 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification in Continual Open-World Learning
Dec 21, 2024



AI deployed in the real-world should be capable of autonomously adapting to novelties encountered after deployment. Yet, in the field of continual learning, the reliance on novelty and labeling oracles is commonplace albeit unrealistic. This paper addresses a challenging and under-explored problem: a deployed AI agent that continuously encounters unlabeled data - which may include both unseen samples of known classes and samples from novel (unknown) classes - and must adapt to it continuously. To tackle this challenge, we propose our method COUQ "Continual Open-world Uncertainty Quantification", an iterative uncertainty estimation algorithm tailored for learning in generalized continual open-world multi-class settings. We rigorously apply and evaluate COUQ on key sub-tasks in the Continual Open-World: continual novelty detection, uncertainty guided active learning, and uncertainty guided pseudo-labeling for semi-supervised CL. We demonstrate the effectiveness of our method across multiple datasets, ablations, backbones and performance superior to state-of-the-art.
CONCLAD: COntinuous Novel CLAss Detector
Dec 13, 2024


In the field of continual learning, relying on so-called oracles for novelty detection is commonplace albeit unrealistic. This paper introduces CONCLAD ("COntinuous Novel CLAss Detector"), a comprehensive solution to the under-explored problem of continual novel class detection in post-deployment data. At each new task, our approach employs an iterative uncertainty estimation algorithm to differentiate between known and novel class(es) samples, and to further discriminate between the different novel classes themselves. Samples predicted to be from a novel class with high-confidence are automatically pseudo-labeled and used to update our model. Simultaneously, a tiny supervision budget is used to iteratively query ambiguous novel class predictions, which are also used during update. Evaluation across multiple datasets, ablations and experimental settings demonstrate our method's effectiveness at separating novel and old class samples continuously. We will release our code upon acceptance.
CUAL: Continual Uncertainty-aware Active Learner
Dec 12, 2024



AI deployed in many real-world use cases should be capable of adapting to novelties encountered after deployment. Here, we consider a challenging, under-explored and realistic continual adaptation problem: a deployed AI agent is continuously provided with unlabeled data that may contain not only unseen samples of known classes but also samples from novel (unknown) classes. In such a challenging setting, it has only a tiny labeling budget to query the most informative samples to help it continuously learn. We present a comprehensive solution to this complex problem with our model "CUAL" (Continual Uncertainty-aware Active Learner). CUAL leverages an uncertainty estimation algorithm to prioritize active labeling of ambiguous (uncertain) predicted novel class samples while also simultaneously pseudo-labeling the most certain predictions of each class. Evaluations across multiple datasets, ablations, settings and backbones (e.g. ViT foundation model) demonstrate our method's effectiveness. We will release our code upon acceptance.
Rate-Distortion Theory in Coding for Machines and its Application
May 26, 2023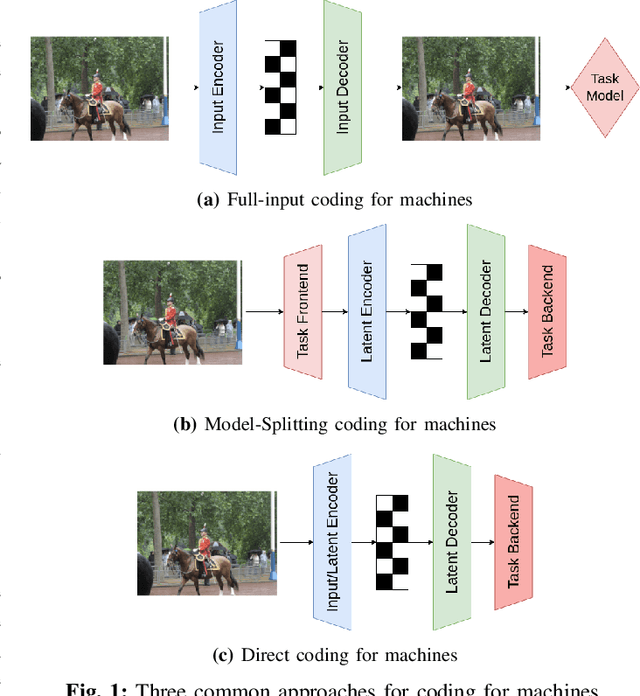
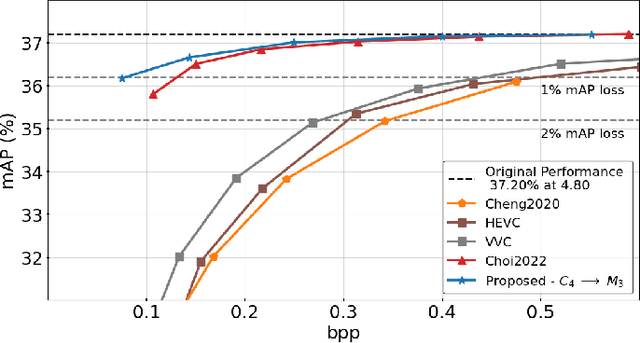
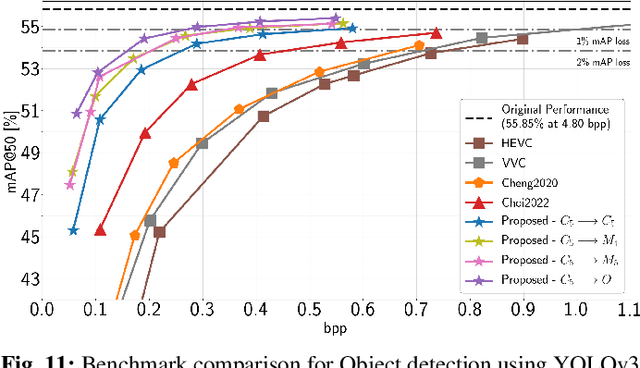
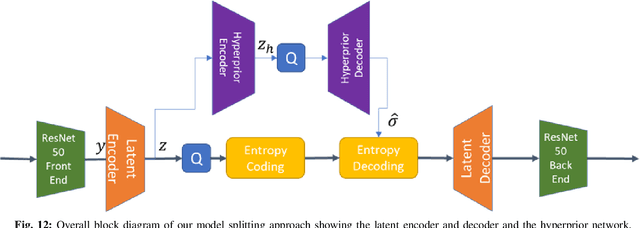
Recent years have seen a tremendous growth in both the capability and popularity of automatic machine analysis of images and video. As a result, a growing need for efficient compression methods optimized for machine vision, rather than human vision, has emerged. To meet this growing demand, several methods have been developed for image and video coding for machines. Unfortunately, while there is a substantial body of knowledge regarding rate-distortion theory for human vision, the same cannot be said of machine analysis. In this paper, we extend the current rate-distortion theory for machines, providing insight into important design considerations of machine-vision codecs. We then utilize this newfound understanding to improve several methods for learnable image coding for machines. Our proposed methods achieve state-of-the-art rate-distortion performance on several computer vision tasks such as classification, instance segmentation, and object detection.
A Low-Complexity Approach to Rate-Distortion Optimized Variable Bit-Rate Compression for Split DNN Computing
Aug 24, 2022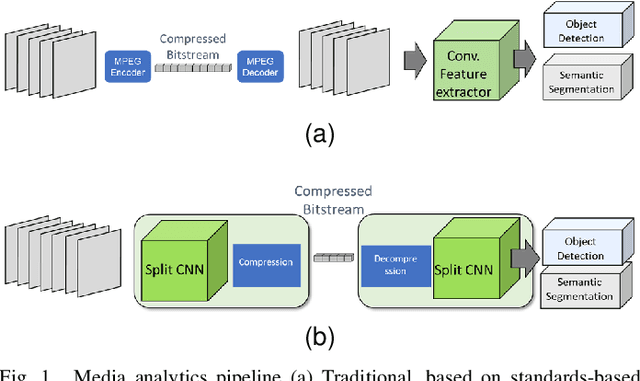
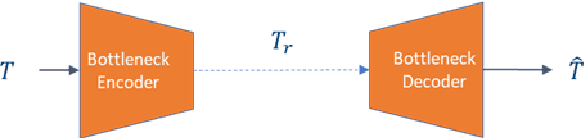
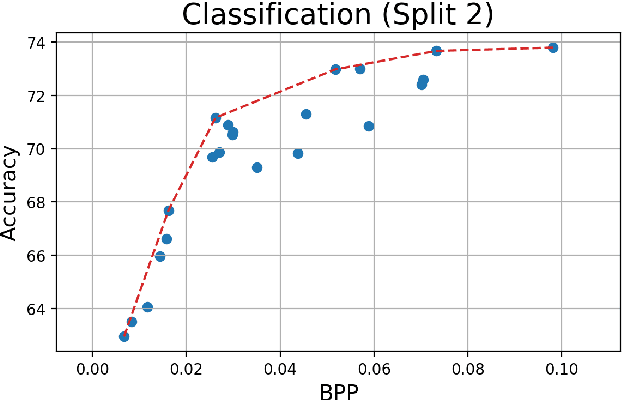

Split computing has emerged as a recent paradigm for implementation of DNN-based AI workloads, wherein a DNN model is split into two parts, one of which is executed on a mobile/client device and the other on an edge-server (or cloud). Data compression is applied to the intermediate tensor from the DNN that needs to be transmitted, addressing the challenge of optimizing the rate-accuracy-complexity trade-off. Existing split-computing approaches adopt ML-based data compression, but require that the parameters of either the entire DNN model, or a significant portion of it, be retrained for different compression levels. This incurs a high computational and storage burden: training a full DNN model from scratch is computationally demanding, maintaining multiple copies of the DNN parameters increases storage requirements, and switching the full set of weights during inference increases memory bandwidth. In this paper, we present an approach that addresses all these challenges. It involves the systematic design and training of bottleneck units - simple, low-cost neural networks - that can be inserted at the point of split. Our approach is remarkably lightweight, both during training and inference, highly effective and achieves excellent rate-distortion performance at a small fraction of the compute and storage overhead compared to existing methods.
A Greedy Part Assignment Algorithm for Real-time Multi-person 2D Pose Estimation
Aug 30, 2017
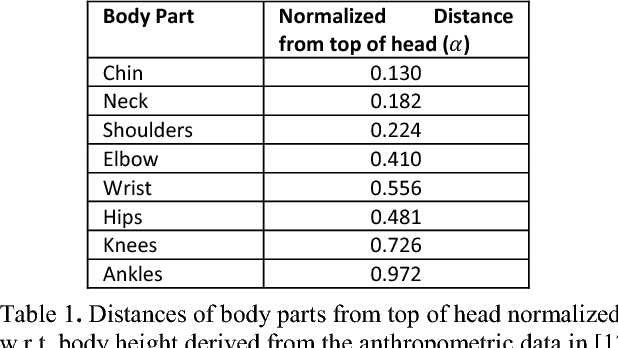
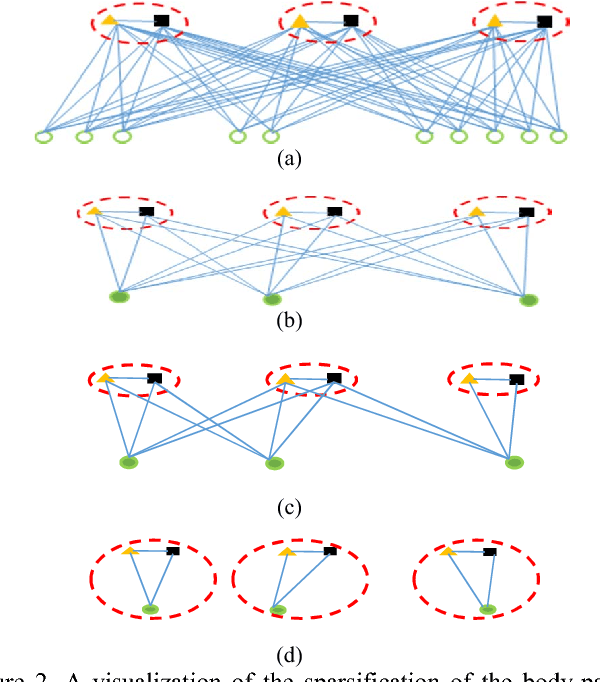
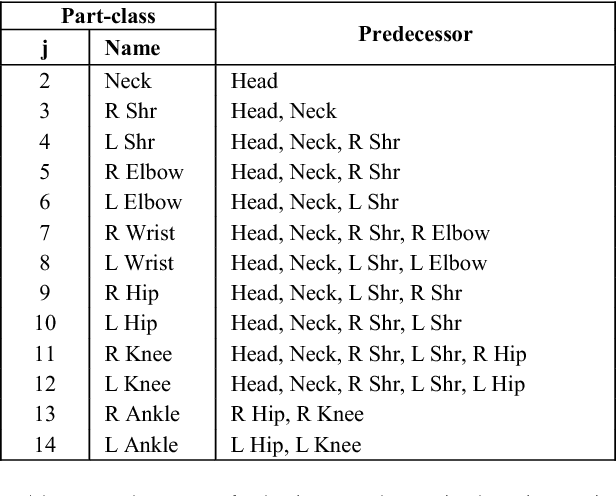
Human pose-estimation in a multi-person image involves detection of various body parts and grouping them into individual person clusters. While the former task is challenging due to mutual occlusions, the combinatorial complexity of the latter task is very high. We propose a greedy part assignment algorithm that exploits the inherent structure of the human body to achieve a lower complexity, compared to any of the prior published works. This is accomplished by (i) reducing the number of part-candidates using the estimated number of people in the image, (ii) doing a greedy sequential assignment of part-classes, following the kinematic chain from head to ankle (iii) doing a greedy assignment of parts in each part-class set, to person-clusters (iv) limiting the candidate person clusters to the most proximal clusters using human anthropometric data and (v) using only a specific subset of pre-assigned parts for establishing pairwise structural constraints. We show that, these steps result in a sparse body parts relationship graph and reduces the complexity. We also propose methods for improving the accuracy of pose-estimation by (i) spawning person-clusters from any unassigned significant body part and (ii) suppressing hallucinated parts. On the MPII multi-person pose database, pose-estimation using the proposed method takes only 0.14 seconds per image. We show that, our proposed algorithm, by using a large spatial and structural context, achieves the state-of-the-art accuracy on both MPII and WAF multi-person pose datasets, demonstrating the robustness of our approach.