 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRate-Distortion Optimization for Transformer Inference
Jan 29, 2026Transformers achieve superior performance on many tasks, but impose heavy compute and memory requirements during inference. This inference can be made more efficient by partitioning the process across multiple devices, which, in turn, requires compressing its intermediate representations. In this work, we introduce a principled rate-distortion-based framework for lossy compression that learns compact encodings that explicitly trade off bitrate against accuracy. Experiments on language benchmarks show that the proposed codec achieves substantial savings with improved accuracy in some cases, outperforming more complex baseline methods. We characterize and analyze the rate-distortion performance of transformers, offering a unified lens for understanding performance in representation coding. This formulation extends information-theoretic concepts to define the gap between rate and entropy, and derive some of its bounds. We further develop probably approximately correct (PAC)-style bounds for estimating this gap. For different architectures and tasks, we empirically demonstrate that their rates are driven by these bounds, adding to the explainability of the formulation.
Lossy Common Information in a Learnable Gray-Wyner Network
Jan 29, 2026Many computer vision tasks share substantial overlapping information, yet conventional codecs tend to ignore this, leading to redundant and inefficient representations. The Gray-Wyner network, a classical concept from information theory, offers a principled framework for separating common and task-specific information. Inspired by this idea, we develop a learnable three-channel codec that disentangles shared information from task-specific details across multiple vision tasks. We characterize the limits of this approach through the notion of lossy common information, and propose an optimization objective that balances inherent tradeoffs in learning such representations. Through comparisons of three codec architectures on two-task scenarios spanning six vision benchmarks, we demonstrate that our approach substantially reduces redundancy and consistently outperforms independent coding. These results highlight the practical value of revisiting Gray-Wyner theory in modern machine learning contexts, bridging classic information theory with task-driven representation learning.
Towards Task-Compatible Compressible Representations
May 16, 2024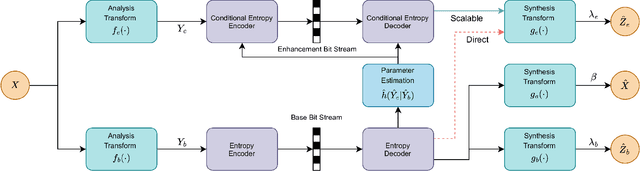
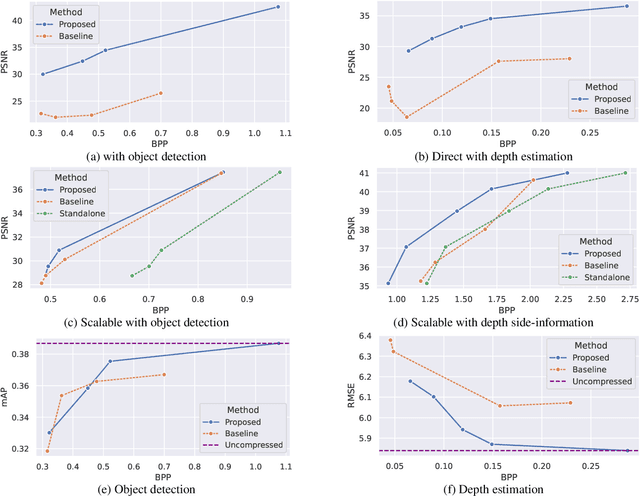
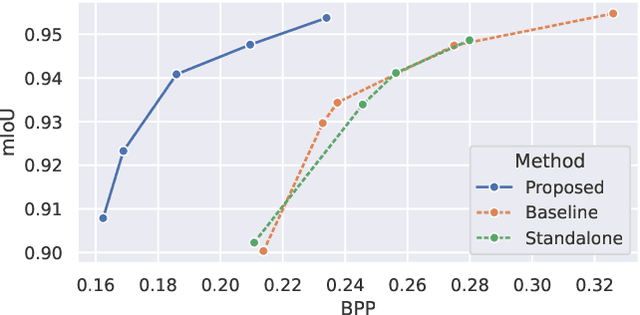
We identify an issue in multi-task learnable compression, in which a representation learned for one task does not positively contribute to the rate-distortion performance of a different task as much as expected, given the estimated amount of information available in it. We interpret this issue using the predictive $\mathcal{V}$-information framework. In learnable scalable coding, previous work increased the utilization of side-information for input reconstruction by also rewarding input reconstruction when learning this shared representation. We evaluate the impact of this idea in the context of input reconstruction more rigorously and extended it to other computer vision tasks. We perform experiments using representations trained for object detection on COCO 2017 and depth estimation on the Cityscapes dataset, and use them to assist in image reconstruction and semantic segmentation tasks. The results show considerable improvements in the rate-distortion performance of the assisted tasks. Moreover, using the proposed representations, the performance of the base tasks are also improved. Results suggest that the proposed method induces simpler representations that are more compatible with downstream processes.
Base Layer Efficiency in Scalable Human-Machine Coding
Jul 05, 2023A basic premise in scalable human-machine coding is that the base layer is intended for automated machine analysis and is therefore more compressible than the same content would be for human viewing. Use cases for such coding include video surveillance and traffic monitoring, where the majority of the content will never be seen by humans. Therefore, base layer efficiency is of paramount importance because the system would most frequently operate at the base-layer rate. In this paper, we analyze the coding efficiency of the base layer in a state-of-the-art scalable human-machine image codec, and show that it can be improved. In particular, we demonstrate that gains of 20-40% in BD-Rate compared to the currently best results on object detection and instance segmentation are possible.
Rate-Distortion Theory in Coding for Machines and its Application
May 26, 2023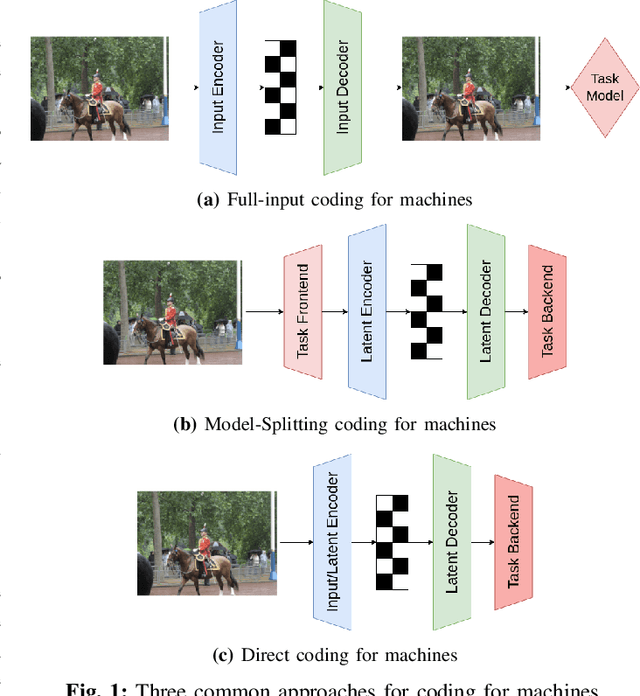
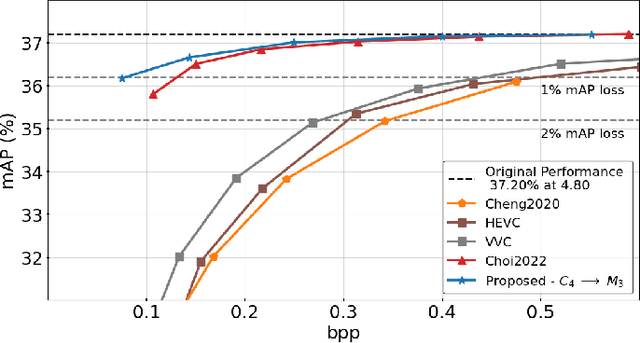
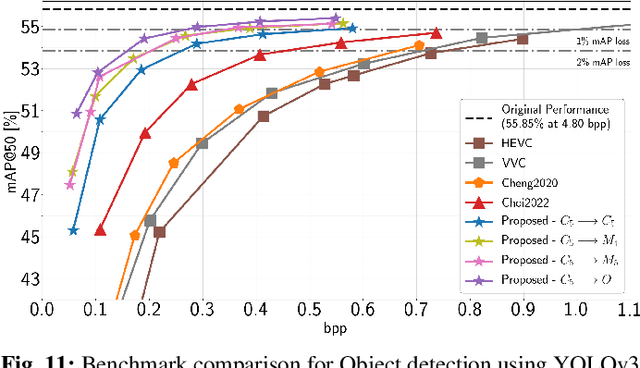
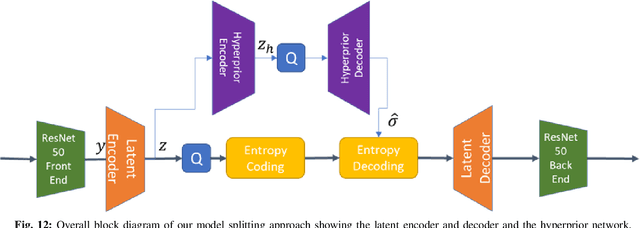
Recent years have seen a tremendous growth in both the capability and popularity of automatic machine analysis of images and video. As a result, a growing need for efficient compression methods optimized for machine vision, rather than human vision, has emerged. To meet this growing demand, several methods have been developed for image and video coding for machines. Unfortunately, while there is a substantial body of knowledge regarding rate-distortion theory for human vision, the same cannot be said of machine analysis. In this paper, we extend the current rate-distortion theory for machines, providing insight into important design considerations of machine-vision codecs. We then utilize this newfound understanding to improve several methods for learnable image coding for machines. Our proposed methods achieve state-of-the-art rate-distortion performance on several computer vision tasks such as classification, instance segmentation, and object detection.
Conditional and Residual Methods in Scalable Coding for Humans and Machines
May 04, 2023We present methods for conditional and residual coding in the context of scalable coding for humans and machines. Our focus is on optimizing the rate-distortion performance of the reconstruction task using the information available in the computer vision task. We include an information analysis of both approaches to provide baselines and also propose an entropy model suitable for conditional coding with increased modelling capacity and similar tractability as previous work. We apply these methods to image reconstruction, using, in one instance, representations created for semantic segmentation on the Cityscapes dataset, and in another instance, representations created for object detection on the COCO dataset. In both experiments, we obtain similar performance between the conditional and residual methods, with the resulting rate-distortion curves contained within our baselines.
Graph Representation Learning Network via Adaptive Sampling
Jun 08, 2020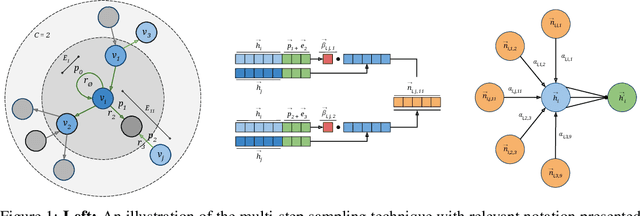
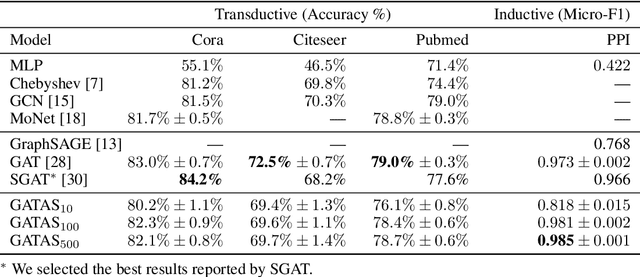
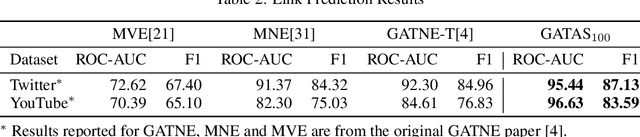
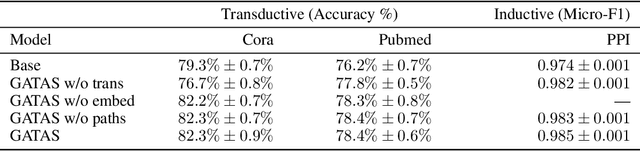
Graph Attention Network (GAT) and GraphSAGE are neural network architectures that operate on graph-structured data and have been widely studied for link prediction and node classification. One challenge raised by GraphSAGE is how to smartly combine neighbour features based on graph structure. GAT handles this problem through attention, however the challenge with GAT is its scalability over large and dense graphs. In this work, we proposed a new architecture to address these issues that is more efficient and is capable of incorporating different edge type information. It generates node representations by attending to neighbours sampled from weighted multi-step transition probabilities. We conduct experiments on both transductive and inductive settings. Experiments achieved comparable or better results on several graph benchmarks, including the Cora, Citeseer, Pubmed, PPI, Twitter, and YouTube datasets.
Best Practices for Convolutional Neural Networks Applied to Object Recognition in Images
Oct 29, 2019
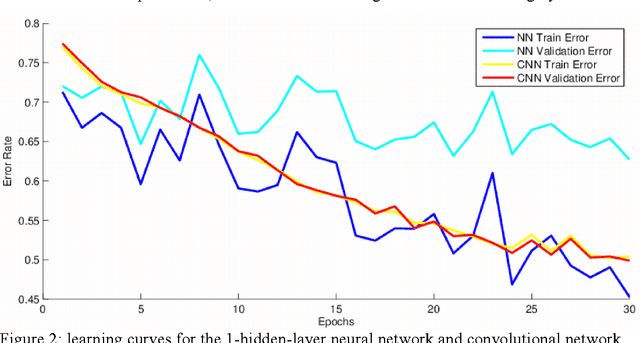
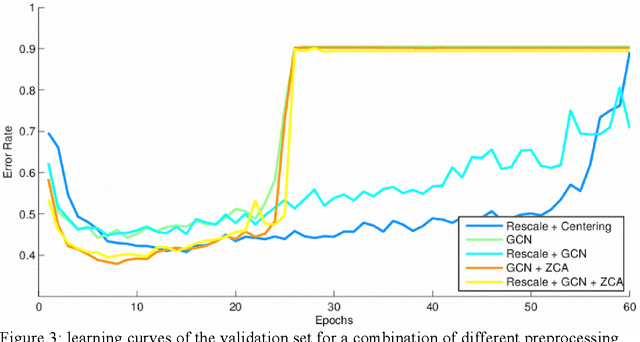
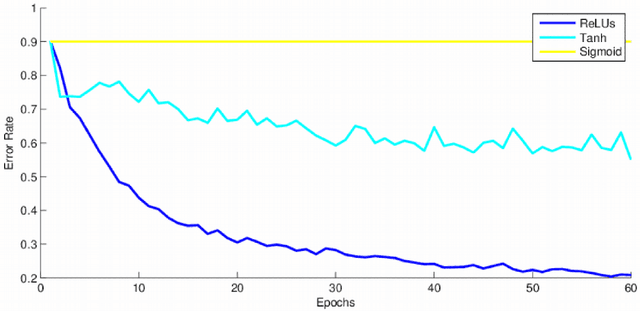
This research project studies the impact of convolutional neural networks (CNN) in image classification tasks. We explore different architectures and training configurations with the use of ReLUs, Nesterov's accelerated gradient, dropout and maxout networks. We work with the CIFAR-10 dataset as part of a Kaggle competition to identify objects in images. Initial results show that CNNs outperform our baseline by acting as invariant feature detectors. Comparisons between different preprocessing procedures show better results for global contrast normalization and ZCA whitening. ReLUs are much faster than tanh units and outperform sigmoids. We provide extensive details about our training hyperparameters, providing intuition for their selection that could help enhance learning in similar situations. We design 4 models of convolutional neural networks that explore characteristics such as depth, number of feature maps, size and overlap of kernels, pooling regions, and different subsampling techniques. Results favor models of moderate depth that use an extensive number of parameters in both convolutional and dense layers. Maxout networks are able to outperform rectifiers on some models but introduce too much noise as the complexity of the fully-connected layers increases. The final discussion explains our results and provides additional techniques that could improve performance.
A Comparison of Neural Network Training Methods for Text Classification
Oct 28, 2019
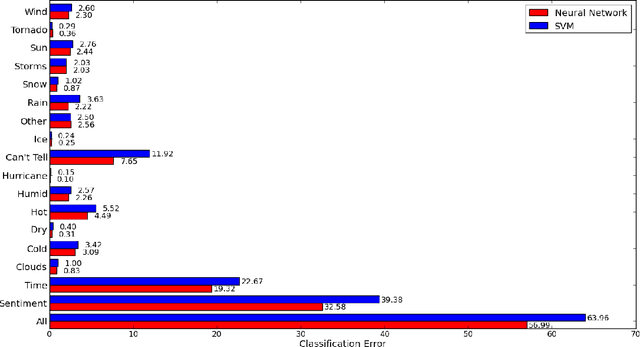
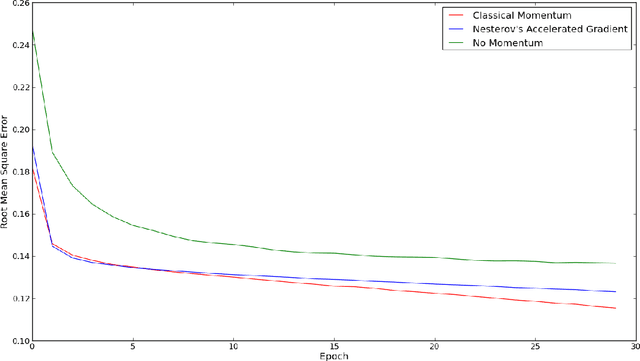
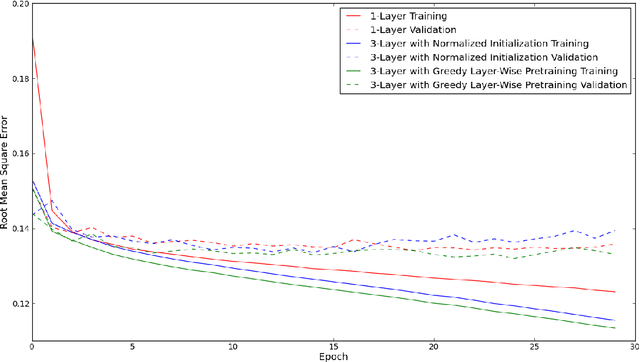
We study the impact of neural networks in text classification. Our focus is on training deep neural networks with proper weight initialization and greedy layer-wise pretraining. Results are compared with 1-layer neural networks and Support Vector Machines. We work with a dataset of labeled messages from the Twitter microblogging service and aim to predict weather conditions. A feature extraction procedure specific for the task is proposed, which applies dimensionality reduction using Latent Semantic Analysis. Our results show that neural networks outperform Support Vector Machines with Gaussian kernels, noticing performance gains from introducing additional hidden layers with nonlinearities. The impact of using Nesterov's Accelerated Gradient in backpropagation is also studied. We conclude that deep neural networks are a reasonable approach for text classification and propose further ideas to improve performance.
DENS: A Dataset for Multi-class Emotion Analysis
Oct 25, 2019


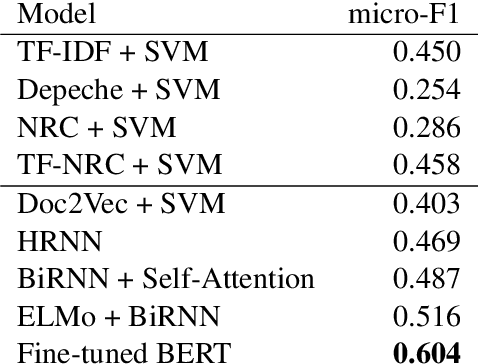
We introduce a new dataset for multi-class emotion analysis from long-form narratives in English. The Dataset for Emotions of Narrative Sequences (DENS) was collected from both classic literature available on Project Gutenberg and modern online narratives available on Wattpad, annotated using Amazon Mechanical Turk. A number of statistics and baseline benchmarks are provided for the dataset. Of the tested techniques, we find that the fine-tuning of a pre-trained BERT model achieves the best results, with an average micro-F1 score of 60.4%. Our results show that the dataset provides a novel opportunity in emotion analysis that requires moving beyond existing sentence-level techniques.