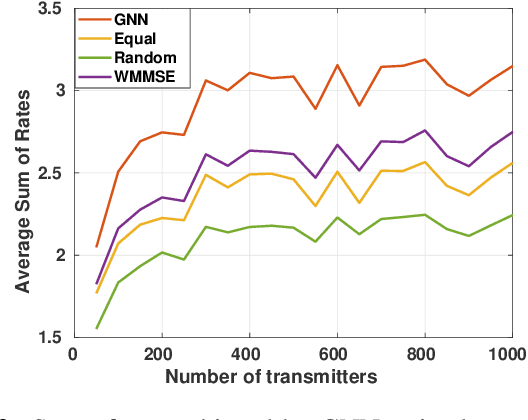
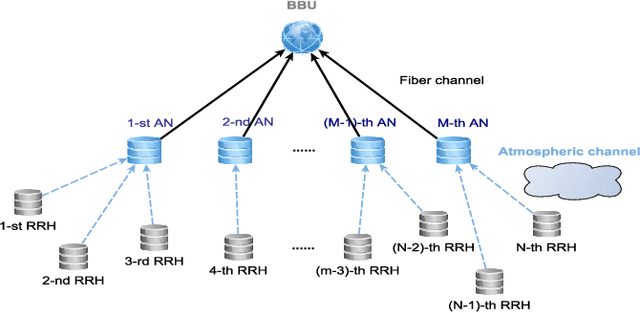
This paper investigates the optimal resource allocation in free space optical (FSO) fronthaul networks. The optimal allocation maximizes an average weighted sum-capacity subject to power limitation and data congestion constraints. Both adaptive power assignment and node selection are considered based on the instantaneous channel state information (CSI) of the links. By parameterizing the resource allocation policy, we formulate the problem as an unsupervised statistical learning problem. We consider the graph neural network (GNN) for the policy parameterization to exploit the FSO network structure with small-scale training parameters. The GNN is shown to retain the permutation equivariance that matches with the permutation equivariance of resource allocation policy in networks. The primal-dual learning algorithm is developed to train the GNN in a model-free manner, where the knowledge of system models is not required. Numerical simulations present the strong performance of the GNN relative to a baseline policy with equal power assignment and random node selection.