 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Split-Federated Learning over Noisy Channels for Embryo Image Segmentation
Jan 26, 2026Split-Federated (SplitFed) learning is an extension of federated learning that places minimal requirements on the clients computing infrastructure, since only a small portion of the overall model is deployed on the clients hardware. In SplitFed learning, feature values, gradient updates, and model updates are transferred across communication channels. In this paper, we study the effects of noise in the communication channels on the learning process and the quality of the final model. We propose a smart averaging strategy for SplitFed learning with the goal of improving resilience against channel noise. Experiments on a segmentation model for embryo images shows that the proposed smart averaging strategy is able to tolerate two orders of magnitude stronger noise in the communication channels compared to conventional averaging, while still maintaining the accuracy of the final model.
MedSegNet10: A Publicly Accessible Network Repository for Split Federated Medical Image Segmentation
Mar 26, 2025



Machine Learning (ML) and Deep Learning (DL) have shown significant promise in healthcare, particularly in medical image segmentation, which is crucial for accurate disease diagnosis and treatment planning. Despite their potential, challenges such as data privacy concerns, limited annotated data, and inadequate training data persist. Decentralized learning approaches such as federated learning (FL), split learning (SL), and split federated learning (SplitFed/SFL) address these issues effectively. This paper introduces "MedSegNet10," a publicly accessible repository designed for medical image segmentation using split-federated learning. MedSegNet10 provides a collection of pre-trained neural network architectures optimized for various medical image types, including microscopic images of human blastocysts, dermatoscopic images of skin lesions, and endoscopic images of lesions, polyps, and ulcers, with applications extending beyond these examples. By leveraging SplitFed's benefits, MedSegNet10 allows collaborative training on privately stored, horizontally split data, ensuring privacy and integrity. This repository supports researchers, practitioners, trainees, and data scientists, aiming to advance medical image segmentation while maintaining patient data privacy. The repository is available at: https://vault.sfu.ca/index.php/s/ryhf6t12O0sobuX (password upon request to the authors).
SplitFedZip: Learned Compression for Data Transfer Reduction in Split-Federated Learning
Dec 18, 2024Federated Learning (FL) enables multiple clients to train a collaborative model without sharing their local data. Split Learning (SL) allows a model to be trained in a split manner across different locations. Split-Federated (SplitFed) learning is a more recent approach that combines the strengths of FL and SL. SplitFed minimizes the computational burden of FL by balancing computation across clients and servers, while still preserving data privacy. This makes it an ideal learning framework across various domains, especially in healthcare, where data privacy is of utmost importance. However, SplitFed networks encounter numerous communication challenges, such as latency, bandwidth constraints, synchronization overhead, and a large amount of data that needs to be transferred during the learning process. In this paper, we propose SplitFedZip -- a novel method that employs learned compression to reduce data transfer in SplitFed learning. Through experiments on medical image segmentation, we show that learned compression can provide a significant data communication reduction in SplitFed learning, while maintaining the accuracy of the final trained model. The implementation is available at: \url{https://github.com/ChamaniS/SplitFedZip}.
Unsupervised Video Summarization via Reinforcement Learning and a Trained Evaluator
Jul 05, 2024This paper presents a novel approach for unsupervised video summarization using reinforcement learning. It aims to address the existing limitations of current unsupervised methods, including unstable training of adversarial generator-discriminator architectures and reliance on hand-crafted reward functions for quality evaluation. The proposed method is based on the concept that a concise and informative summary should result in a reconstructed video that closely resembles the original. The summarizer model assigns an importance score to each frame and generates a video summary. In the proposed scheme, reinforcement learning, coupled with a unique reward generation pipeline, is employed to train the summarizer model. The reward generation pipeline trains the summarizer to create summaries that lead to improved reconstructions. It comprises a generator model capable of reconstructing masked frames from a partially masked video, along with a reward mechanism that compares the reconstructed video from the summary against the original. The video generator is trained in a self-supervised manner to reconstruct randomly masked frames, enhancing its ability to generate accurate summaries. This training pipeline results in a summarizer model that better mimics human-generated video summaries compared to methods relying on hand-crafted rewards. The training process consists of two stable and isolated training steps, unlike adversarial architectures. Experimental results demonstrate promising performance, with F-scores of 62.3 and 54.5 on TVSum and SumMe datasets, respectively. Additionally, the inference stage is 300 times faster than our previously reported state-of-the-art method.
Optimizing Split Points for Error-Resilient SplitFed Learning
May 29, 2024Recent advancements in decentralized learning, such as Federated Learning (FL), Split Learning (SL), and Split Federated Learning (SplitFed), have expanded the potentials of machine learning. SplitFed aims to minimize the computational burden on individual clients in FL and parallelize SL while maintaining privacy. This study investigates the resilience of SplitFed to packet loss at model split points. It explores various parameter aggregation strategies of SplitFed by examining the impact of splitting the model at different points-either shallow split or deep split-on the final global model performance. The experiments, conducted on a human embryo image segmentation task, reveal a statistically significant advantage of a deeper split point.
SplitFed resilience to packet loss: Where to split, that is the question
Jul 25, 2023Decentralized machine learning has broadened its scope recently with the invention of Federated Learning (FL), Split Learning (SL), and their hybrids like Split Federated Learning (SplitFed or SFL). The goal of SFL is to reduce the computational power required by each client in FL and parallelize SL while maintaining privacy. This paper investigates the robustness of SFL against packet loss on communication links. The performance of various SFL aggregation strategies is examined by splitting the model at two points -- shallow split and deep split -- and testing whether the split point makes a statistically significant difference to the accuracy of the final model. Experiments are carried out on a segmentation model for human embryo images and indicate the statistically significant advantage of a deeper split point.
Quality-Adaptive Split-Federated Learning for Segmenting Medical Images with Inaccurate Annotations
Apr 28, 2023SplitFed Learning, a combination of Federated and Split Learning (FL and SL), is one of the most recent developments in the decentralized machine learning domain. In SplitFed learning, a model is trained by clients and a server collaboratively. For image segmentation, labels are created at each client independently and, therefore, are subject to clients' bias, inaccuracies, and inconsistencies. In this paper, we propose a data quality-based adaptive averaging strategy for SplitFed learning, called QA-SplitFed, to cope with the variation of annotated ground truth (GT) quality over multiple clients. The proposed method is compared against five state-of-the-art model averaging methods on the task of learning human embryo image segmentation. Our experiments show that all five baseline methods fail to maintain accuracy as the number of corrupted clients increases. QA-SplitFed, however, copes effectively with corruption as long as there is at least one uncorrupted client.
Enhancing Multivariate Time Series Classifiers through Self-Attention and Relative Positioning Infusion
Feb 13, 2023Time Series Classification (TSC) is an important and challenging task for many visual computing applications. Despite the extensive range of methods developed for TSC, relatively few utilized Deep Neural Networks (DNNs). In this paper, we propose two novel attention blocks (Global Temporal Attention and Temporal Pseudo-Gaussian augmented Self-Attention) that can enhance deep learning-based TSC approaches, even when such approaches are designed and optimized for a specific dataset or task. We validate this claim by evaluating multiple state-of-the-art deep learning-based TSC models on the University of East Anglia (UEA) benchmark, a standardized collection of 30 Multivariate Time Series Classification (MTSC) datasets. We show that adding the proposed attention blocks improves base models' average accuracy by up to 3.6%. Additionally, the proposed TPS block uses a new injection module to include the relative positional information in transformers. As a standalone unit with less computational complexity, it enables TPS to perform better than most of the state-of-the-art DNN-based TSC methods. The source codes for our experimental setups and proposed attention blocks are made publicly available.
Illumination-Invariant Image from 4-Channel Images: The Effect of Near-Infrared Data in Shadow Removal
May 04, 2020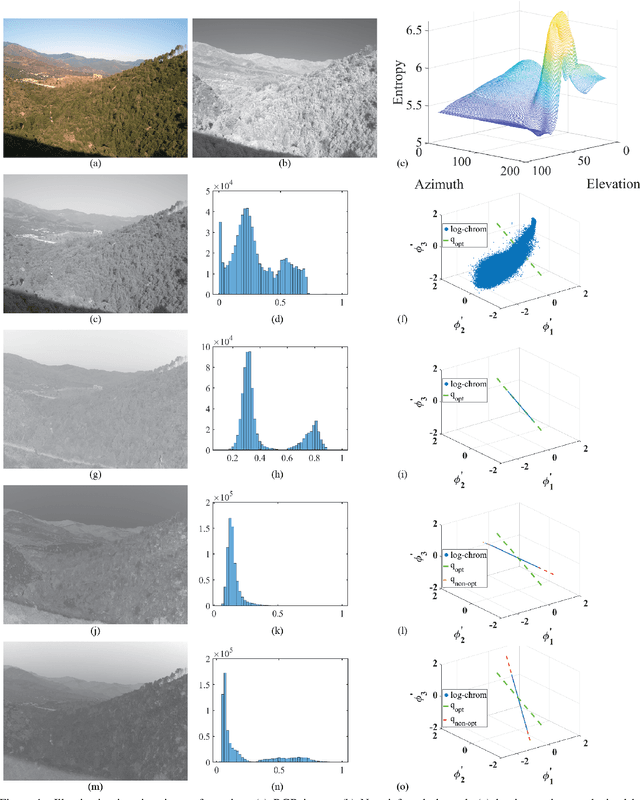
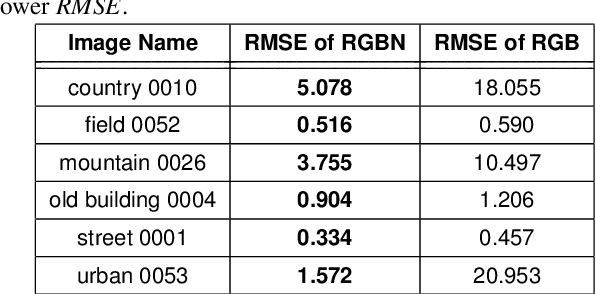

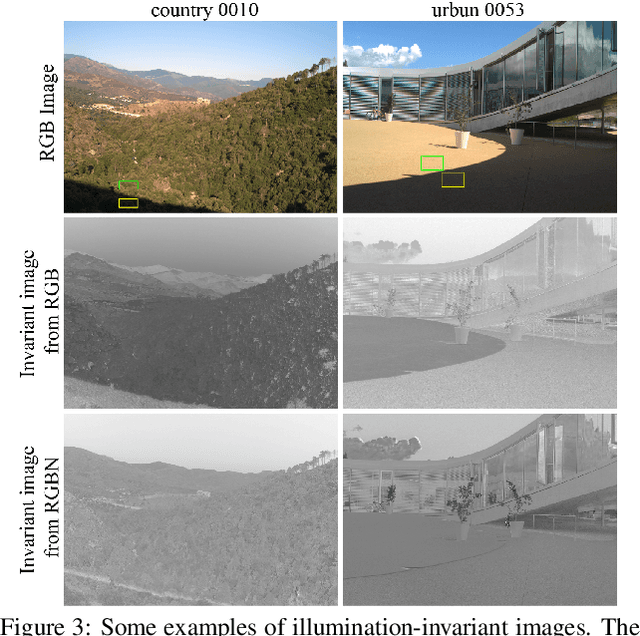
Removing the effect of illumination variation in images has been proved to be beneficial in many computer vision applications such as object recognition and semantic segmentation. Although generating illumination-invariant images has been studied in the literature before, it has not been investigated on real 4-channel (4D) data. In this study, we examine the quality of illumination-invariant images generated from red, green, blue, and near-infrared (RGBN) data. Our experiments show that the near-infrared channel substantively contributes toward removing illumination. As shown in our numerical and visual results, the illumination-invariant image obtained by RGBN data is superior compared to that obtained by RGB alone.
Cloud-Net+: A Cloud Segmentation CNN for Landsat 8 Remote Sensing Imagery Optimized with Filtered Jaccard Loss Function
Jan 23, 2020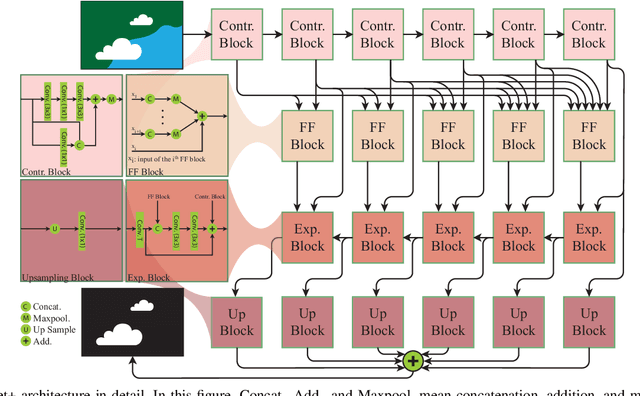


Cloud Segmentation is one of the fundamental steps in optical remote sensing image analysis. Current methods for identification of cloud regions in aerial or satellite images are not accurate enough especially in the presence of snow and haze. This paper presents a deep learning-based framework to address the problem of cloud detection in Landsat 8 imagery. The proposed method benefits from a convolutional neural network (Cloud-Net+) with multiple blocks, which is trained with a novel loss function (Filtered Jaccard loss). The proposed loss function is more sensitive to the absence of cloud pixels in an image and penalizes/rewards the predicted mask more accurately. The combination of Cloud-Net+ and Filtered Jaccard loss function delivers superior results over four public cloud detection datasets. Our experiments on one of the most common public datasets in computer vision (Pascal VOC dataset) show that the proposed network/loss function could be used in other segmentation tasks for more accurate performance/evaluation.