Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Multimodal Compression for Autonomous Driving
Paper and Code
Aug 15, 2024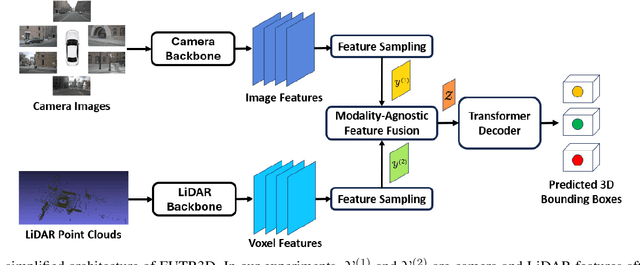
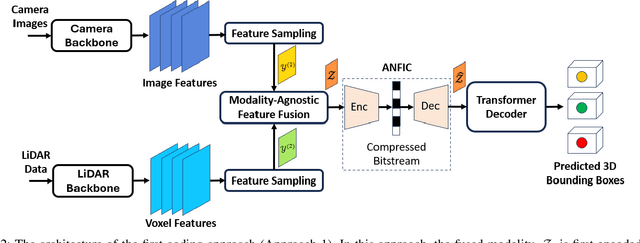
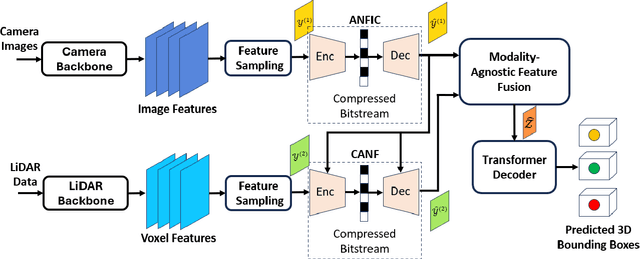
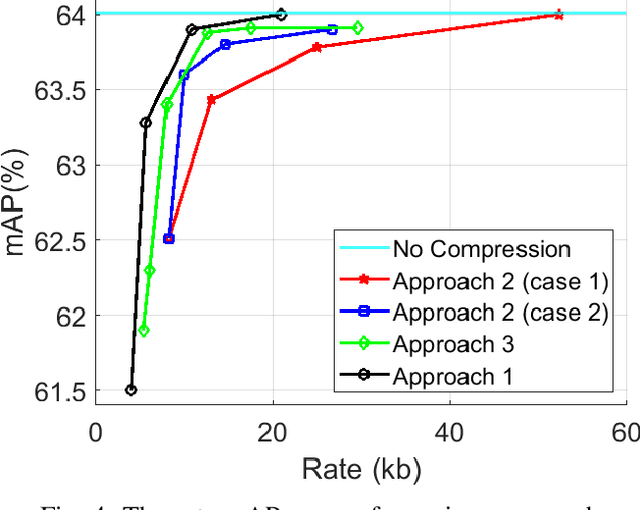
Autonomous driving sensors generate an enormous amount of data. In this paper, we explore learned multimodal compression for autonomous driving, specifically targeted at 3D object detection. We focus on camera and LiDAR modalities and explore several coding approaches. One approach involves joint coding of fused modalities, while others involve coding one modality first, followed by conditional coding of the other modality. We evaluate the performance of these coding schemes on the nuScenes dataset. Our experimental results indicate that joint coding of fused modalities yields better results compared to the alternatives.
* 6 pages, 5 figures, IEEE MMSP 2024
View paper on