 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification in Continual Open-World Learning
Dec 21, 2024



AI deployed in the real-world should be capable of autonomously adapting to novelties encountered after deployment. Yet, in the field of continual learning, the reliance on novelty and labeling oracles is commonplace albeit unrealistic. This paper addresses a challenging and under-explored problem: a deployed AI agent that continuously encounters unlabeled data - which may include both unseen samples of known classes and samples from novel (unknown) classes - and must adapt to it continuously. To tackle this challenge, we propose our method COUQ "Continual Open-world Uncertainty Quantification", an iterative uncertainty estimation algorithm tailored for learning in generalized continual open-world multi-class settings. We rigorously apply and evaluate COUQ on key sub-tasks in the Continual Open-World: continual novelty detection, uncertainty guided active learning, and uncertainty guided pseudo-labeling for semi-supervised CL. We demonstrate the effectiveness of our method across multiple datasets, ablations, backbones and performance superior to state-of-the-art.
PROMPT: Learning Dynamic Resource Allocation Policies for Edge-Network Applications
Jan 19, 2022



A growing number of service providers are exploring methods to improve server utilization, reduce power consumption, and reduce total cost of ownership by co-scheduling high-priority latency-critical workloads with best-effort workloads. This practice requires strict resource allocation between workloads to reduce resource contention and maintain Quality of Service (QoS) guarantees. Prior resource allocation works have been shown to improve server utilization under ideal circumstances, yet often compromise QoS guarantees or fail to find valid resource allocations in more dynamic operating environments. Further, prior works are fundamentally reliant upon QoS measurements that can, in practice, exhibit significant transient fluctuations, thus stable control behavior cannot be reliably achieved. In this paper, we propose a novel framework for dynamic resource allocation based on proactive QoS prediction. These predictions help guide a reinforcement-learning-based resource controller towards optimal resource allocations while avoiding transient QoS violations due to fluctuating workload demands. Evaluation shows that the proposed method incurs 4.3x fewer QoS violations, reduces severity of QoS violations by 3.7x, improves best-effort workload performance, and improves overall power efficiency compared with prior work.
Resource Management in Wireless Networks via Multi-Agent Deep Reinforcement Learning
Feb 14, 2020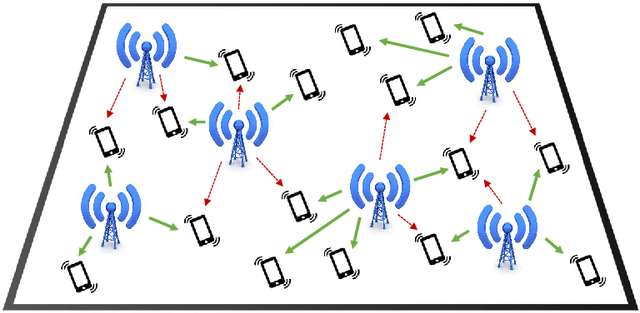
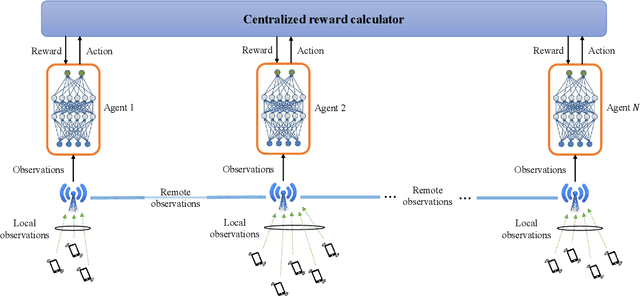
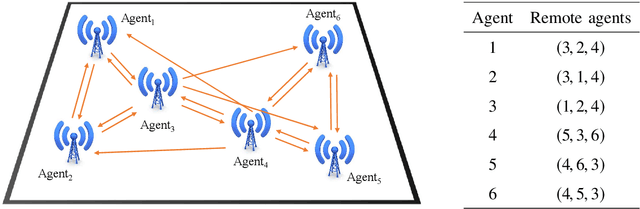
We propose a mechanism for distributed radio resource management using multi-agent deep reinforcement learning (RL) for interference mitigation in wireless networks. We equip each transmitter in the network with a deep RL agent, which receives partial delayed observations from its associated users, while also exchanging observations with its neighboring agents, and decides on which user to serve and what transmit power to use at each scheduling interval. Our proposed framework enables the agents to make decisions simultaneously and in a distributed manner, without any knowledge about the concurrent decisions of other agents. Moreover, our design of the agents' observation and action spaces is scalable, in the sense that an agent trained on a scenario with a specific number of transmitters and receivers can be readily applied to scenarios with different numbers of transmitters and/or receivers. Simulation results demonstrate the superiority of our proposed approach compared to decentralized baselines in terms of the tradeoff between average and $5^{th}$ percentile user rates, while achieving performance close to, and even in certain cases outperforming, that of a centralized information-theoretic scheduling algorithm. We also show that our trained agents are robust and maintain their performance gains when experiencing mismatches between training and testing deployments.
When Multiple Agents Learn to Schedule: A Distributed Radio Resource Management Framework
Jun 20, 2019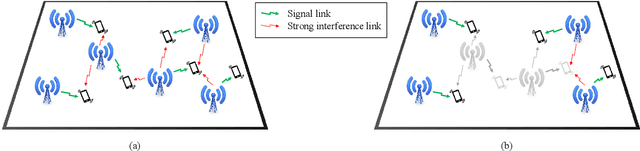
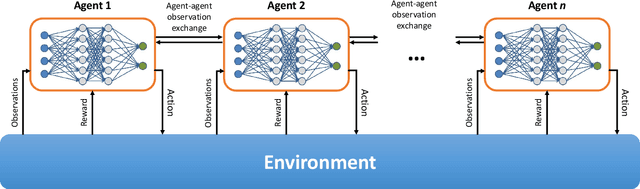
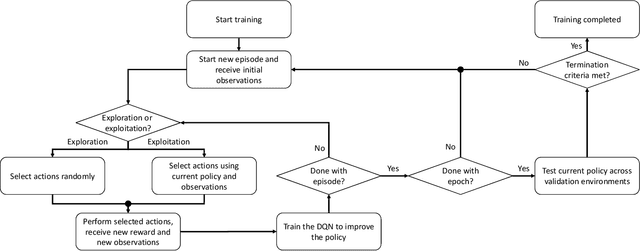
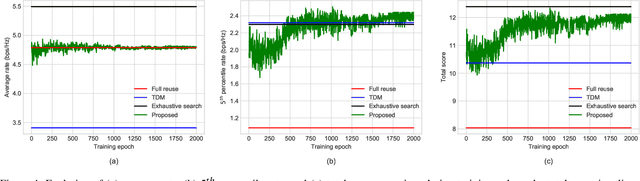
Interference among concurrent transmissions in a wireless network is a key factor limiting the system performance. One way to alleviate this problem is to manage the radio resources in order to maximize either the average or the worst-case performance. However, joint consideration of both metrics is often neglected as they are competing in nature. In this article, a mechanism for radio resource management using multi-agent deep reinforcement learning (RL) is proposed, which strikes the right trade-off between maximizing the average and the $5^{th}$ percentile user throughput. Each transmitter in the network is equipped with a deep RL agent, receiving partial observations from the network (e.g., channel quality, interference level, etc.) and deciding whether to be active or inactive at each scheduling interval for given radio resources, a process referred to as link scheduling. Based on the actions of all agents, the network emits a reward to the agents, indicating how good their joint decisions were. The proposed framework enables the agents to make decisions in a distributed manner, and the reward is designed in such a way that the agents strive to guarantee a minimum performance, leading to a fair resource allocation among all users across the network. Simulation results demonstrate the superiority of our approach compared to decentralized baselines in terms of average and $5^{th}$ percentile user throughput, while achieving performance close to that of a centralized exhaustive search approach. Moreover, the proposed framework is robust to mismatches between training and testing scenarios. In particular, it is shown that an agent trained on a network with low transmitter density maintains its performance and outperforms the baselines when deployed in a network with a higher transmitter density.