 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUNA: Linear Universal Neural Attention with Generalization Guarantees
Dec 08, 2025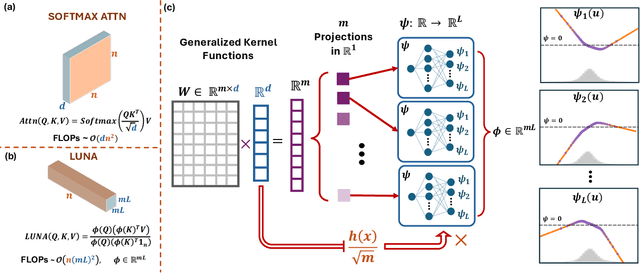
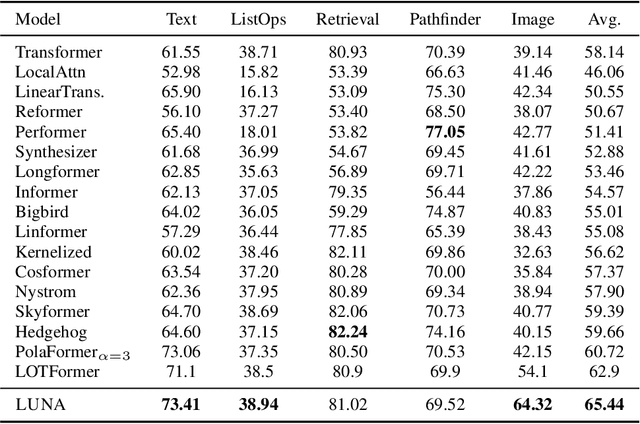
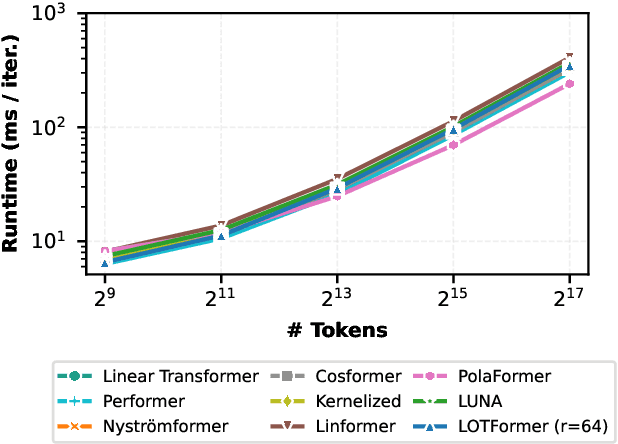
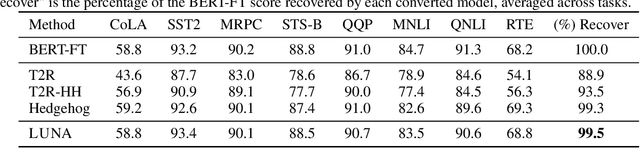
Scaling attention faces a critical bottleneck: the $\mathcal{O}(n^2)$ quadratic computational cost of softmax attention, which limits its application in long-sequence domains. While linear attention mechanisms reduce this cost to $\mathcal{O}(n)$, they typically rely on fixed random feature maps, such as random Fourier features or hand-crafted functions. This reliance on static, data-agnostic kernels creates a fundamental trade-off, forcing practitioners to sacrifice significant model accuracy for computational efficiency. We introduce \textsc{LUNA}, a kernelized linear attention mechanism that eliminates this trade-off, retaining linear cost while matching and surpassing the accuracy of quadratic attention. \textsc{LUNA} is built on the key insight that the kernel feature map itself should be learned rather than fixed a priori. By parameterizing the kernel, \textsc{LUNA} learns a feature basis tailored to the specific data and task, overcoming the expressive limitations of fixed-feature methods. \textsc{Luna} implements this with a learnable feature map that induces a positive-definite kernel and admits a streaming form, yielding linear time and memory scaling in the sequence length. Empirical evaluations validate our approach across diverse settings. On the Long Range Arena (LRA), \textsc{Luna} achieves state-of-the-art average accuracy among efficient Transformers under compute parity, using the same parameter count, training steps, and approximate FLOPs. \textsc{Luna} also excels at post-hoc conversion: replacing softmax in fine-tuned BERT and ViT-B/16 checkpoints and briefly fine-tuning recovers most of the original performance, substantially outperforming fixed linearizations.
Transport Based Mean Flows for Generative Modeling
Sep 26, 2025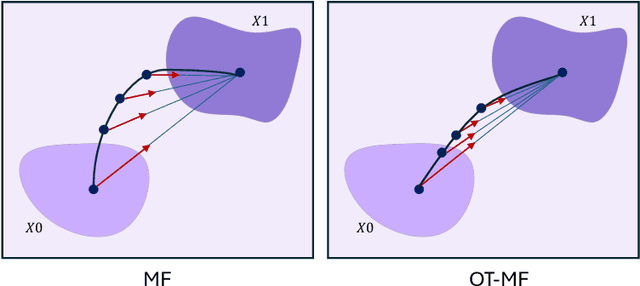


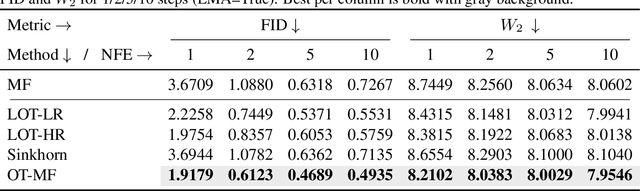
Flow-matching generative models have emerged as a powerful paradigm for continuous data generation, achieving state-of-the-art results across domains such as images, 3D shapes, and point clouds. Despite their success, these models suffer from slow inference due to the requirement of numerous sequential sampling steps. Recent work has sought to accelerate inference by reducing the number of sampling steps. In particular, Mean Flows offer a one-step generation approach that delivers substantial speedups while retaining strong generative performance. Yet, in many continuous domains, Mean Flows fail to faithfully approximate the behavior of the original multi-step flow-matching process. In this work, we address this limitation by incorporating optimal transport-based sampling strategies into the Mean Flow framework, enabling one-step generators that better preserve the fidelity and diversity of the original multi-step flow process. Experiments on controlled low-dimensional settings and on high-dimensional tasks such as image generation, image-to-image translation, and point cloud generation demonstrate that our approach achieves superior inference accuracy in one-step generative modeling.
Neural-Augmented Kelvinlet: Real-Time Soft Tissue Deformation with Multiple Graspers
Jun 06, 2025Fast and accurate simulation of soft tissue deformation is a critical factor for surgical robotics and medical training. In this paper, we introduce a novel physics-informed neural simulator that approximates soft tissue deformations in a realistic and real-time manner. Our framework integrates Kelvinlet-based priors into neural simulators, making it the first approach to leverage Kelvinlets for residual learning and regularization in data-driven soft tissue modeling. By incorporating large-scale Finite Element Method (FEM) simulations of both linear and nonlinear soft tissue responses, our method improves neural network predictions across diverse architectures, enhancing accuracy and physical consistency while maintaining low latency for real-time performance. We demonstrate the effectiveness of our approach by performing accurate surgical maneuvers that simulate the use of standard laparoscopic tissue grasping tools with high fidelity. These results establish Kelvinlet-augmented learning as a powerful and efficient strategy for real-time, physics-aware soft tissue simulation in surgical applications.
ESPFormer: Doubly-Stochastic Attention with Expected Sliced Transport Plans
Feb 11, 2025While self-attention has been instrumental in the success of Transformers, it can lead to over-concentration on a few tokens during training, resulting in suboptimal information flow. Enforcing doubly-stochastic constraints in attention matrices has been shown to improve structure and balance in attention distributions. However, existing methods rely on iterative Sinkhorn normalization, which is computationally costly. In this paper, we introduce a novel, fully parallelizable doubly-stochastic attention mechanism based on sliced optimal transport, leveraging Expected Sliced Transport Plans (ESP). Unlike prior approaches, our method enforces double stochasticity without iterative Sinkhorn normalization, significantly enhancing efficiency. To ensure differentiability, we incorporate a temperature-based soft sorting technique, enabling seamless integration into deep learning models. Experiments across multiple benchmark datasets, including image classification, point cloud classification, sentiment analysis, and neural machine translation, demonstrate that our enhanced attention regularization consistently improves performance across diverse applications.
CovarNav: Machine Unlearning via Model Inversion and Covariance Navigation
Nov 21, 2023



The rapid progress of AI, combined with its unprecedented public adoption and the propensity of large neural networks to memorize training data, has given rise to significant data privacy concerns. To address these concerns, machine unlearning has emerged as an essential technique to selectively remove the influence of specific training data points on trained models. In this paper, we approach the machine unlearning problem through the lens of continual learning. Given a trained model and a subset of training data designated to be forgotten (i.e., the "forget set"), we introduce a three-step process, named CovarNav, to facilitate this forgetting. Firstly, we derive a proxy for the model's training data using a model inversion attack. Secondly, we mislabel the forget set by selecting the most probable class that deviates from the actual ground truth. Lastly, we deploy a gradient projection method to minimize the cross-entropy loss on the modified forget set (i.e., learn incorrect labels for this set) while preventing forgetting of the inverted samples. We rigorously evaluate CovarNav on the CIFAR-10 and Vggface2 datasets, comparing our results with recent benchmarks in the field and demonstrating the efficacy of our proposed approach.