 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuCALD-SplitFed: Causal-Latent Diffusion for Privacy-Preserving Multi-Task Split-Federated Medical Image Segmentation
May 04, 2026Federated Learning enables decentralized training by aggregating model updates across clients without sharing raw data, while Split Federated Learning further partitions the model between clients and a server to reduce computation and communication at the client side. However, decentralized medical institutions rarely operate on a single shared task, making standard Federated and SplitFed collaborations poorly aligned with real clinical workflows. Multi-task FL extends these frameworks by allowing clients to handle different tasks, but often introduces instability and privacy vulnerabilities. This study proposes \textbf{MuCALD-SplitFed}, a multi-task SplitFed framework that integrates causal representation learning and latent diffusion. Experiments show MuCALD-SplitFed consistently improves segmentation, while baseline SplitFed fails to converge. The proposed approach further reduces information leakage at split points, mitigating reconstruction-based and membership inference attacks. Additionally, MuCALD SplitFed outperforms state-of-the-art personalized FL and multi-task FL approaches. The code repository is: https://github.com/ChamaniS/MuCALD_SplitFed.
MedSegNet10: A Publicly Accessible Network Repository for Split Federated Medical Image Segmentation
Mar 26, 2025



Machine Learning (ML) and Deep Learning (DL) have shown significant promise in healthcare, particularly in medical image segmentation, which is crucial for accurate disease diagnosis and treatment planning. Despite their potential, challenges such as data privacy concerns, limited annotated data, and inadequate training data persist. Decentralized learning approaches such as federated learning (FL), split learning (SL), and split federated learning (SplitFed/SFL) address these issues effectively. This paper introduces "MedSegNet10," a publicly accessible repository designed for medical image segmentation using split-federated learning. MedSegNet10 provides a collection of pre-trained neural network architectures optimized for various medical image types, including microscopic images of human blastocysts, dermatoscopic images of skin lesions, and endoscopic images of lesions, polyps, and ulcers, with applications extending beyond these examples. By leveraging SplitFed's benefits, MedSegNet10 allows collaborative training on privately stored, horizontally split data, ensuring privacy and integrity. This repository supports researchers, practitioners, trainees, and data scientists, aiming to advance medical image segmentation while maintaining patient data privacy. The repository is available at: https://vault.sfu.ca/index.php/s/ryhf6t12O0sobuX (password upon request to the authors).
SplitFedZip: Learned Compression for Data Transfer Reduction in Split-Federated Learning
Dec 18, 2024Federated Learning (FL) enables multiple clients to train a collaborative model without sharing their local data. Split Learning (SL) allows a model to be trained in a split manner across different locations. Split-Federated (SplitFed) learning is a more recent approach that combines the strengths of FL and SL. SplitFed minimizes the computational burden of FL by balancing computation across clients and servers, while still preserving data privacy. This makes it an ideal learning framework across various domains, especially in healthcare, where data privacy is of utmost importance. However, SplitFed networks encounter numerous communication challenges, such as latency, bandwidth constraints, synchronization overhead, and a large amount of data that needs to be transferred during the learning process. In this paper, we propose SplitFedZip -- a novel method that employs learned compression to reduce data transfer in SplitFed learning. Through experiments on medical image segmentation, we show that learned compression can provide a significant data communication reduction in SplitFed learning, while maintaining the accuracy of the final trained model. The implementation is available at: \url{https://github.com/ChamaniS/SplitFedZip}.
Learned Multimodal Compression for Autonomous Driving
Aug 15, 2024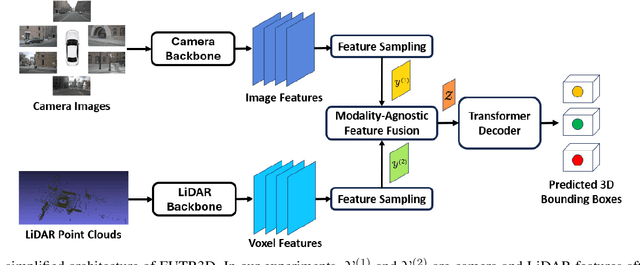
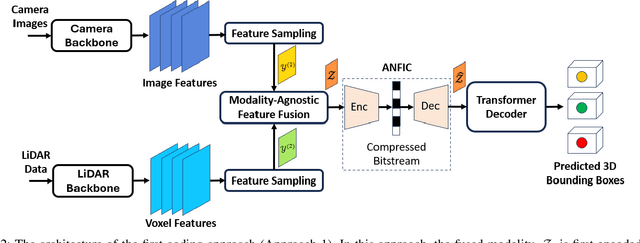
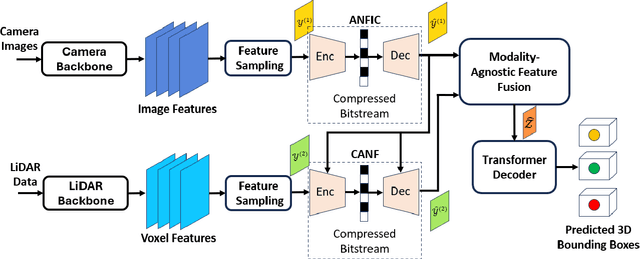
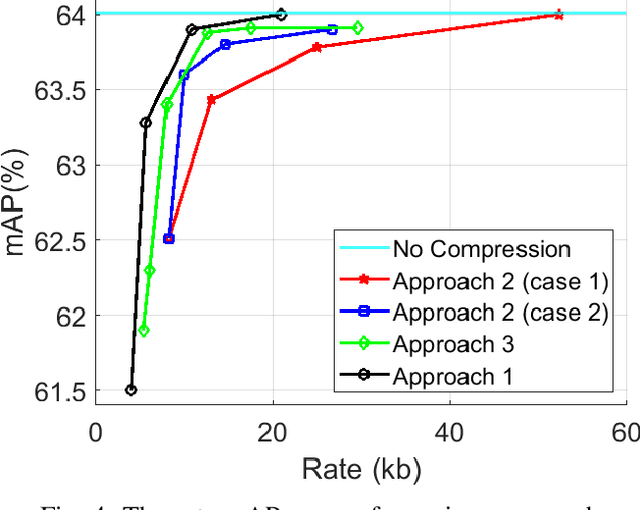
Autonomous driving sensors generate an enormous amount of data. In this paper, we explore learned multimodal compression for autonomous driving, specifically targeted at 3D object detection. We focus on camera and LiDAR modalities and explore several coding approaches. One approach involves joint coding of fused modalities, while others involve coding one modality first, followed by conditional coding of the other modality. We evaluate the performance of these coding schemes on the nuScenes dataset. Our experimental results indicate that joint coding of fused modalities yields better results compared to the alternatives.
Unsupervised Video Summarization via Reinforcement Learning and a Trained Evaluator
Jul 05, 2024This paper presents a novel approach for unsupervised video summarization using reinforcement learning. It aims to address the existing limitations of current unsupervised methods, including unstable training of adversarial generator-discriminator architectures and reliance on hand-crafted reward functions for quality evaluation. The proposed method is based on the concept that a concise and informative summary should result in a reconstructed video that closely resembles the original. The summarizer model assigns an importance score to each frame and generates a video summary. In the proposed scheme, reinforcement learning, coupled with a unique reward generation pipeline, is employed to train the summarizer model. The reward generation pipeline trains the summarizer to create summaries that lead to improved reconstructions. It comprises a generator model capable of reconstructing masked frames from a partially masked video, along with a reward mechanism that compares the reconstructed video from the summary against the original. The video generator is trained in a self-supervised manner to reconstruct randomly masked frames, enhancing its ability to generate accurate summaries. This training pipeline results in a summarizer model that better mimics human-generated video summaries compared to methods relying on hand-crafted rewards. The training process consists of two stable and isolated training steps, unlike adversarial architectures. Experimental results demonstrate promising performance, with F-scores of 62.3 and 54.5 on TVSum and SumMe datasets, respectively. Additionally, the inference stage is 300 times faster than our previously reported state-of-the-art method.
Mutual Information Analysis in Multimodal Learning Systems
May 21, 2024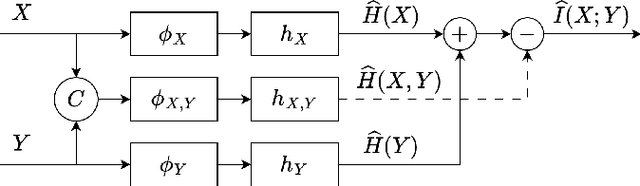
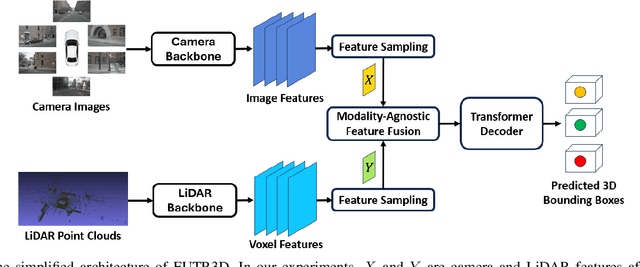


In recent years, there has been a significant increase in applications of multimodal signal processing and analysis, largely driven by the increased availability of multimodal datasets and the rapid progress in multimodal learning systems. Well-known examples include autonomous vehicles, audiovisual generative systems, vision-language systems, and so on. Such systems integrate multiple signal modalities: text, speech, images, video, LiDAR, etc., to perform various tasks. A key issue for understanding such systems is the relationship between various modalities and how it impacts task performance. In this paper, we employ the concept of mutual information (MI) to gain insight into this issue. Taking advantage of the recent progress in entropy modeling and estimation, we develop a system called InfoMeter to estimate MI between modalities in a multimodal learning system. We then apply InfoMeter to analyze a multimodal 3D object detection system over a large-scale dataset for autonomous driving. Our experiments on this system suggest that a lower MI between modalities is beneficial for detection accuracy. This new insight may facilitate improvements in the development of future multimodal learning systems.
Learned Scalable Video Coding For Humans and Machines
Jul 18, 2023Video coding has traditionally been developed to support services such as video streaming, videoconferencing, digital TV, and so on. The main intent was to enable human viewing of the encoded content. However, with the advances in deep neural networks (DNNs), encoded video is increasingly being used for automatic video analytics performed by machines. In applications such as automatic traffic monitoring, analytics such as vehicle detection, tracking and counting, would run continuously, while human viewing could be required occasionally to review potential incidents. To support such applications, a new paradigm for video coding is needed that will facilitate efficient representation and compression of video for both machine and human use in a scalable manner. In this manuscript, we introduce the first end-to-end learnable video codec that supports a machine vision task in its base layer, while its enhancement layer supports input reconstruction for human viewing. The proposed system is constructed based on the concept of conditional coding to achieve better compression gains. Comprehensive experimental evaluations conducted on four standard video datasets demonstrate that our framework outperforms both state-of-the-art learned and conventional video codecs in its base layer, while maintaining comparable performance on the human vision task in its enhancement layer. We will provide the implementation of the proposed system at www.github.com upon completion of the review process.
LCCM-VC: Learned Conditional Coding Modes for Video Coding
Oct 28, 2022End-to-end learning-based video compression has made steady progress over the last several years. However, unlike learning-based image coding, which has already surpassed its handcrafted counterparts, learning-based video coding still has some ways to go. In this paper we present learned conditional coding modes for video coding (LCCM-VC), a video coding model that achieves state-of-the-art results among learning-based video coding methods. Our model utilizes conditional coding engines from the recent conditional augmented normalizing flows (CANF) pipeline, and introduces additional coding modes to improve compression performance. The compression efficiency is especially good in the high-quality/high-bitrate range, which is important for broadcast and video-on-demand streaming applications. We will provide the code of the proposed model at www.github.com upon completion of the review process.