 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Adaptive Extended Chain Coding for Semantic Map Compression
Mar 03, 2026Semantic maps are increasingly utilized in areas such as robotics, autonomous systems, and extended reality, motivating the investigation of efficient compression methods that preserve structured semantic information. This paper studies lossless compression of semantic maps through a novel chain-coding-based framework that explicitly exploits contour topology and shared boundaries between adjacent semantic regions. We propose an extended chain code (ECC) to represent long-range contour transitions more compactly, while retaining a legacy three-orthogonal chain code (3OT) as a fallback mode for further efficiency. To efficiently encode sequences of ECC symbols, a context-adaptive entropy coding scheme based on Markov modeling is employed. Furthermore, a skip-coding mechanism is introduced to eliminate redundant representations of shared contours between adjacent semantic regions, supporting both complete and partial skips via run-length signaling. Experimental results demonstrate that the proposed method achieves an average bitrate reduction of 18\% compared with a state-of-the-art benchmark on semantic map datasets. In addition, the proposed encoder and decoder achieve up to 98\% and 50\% runtime reduction, respectively, relative to a modern generic lossless codec. Extended evaluations on occupancy maps further confirm consistent compression gains across the majority of tested scenarios.
Wrapper-Aware Rate-Distortion Optimization in Feature Coding for Machines
Jan 29, 2026Feature coding for machines (FCM) is a lossy compression paradigm for split-inference. The transmitter encodes the outputs of the first part of a neural network before sending them to the receiver for completing the inference. Practical FCM methods ``sandwich'' a traditional codec between pre- and post-processing neural networks, called wrappers, to make features easier to compress using video codecs. Since traditional codecs are non-differentiable, the wrappers are trained using a proxy codec, which is later replaced by a standard codec after training. These codecs perform rate-distortion optimization (RDO) based on the sum of squared errors (SSE). Because the RDO does not consider the post-processing wrapper, the inner codec can invest bits in preserving information that the post-processing later discards. In this paper, we modify the bit-allocation in the inner codec via a wrapper-aware weighted SSE metric. To make wrapper-aware RDO (WA-RDO) practical for FCM, we propose: 1) temporal reuse of weights across a group of pictures and 2) fixed, architecture- and task-dependent weights trained offline. Under MPEG test conditions, our methods implemented on HEVC match the VVC-based FCM state-of-the-art, effectively bridging a codec generation gap with minimal runtime overhead relative to SSE-RDO HEVC.
Generalized Regularized Evidential Deep Learning Models: Theory and Comprehensive Evaluation
Dec 27, 2025Evidential deep learning (EDL) models, based on Subjective Logic, introduce a principled and computationally efficient way to make deterministic neural networks uncertainty-aware. The resulting evidential models can quantify fine-grained uncertainty using learned evidence. However, the Subjective-Logic framework constrains evidence to be non-negative, requiring specific activation functions whose geometric properties can induce activation-dependent learning-freeze behavior: a regime where gradients become extremely small for samples mapped into low-evidence regions. We theoretically characterize this behavior and analyze how different evidential activations influence learning dynamics. Building on this analysis, we design a general family of activation functions and corresponding evidential regularizers that provide an alternative pathway for consistent evidence updates across activation regimes. Extensive experiments on four benchmark classification problems (MNIST, CIFAR-10, CIFAR-100, and Tiny-ImageNet), two few-shot classification problems, and blind face restoration problem empirically validate the developed theory and demonstrate the effectiveness of the proposed generalized regularized evidential models.
Feature Compression for Machines with Range-Based Channel Truncation and Frame Packing
Dec 11, 2025This paper proposes a method that enhances the compression performance of the current model under development for the upcoming MPEG standard on Feature Coding for Machines (FCM). This standard aims at providing inter-operable compressed bitstreams of features in the context of split computing, i.e., when the inference of a large computer vision neural-network (NN)-based model is split between two devices. Intermediate features can consist of multiple 3D tensors that can be reduced and entropy coded to limit the required bandwidth of such transmission. In the envisioned design for the MPEG-FCM standard, intermediate feature tensors may be reduced using Neural layers before being converted into 2D video frames that can be coded using existing video compression standards. This paper introduces an additional channel truncation and packing method which enables the system to preserve the relevant channels, depending on the statistics of the features at inference time, while preserving the computer vision task performance at the receiver. Implemented within the MPEG-FCM test model, the proposed method yields an average reduction in rate by 10.59% for a given accuracy on multiple computer vision tasks and datasets.
* 10 pages, 8 figures. Extended version of the paper with the same title presented at IEEE DCC 2025
Efficient Feature Compression for Machines with Global Statistics Preservation
Dec 10, 2025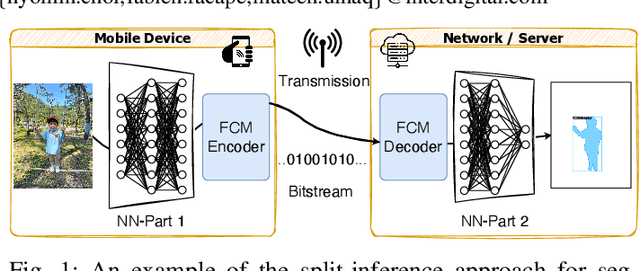
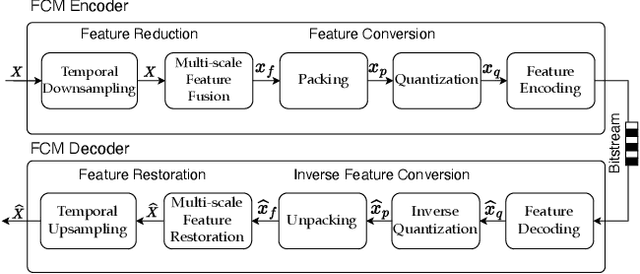
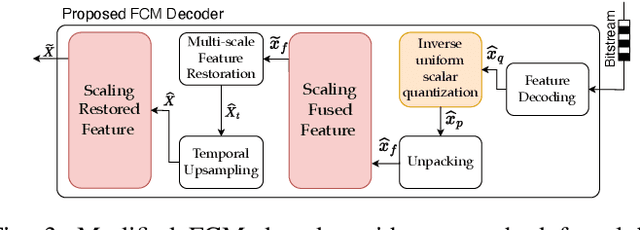
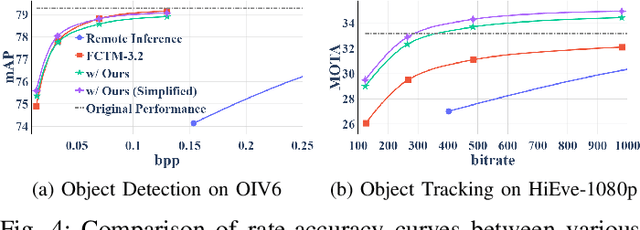
The split-inference paradigm divides an artificial intelligence (AI) model into two parts. This necessitates the transfer of intermediate feature data between the two halves. Here, effective compression of the feature data becomes vital. In this paper, we employ Z-score normalization to efficiently recover the compressed feature data at the decoder side. To examine the efficacy of our method, the proposed method is integrated into the latest Feature Coding for Machines (FCM) codec standard under development by the Moving Picture Experts Group (MPEG). Our method supersedes the existing scaling method used by the current standard under development. It both reduces the overhead bits and improves the end-task accuracy. To further reduce the overhead in certain circumstances, we also propose a simplified method. Experiments show that using our proposed method shows 17.09% reduction in bitrate on average across different tasks and up to 65.69% for object tracking without sacrificing the task accuracy.
Semantics-Guided Generative Image Compression
May 29, 2025Advancements in text-to-image generative AI with large multimodal models are spreading into the field of image compression, creating high-quality representation of images at extremely low bit rates. This work introduces novel components to the existing multimodal image semantic compression (MISC) approach, enhancing the quality of the generated images in terms of PSNR and perceptual metrics. The new components include semantic segmentation guidance for the generative decoder, as well as content-adaptive diffusion, which controls the number of diffusion steps based on image characteristics. The results show that our newly introduced methods significantly improve the baseline MISC model while also decreasing the complexity. As a result, both the encoding and decoding time are reduced by more than 36%. Moreover, the proposed compression framework outperforms mainstream codecs in terms of perceptual similarity and quality. The code and visual examples are available.
A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals
Feb 04, 2025Web refresh crawling is the problem of keeping a cache of web pages fresh, that is, having the most recent copy available when a page is requested, given a limited bandwidth available to the crawler. Under the assumption that the change and request events, resp., to each web page follow independent Poisson processes, the optimal scheduling policy was derived by Azar et al. 2018. In this paper, we study an extension of this problem where side information indicating content changes, such as various types of web pings, for example, signals from sitemaps, content delivery networks, etc., is available. Incorporating such side information into the crawling policy is challenging, because (i) the signals can be noisy with false positive events and with missing change events; and (ii) the crawler should achieve a fair performance over web pages regardless of the quality of the side information, which might differ from web page to web page. We propose a scalable crawling algorithm which (i) uses the noisy side information in an optimal way under mild assumptions; (ii) can be deployed without heavy centralized computation; (iii) is able to crawl web pages at a constant total rate without spikes in the total bandwidth usage over any time interval, and automatically adapt to the new optimal solution when the total bandwidth changes without centralized computation. Experiments clearly demonstrate the versatility of our approach.
Variable-Rate Learned Image Compression with Multi-Objective Optimization and Quantization-Reconstruction Offsets
Feb 29, 2024Achieving successful variable bitrate compression with computationally simple algorithms from a single end-to-end learned image or video compression model remains a challenge. Many approaches have been proposed, including conditional auto-encoders, channel-adaptive gains for the latent tensor or uniformly quantizing all elements of the latent tensor. This paper follows the traditional approach to vary a single quantization step size to perform uniform quantization of all latent tensor elements. However, three modifications are proposed to improve the variable rate compression performance. First, multi objective optimization is used for (post) training. Second, a quantization-reconstruction offset is introduced into the quantization operation. Third, variable rate quantization is used also for the hyper latent. All these modifications can be made on a pre-trained single-rate compression model by performing post training. The algorithms are implemented into three well-known image compression models and the achieved variable rate compression results indicate negligible or minimal compression performance loss compared to training multiple models. (Codes will be shared at https://github.com/InterDigitalInc/CompressAI)
Learned Disentangled Latent Representations for Scalable Image Coding for Humans and Machines
Jan 10, 2023



As an increasing amount of image and video content will be analyzed by machines, there is demand for a new codec paradigm that is capable of compressing visual input primarily for the purpose of computer vision inference, while secondarily supporting input reconstruction. In this work, we propose a learned compression architecture that can be used to build such a codec. We introduce a novel variational formulation that explicitly takes feature data relevant to the desired inference task as input at the encoder side. As such, our learned scalable image codec encodes and transmits two disentangled latent representations for object detection and input reconstruction. We note that compared to relevant benchmarks, our proposed scheme yields a more compact latent representation that is specialized for the inference task. Our experiments show that our proposed system achieves a bit rate savings of 40.6% on the primary object detection task compared to the current state-of-the-art, albeit with some degradation in performance for the secondary input reconstruction task.
Frequency-aware Learned Image Compression for Quality Scalability
Jan 03, 2023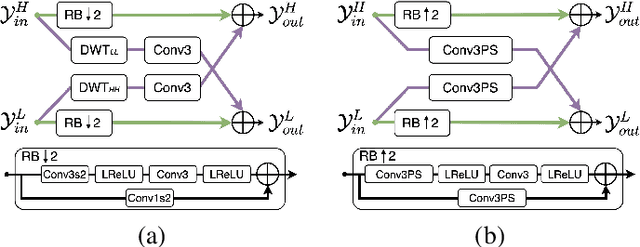
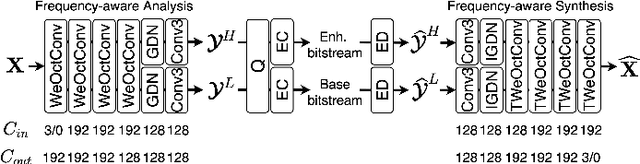

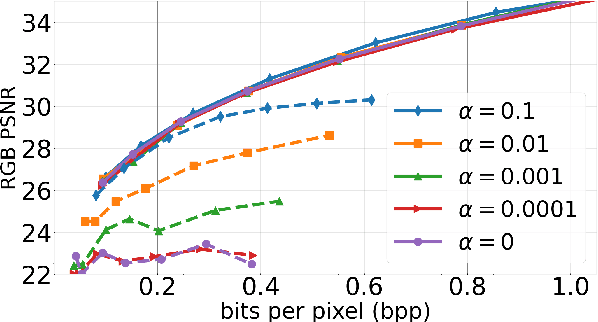
Spatial frequency analysis and transforms serve a central role in most engineered image and video lossy codecs, but are rarely employed in neural network (NN)-based approaches. We propose a novel NN-based image coding framework that utilizes forward wavelet transforms to decompose the input signal by spatial frequency. Our encoder generates separate bitstreams for each latent representation of low and high frequencies. This enables our decoder to selectively decode bitstreams in a quality-scalable manner. Hence, the decoder can produce an enhanced image by using an enhancement bitstream in addition to the base bitstream. Furthermore, our method is able to enhance only a specific region of interest (ROI) by using a corresponding part of the enhancement latent representation. Our experiments demonstrate that the proposed method shows competitive rate-distortion performance compared to several non-scalable image codecs. We also showcase the effectiveness of our two-level quality scalability, as well as its practicality in ROI quality enhancement.