 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersuasion Index: A Theory-Guided Framework for Persuasion Analysis
Jun 12, 2026Identifying persuasive rhetorical cues is critical across domains, from detecting information manipulation and improving AI safety to advancing public health communication. We propose Persuasion Index (PI), a taxonomy of 15 dimensions grounded in persuasion theories from psychology and communication, and one transparent implementation using 55 sub-features built from lexicons and rule-based detectors. The taxonomy is modular: individual detectors can be replaced while preserving the theoretical structure. By evaluating PI on four public datasets varying in domain, style, and outcome measures, we show that PI provides a shared feature space for interpreting rhetorical patterns associated with persuasion-related outcomes. Linear models show that PI features carry meaningful predictive signal while remaining computationally lightweight. Dimension-level analyses reveal recurring associations between PI dimensions and persuasion outcomes across datasets, while also highlighting topic- and stance-specific variation. We release PI as an open-source package and web interface for principled and auditable analysis of human and AI-mediated communication.
Limit Analysis of Graph Neural Networks with Wireless Conflict Graphs
Jun 02, 2026Graph Neural Networks (GNNs) have emerged as a powerful tool for wireless resource allocation that leverages the underlying graph structure of communication networks. Their transferability property enables models trained on small-scale graphs to generalize to large-scale deployments with little performance deterioration, a desirable property for currently growing networks. Wireless networks are sparse regimes, where a single node is connected to a small number of other users. This work establishes theoretical results for transferability of GNNs over graphs derived from sparse Random Geometric Graphs (RGGs). In particular, we focus on conflict graphs of RGGs used to model interference among links. Our approach considers the closeness between RGGs and Deterministic Grid Graphs (DGG) to establish bounds in the performance loss when a model is transferred across scales. We validate our theoretical findings through the problem of link scheduling, demonstrating that our learned policies consistently outperform existing benchmarks at scale. Finally, we examine the impact of our theoretical assumptions on empirical performance.
Size Transferability of Graph Transformers with Convolutional Positional Encodings
Feb 16, 2026Transformers have achieved remarkable success across domains, motivating the rise of Graph Transformers (GTs) as attention-based architectures for graph-structured data. A key design choice in GTs is the use of Graph Neural Network (GNN)-based positional encodings to incorporate structural information. In this work, we study GTs through the lens of manifold limit models for graph sequences and establish a theoretical connection between GTs with GNN positional encodings and Manifold Neural Networks (MNNs). Building on transferability results for GNNs under manifold convergence, we show that GTs inherit transferability guarantees from their positional encodings. In particular, GTs trained on small graphs provably generalize to larger graphs under mild assumptions. We complement our theory with extensive experiments on standard graph benchmarks, demonstrating that GTs exhibit scalable behavior on par with GNNs. To further show the efficiency in a real-world scenario, we implement GTs for shortest path distance estimation over terrains to better illustrate the efficiency of the transferable GTs. Our results provide new insights into the understanding of GTs and suggest practical directions for efficient training of GTs in large-scale settings.
Position: Message-passing and spectral GNNs are two sides of the same coin
Feb 10, 2026Graph neural networks (GNNs) are commonly divided into message-passing neural networks (MPNNs) and spectral graph neural networks, reflecting two largely separate research traditions in machine learning and signal processing. This paper argues that this divide is mostly artificial, hindering progress in the field. We propose a viewpoint in which both MPNNs and spectral GNNs are understood as different parametrizations of permutation-equivariant operators acting on graph signals. From this perspective, many popular architectures are equivalent in expressive power, while genuine gaps arise only in specific regimes. We further argue that MPNNs and spectral GNNs offer complementary strengths. That is, MPNNs provide a natural language for discrete structure and expressivity analysis using tools from logic and graph isomorphism research, while the spectral perspective provides principled tools for understanding smoothing, bottlenecks, stability, and community structure. Overall, we posit that progress in graph learning will be accelerated by clearly understanding the key similarities and differences between these two types of GNNs, and by working towards unifying these perspectives within a common theoretical and conceptual framework rather than treating them as competing paradigms.
Graph Semi-Supervised Learning for Point Classification on Data Manifolds
Jun 13, 2025We propose a graph semi-supervised learning framework for classification tasks on data manifolds. Motivated by the manifold hypothesis, we model data as points sampled from a low-dimensional manifold $\mathcal{M} \subset \mathbb{R}^F$. The manifold is approximated in an unsupervised manner using a variational autoencoder (VAE), where the trained encoder maps data to embeddings that represent their coordinates in $\mathbb{R}^F$. A geometric graph is constructed with Gaussian-weighted edges inversely proportional to distances in the embedding space, transforming the point classification problem into a semi-supervised node classification task on the graph. This task is solved using a graph neural network (GNN). Our main contribution is a theoretical analysis of the statistical generalization properties of this data-to-manifold-to-graph pipeline. We show that, under uniform sampling from $\mathcal{M}$, the generalization gap of the semi-supervised task diminishes with increasing graph size, up to the GNN training error. Leveraging a training procedure which resamples a slightly larger graph at regular intervals during training, we then show that the generalization gap can be reduced even further, vanishing asymptotically. Finally, we validate our findings with numerical experiments on image classification benchmarks, demonstrating the empirical effectiveness of our approach.
Wireless Link Scheduling with State-Augmented Graph Neural Networks
May 12, 2025We consider the problem of optimal link scheduling in large-scale wireless ad hoc networks. We specifically aim for the maximum long-term average performance, subject to a minimum transmission requirement for each link to ensure fairness. With a graph structure utilized to represent the conflicts of links, we formulate a constrained optimization problem to learn the scheduling policy, which is parameterized with a graph neural network (GNN). To address the challenge of long-term performance, we use the state-augmentation technique. In particular, by augmenting the Lagrangian dual variables as dynamic inputs to the scheduling policy, the GNN can be trained to gradually adapt the scheduling decisions to achieve the minimum transmission requirements. We verify the efficacy of our proposed policy through numerical simulations and compare its performance with several baselines in various network settings.
Generalization of Geometric Graph Neural Networks
Sep 08, 2024In this paper, we study the generalization capabilities of geometric graph neural networks (GNNs). We consider GNNs over a geometric graph constructed from a finite set of randomly sampled points over an embedded manifold with topological information captured. We prove a generalization gap between the optimal empirical risk and the optimal statistical risk of this GNN, which decreases with the number of sampled points from the manifold and increases with the dimension of the underlying manifold. This generalization gap ensures that the GNN trained on a graph on a set of sampled points can be utilized to process other unseen graphs constructed from the same underlying manifold. The most important observation is that the generalization capability can be realized with one large graph instead of being limited to the size of the graph as in previous results. The generalization gap is derived based on the non-asymptotic convergence result of a GNN on the sampled graph to the underlying manifold neural networks (MNNs). We verify this theoretical result with experiments on both Arxiv dataset and Cora dataset.
Generalization of Graph Neural Networks is Robust to Model Mismatch
Aug 25, 2024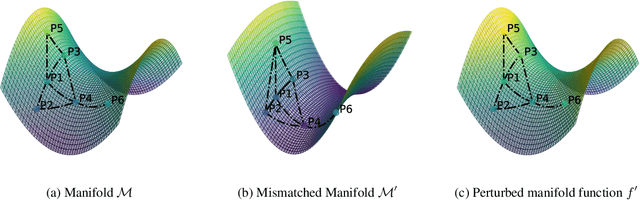
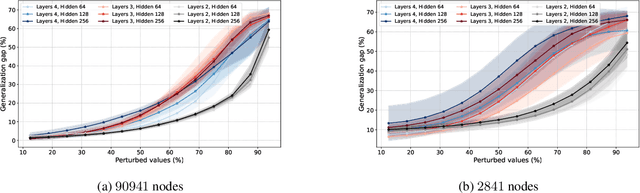
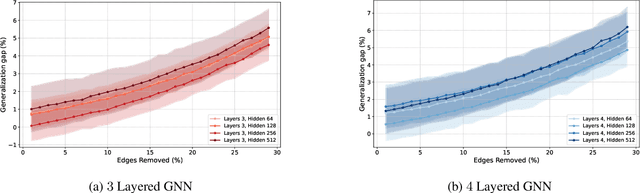
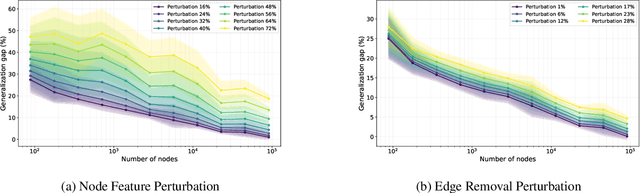
Graph neural networks (GNNs) have demonstrated their effectiveness in various tasks supported by their generalization capabilities. However, the current analysis of GNN generalization relies on the assumption that training and testing data are independent and identically distributed (i.i.d). This imposes limitations on the cases where a model mismatch exists when generating testing data. In this paper, we examine GNNs that operate on geometric graphs generated from manifold models, explicitly focusing on scenarios where there is a mismatch between manifold models generating training and testing data. Our analysis reveals the robustness of the GNN generalization in the presence of such model mismatch. This indicates that GNNs trained on graphs generated from a manifold can still generalize well to unseen nodes and graphs generated from a mismatched manifold. We attribute this mismatch to both node feature perturbations and edge perturbations within the generated graph. Our findings indicate that the generalization gap decreases as the number of nodes grows in the training graph while increasing with larger manifold dimension as well as larger mismatch. Importantly, we observe a trade-off between the generalization of GNNs and the capability to discriminate high-frequency components when facing a model mismatch. The most important practical consequence of this analysis is to shed light on the filter design of generalizable GNNs robust to model mismatch. We verify our theoretical findings with experiments on multiple real-world datasets.
A Manifold Perspective on the Statistical Generalization of Graph Neural Networks
Jun 07, 2024Convolutional neural networks have been successfully extended to operate on graphs, giving rise to Graph Neural Networks (GNNs). GNNs combine information from adjacent nodes by successive applications of graph convolutions. GNNs have been implemented successfully in various learning tasks while the theoretical understanding of their generalization capability is still in progress. In this paper, we leverage manifold theory to analyze the statistical generalization gap of GNNs operating on graphs constructed on sampled points from manifolds. We study the generalization gaps of GNNs on both node-level and graph-level tasks. We show that the generalization gaps decrease with the number of nodes in the training graphs, which guarantees the generalization of GNNs to unseen points over manifolds. We validate our theoretical results in multiple real-world datasets.
Geometric Graph Filters and Neural Networks: Limit Properties and Discriminability Trade-offs
May 29, 2023This paper studies the relationship between a graph neural network (GNN) and a manifold neural network (MNN) when the graph is constructed from a set of points sampled from the manifold, thus encoding geometric information. We consider convolutional MNNs and GNNs where the manifold and the graph convolutions are respectively defined in terms of the Laplace-Beltrami operator and the graph Laplacian. Using the appropriate kernels, we analyze both dense and moderately sparse graphs. We prove non-asymptotic error bounds showing that convolutional filters and neural networks on these graphs converge to convolutional filters and neural networks on the continuous manifold. As a byproduct of this analysis, we observe an important trade-off between the discriminability of graph filters and their ability to approximate the desired behavior of manifold filters. We then discuss how this trade-off is ameliorated in neural networks due to the frequency mixing property of nonlinearities. We further derive a transferability corollary for geometric graphs sampled from the same manifold. We validate our results numerically on a navigation control problem and a point cloud classification task.