 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Reinforcement Learning for Wireless Control Systems: Large-Scale Resource Allocation over Interference Channels
Paper and Code
Jan 24, 2022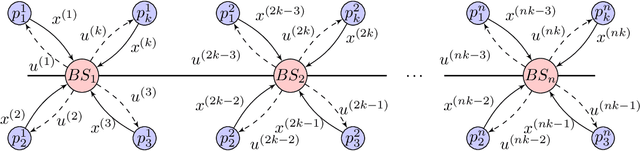
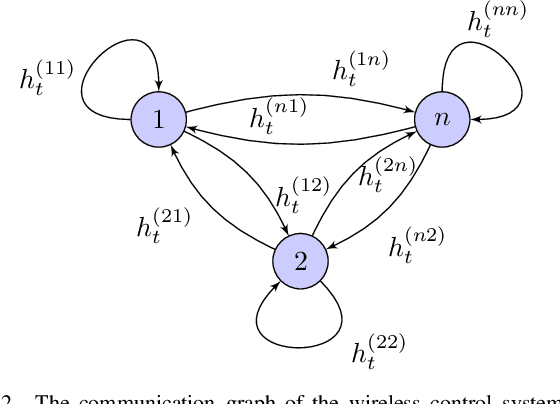
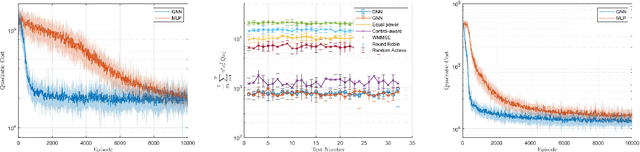
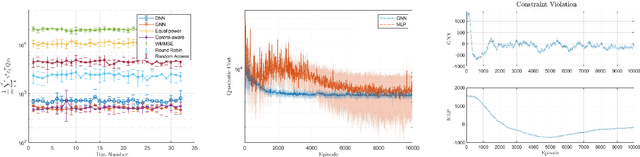
Modern control systems routinely employ wireless networks to exchange information between spatially distributed plants, actuators and sensors. With wireless networks defined by random, rapidly changing transmission conditions that challenge assumptions commonly held in the design of control systems, proper allocation of communication resources is essential to achieve reliable operation. Designing resource allocation policies, however, is challenging, motivating recent works to successfully exploit deep learning and deep reinforcement learning techniques to design resource allocation and scheduling policies for wireless control systems. As the number of learnable parameters in a neural network grows with the size of the input signal, deep reinforcement learning algorithms may fail to scale, limiting the immediate generalization of such scheduling and resource allocation policies to large-scale systems. The interference and fading patterns among plants and controllers in the network, on the other hand, induce a time-varying communication graph that can be used to construct policy representations based on graph neural networks (GNNs), with the number of learnable parameters now independent of the number of plants in the network. That invariance to the number of nodes is key to design scalable and transferable resource allocation policies, which can be trained with reinforcement learning. Through extensive numerical experiments we show that the proposed graph reinforcement learning approach yields policies that not only outperform baseline solutions and deep reinforcement learning based policies in large-scale systems, but that can also be transferred across networks of varying size.