 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUNA: Linear Universal Neural Attention with Generalization Guarantees
Dec 08, 2025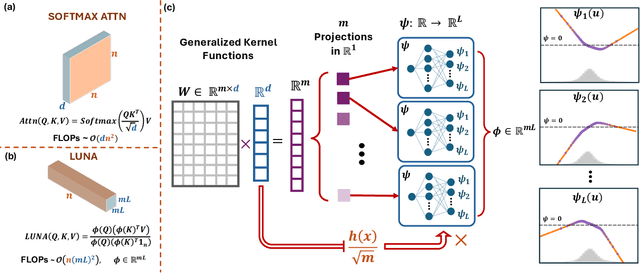
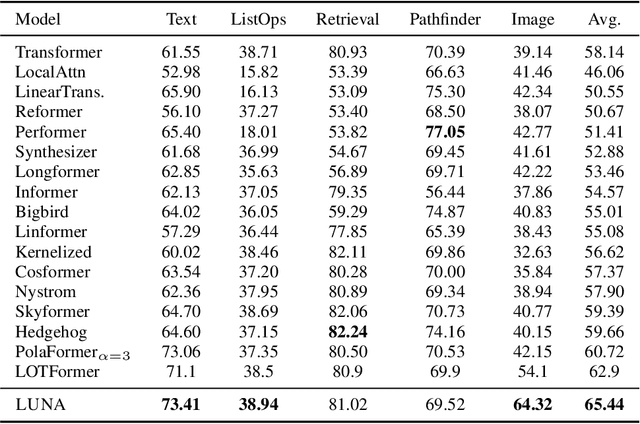
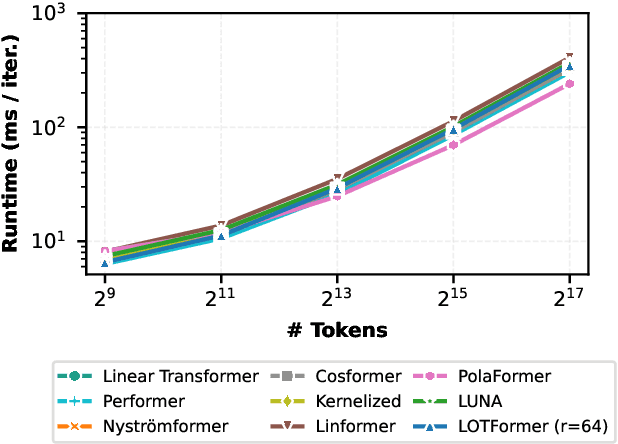
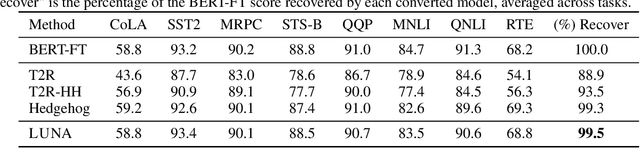
Scaling attention faces a critical bottleneck: the $\mathcal{O}(n^2)$ quadratic computational cost of softmax attention, which limits its application in long-sequence domains. While linear attention mechanisms reduce this cost to $\mathcal{O}(n)$, they typically rely on fixed random feature maps, such as random Fourier features or hand-crafted functions. This reliance on static, data-agnostic kernels creates a fundamental trade-off, forcing practitioners to sacrifice significant model accuracy for computational efficiency. We introduce \textsc{LUNA}, a kernelized linear attention mechanism that eliminates this trade-off, retaining linear cost while matching and surpassing the accuracy of quadratic attention. \textsc{LUNA} is built on the key insight that the kernel feature map itself should be learned rather than fixed a priori. By parameterizing the kernel, \textsc{LUNA} learns a feature basis tailored to the specific data and task, overcoming the expressive limitations of fixed-feature methods. \textsc{Luna} implements this with a learnable feature map that induces a positive-definite kernel and admits a streaming form, yielding linear time and memory scaling in the sequence length. Empirical evaluations validate our approach across diverse settings. On the Long Range Arena (LRA), \textsc{Luna} achieves state-of-the-art average accuracy among efficient Transformers under compute parity, using the same parameter count, training steps, and approximate FLOPs. \textsc{Luna} also excels at post-hoc conversion: replacing softmax in fine-tuned BERT and ViT-B/16 checkpoints and briefly fine-tuning recovers most of the original performance, substantially outperforming fixed linearizations.
ESPFormer: Doubly-Stochastic Attention with Expected Sliced Transport Plans
Feb 11, 2025While self-attention has been instrumental in the success of Transformers, it can lead to over-concentration on a few tokens during training, resulting in suboptimal information flow. Enforcing doubly-stochastic constraints in attention matrices has been shown to improve structure and balance in attention distributions. However, existing methods rely on iterative Sinkhorn normalization, which is computationally costly. In this paper, we introduce a novel, fully parallelizable doubly-stochastic attention mechanism based on sliced optimal transport, leveraging Expected Sliced Transport Plans (ESP). Unlike prior approaches, our method enforces double stochasticity without iterative Sinkhorn normalization, significantly enhancing efficiency. To ensure differentiability, we incorporate a temperature-based soft sorting technique, enabling seamless integration into deep learning models. Experiments across multiple benchmark datasets, including image classification, point cloud classification, sentiment analysis, and neural machine translation, demonstrate that our enhanced attention regularization consistently improves performance across diverse applications.