 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Video Coding for Humans and Machines
Paper and Code
Aug 04, 2022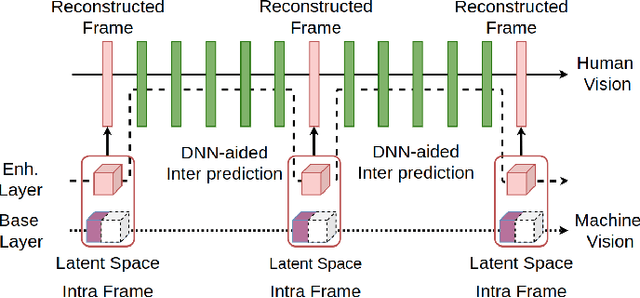

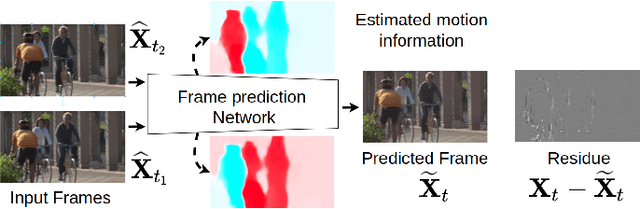

Video content is watched not only by humans, but increasingly also by machines. For example, machine learning models analyze surveillance video for security and traffic monitoring, search through YouTube videos for inappropriate content, and so on. In this paper, we propose a scalable video coding framework that supports machine vision (specifically, object detection) through its base layer bitstream and human vision via its enhancement layer bitstream. The proposed framework includes components from both conventional and Deep Neural Network (DNN)-based video coding. The results show that on object detection, the proposed framework achieves 13-19% bit savings compared to state-of-the-art video codecs, while remaining competitive in terms of MS-SSIM on the human vision task.