 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Adaptive Extended Chain Coding for Semantic Map Compression
Mar 03, 2026Semantic maps are increasingly utilized in areas such as robotics, autonomous systems, and extended reality, motivating the investigation of efficient compression methods that preserve structured semantic information. This paper studies lossless compression of semantic maps through a novel chain-coding-based framework that explicitly exploits contour topology and shared boundaries between adjacent semantic regions. We propose an extended chain code (ECC) to represent long-range contour transitions more compactly, while retaining a legacy three-orthogonal chain code (3OT) as a fallback mode for further efficiency. To efficiently encode sequences of ECC symbols, a context-adaptive entropy coding scheme based on Markov modeling is employed. Furthermore, a skip-coding mechanism is introduced to eliminate redundant representations of shared contours between adjacent semantic regions, supporting both complete and partial skips via run-length signaling. Experimental results demonstrate that the proposed method achieves an average bitrate reduction of 18\% compared with a state-of-the-art benchmark on semantic map datasets. In addition, the proposed encoder and decoder achieve up to 98\% and 50\% runtime reduction, respectively, relative to a modern generic lossless codec. Extended evaluations on occupancy maps further confirm consistent compression gains across the majority of tested scenarios.
Rate-Distortion Optimization for Transformer Inference
Jan 29, 2026Transformers achieve superior performance on many tasks, but impose heavy compute and memory requirements during inference. This inference can be made more efficient by partitioning the process across multiple devices, which, in turn, requires compressing its intermediate representations. In this work, we introduce a principled rate-distortion-based framework for lossy compression that learns compact encodings that explicitly trade off bitrate against accuracy. Experiments on language benchmarks show that the proposed codec achieves substantial savings with improved accuracy in some cases, outperforming more complex baseline methods. We characterize and analyze the rate-distortion performance of transformers, offering a unified lens for understanding performance in representation coding. This formulation extends information-theoretic concepts to define the gap between rate and entropy, and derive some of its bounds. We further develop probably approximately correct (PAC)-style bounds for estimating this gap. For different architectures and tasks, we empirically demonstrate that their rates are driven by these bounds, adding to the explainability of the formulation.
Lossy Common Information in a Learnable Gray-Wyner Network
Jan 29, 2026Many computer vision tasks share substantial overlapping information, yet conventional codecs tend to ignore this, leading to redundant and inefficient representations. The Gray-Wyner network, a classical concept from information theory, offers a principled framework for separating common and task-specific information. Inspired by this idea, we develop a learnable three-channel codec that disentangles shared information from task-specific details across multiple vision tasks. We characterize the limits of this approach through the notion of lossy common information, and propose an optimization objective that balances inherent tradeoffs in learning such representations. Through comparisons of three codec architectures on two-task scenarios spanning six vision benchmarks, we demonstrate that our approach substantially reduces redundancy and consistently outperforms independent coding. These results highlight the practical value of revisiting Gray-Wyner theory in modern machine learning contexts, bridging classic information theory with task-driven representation learning.
Semantics-Guided Generative Image Compression
May 29, 2025Advancements in text-to-image generative AI with large multimodal models are spreading into the field of image compression, creating high-quality representation of images at extremely low bit rates. This work introduces novel components to the existing multimodal image semantic compression (MISC) approach, enhancing the quality of the generated images in terms of PSNR and perceptual metrics. The new components include semantic segmentation guidance for the generative decoder, as well as content-adaptive diffusion, which controls the number of diffusion steps based on image characteristics. The results show that our newly introduced methods significantly improve the baseline MISC model while also decreasing the complexity. As a result, both the encoding and decoding time are reduced by more than 36%. Moreover, the proposed compression framework outperforms mainstream codecs in terms of perceptual similarity and quality. The code and visual examples are available.
Rate-Accuracy Bounds in Visual Coding for Machines
May 20, 2025Increasingly, visual signals such as images, videos and point clouds are being captured solely for the purpose of automated analysis by computer vision models. Applications include traffic monitoring, robotics, autonomous driving, smart home, and many others. This trend has led to the need to develop compression strategies for these signals for the purpose of analysis rather than reconstruction, an area often referred to as "coding for machines." By drawing parallels with lossy coding of a discrete memoryless source, in this paper we derive rate-accuracy bounds on several popular problems in visual coding for machines, and compare these with state-of-the-art results from the literature. The comparison shows that the current results are at least an order of magnitude -- and in some cases two or three orders of magnitude -- away from the theoretical bounds in terms of the bitrate needed to achieve a certain level of accuracy. This, in turn, means that there is much room for improvement in the current methods for visual coding for machines.
SplitFedZip: Learned Compression for Data Transfer Reduction in Split-Federated Learning
Dec 18, 2024Federated Learning (FL) enables multiple clients to train a collaborative model without sharing their local data. Split Learning (SL) allows a model to be trained in a split manner across different locations. Split-Federated (SplitFed) learning is a more recent approach that combines the strengths of FL and SL. SplitFed minimizes the computational burden of FL by balancing computation across clients and servers, while still preserving data privacy. This makes it an ideal learning framework across various domains, especially in healthcare, where data privacy is of utmost importance. However, SplitFed networks encounter numerous communication challenges, such as latency, bandwidth constraints, synchronization overhead, and a large amount of data that needs to be transferred during the learning process. In this paper, we propose SplitFedZip -- a novel method that employs learned compression to reduce data transfer in SplitFed learning. Through experiments on medical image segmentation, we show that learned compression can provide a significant data communication reduction in SplitFed learning, while maintaining the accuracy of the final trained model. The implementation is available at: \url{https://github.com/ChamaniS/SplitFedZip}.
Learned Multimodal Compression for Autonomous Driving
Aug 15, 2024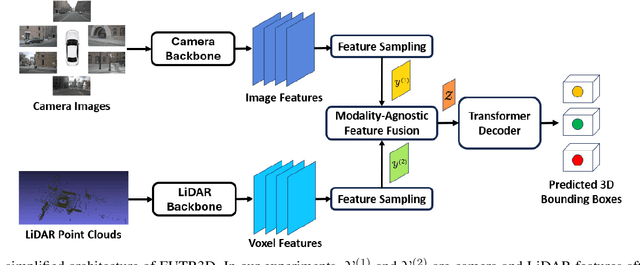
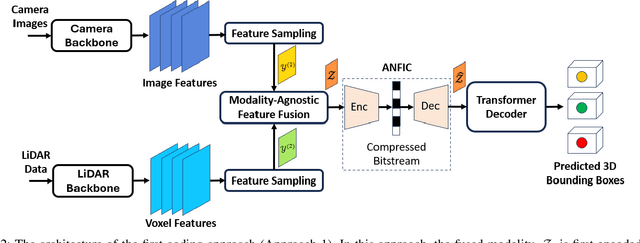
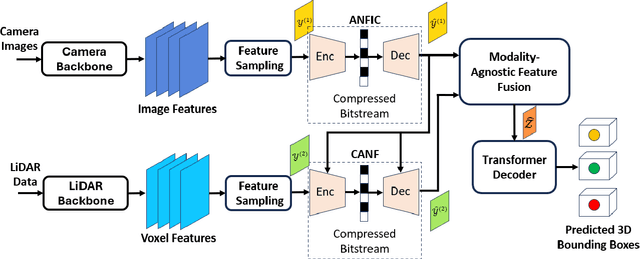
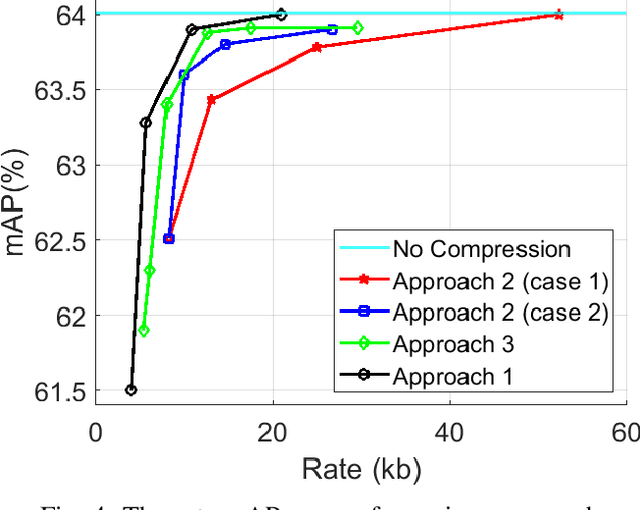
Autonomous driving sensors generate an enormous amount of data. In this paper, we explore learned multimodal compression for autonomous driving, specifically targeted at 3D object detection. We focus on camera and LiDAR modalities and explore several coding approaches. One approach involves joint coding of fused modalities, while others involve coding one modality first, followed by conditional coding of the other modality. We evaluate the performance of these coding schemes on the nuScenes dataset. Our experimental results indicate that joint coding of fused modalities yields better results compared to the alternatives.
Learned Compression of Encoding Distributions
Jun 18, 2024The entropy bottleneck introduced by Ball\'e et al. is a common component used in many learned compression models. It encodes a transformed latent representation using a static distribution whose parameters are learned during training. However, the actual distribution of the latent data may vary wildly across different inputs. The static distribution attempts to encompass all possible input distributions, thus fitting none of them particularly well. This unfortunate phenomenon, sometimes known as the amortization gap, results in suboptimal compression. To address this issue, we propose a method that dynamically adapts the encoding distribution to match the latent data distribution for a specific input. First, our model estimates a better encoding distribution for a given input. This distribution is then compressed and transmitted as an additional side-information bitstream. Finally, the decoder reconstructs the encoding distribution and uses it to decompress the corresponding latent data. Our method achieves a Bj{\o}ntegaard-Delta (BD)-rate gain of -7.10% on the Kodak test dataset when applied to the standard fully-factorized architecture. Furthermore, considering computational complexity, the transform used by our method is an order of magnitude cheaper in terms of Multiply-Accumulate (MAC) operations compared to related side-information methods such as the scale hyperprior.
Optimizing Split Points for Error-Resilient SplitFed Learning
May 29, 2024Recent advancements in decentralized learning, such as Federated Learning (FL), Split Learning (SL), and Split Federated Learning (SplitFed), have expanded the potentials of machine learning. SplitFed aims to minimize the computational burden on individual clients in FL and parallelize SL while maintaining privacy. This study investigates the resilience of SplitFed to packet loss at model split points. It explores various parameter aggregation strategies of SplitFed by examining the impact of splitting the model at different points-either shallow split or deep split-on the final global model performance. The experiments, conducted on a human embryo image segmentation task, reveal a statistically significant advantage of a deeper split point.
Mutual Information Analysis in Multimodal Learning Systems
May 21, 2024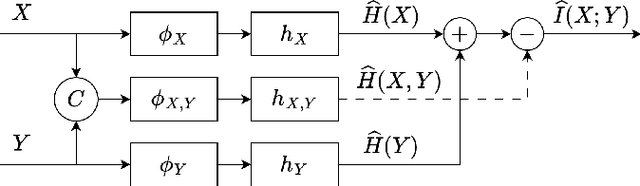
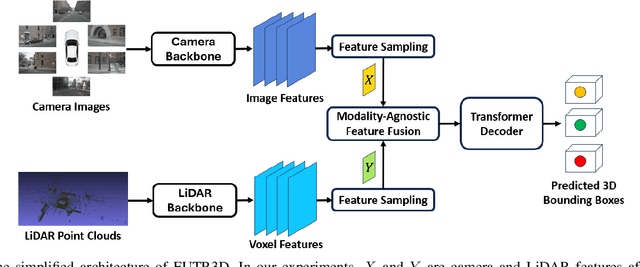


In recent years, there has been a significant increase in applications of multimodal signal processing and analysis, largely driven by the increased availability of multimodal datasets and the rapid progress in multimodal learning systems. Well-known examples include autonomous vehicles, audiovisual generative systems, vision-language systems, and so on. Such systems integrate multiple signal modalities: text, speech, images, video, LiDAR, etc., to perform various tasks. A key issue for understanding such systems is the relationship between various modalities and how it impacts task performance. In this paper, we employ the concept of mutual information (MI) to gain insight into this issue. Taking advantage of the recent progress in entropy modeling and estimation, we develop a system called InfoMeter to estimate MI between modalities in a multimodal learning system. We then apply InfoMeter to analyze a multimodal 3D object detection system over a large-scale dataset for autonomous driving. Our experiments on this system suggest that a lower MI between modalities is beneficial for detection accuracy. This new insight may facilitate improvements in the development of future multimodal learning systems.