 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals
Feb 04, 2025Web refresh crawling is the problem of keeping a cache of web pages fresh, that is, having the most recent copy available when a page is requested, given a limited bandwidth available to the crawler. Under the assumption that the change and request events, resp., to each web page follow independent Poisson processes, the optimal scheduling policy was derived by Azar et al. 2018. In this paper, we study an extension of this problem where side information indicating content changes, such as various types of web pings, for example, signals from sitemaps, content delivery networks, etc., is available. Incorporating such side information into the crawling policy is challenging, because (i) the signals can be noisy with false positive events and with missing change events; and (ii) the crawler should achieve a fair performance over web pages regardless of the quality of the side information, which might differ from web page to web page. We propose a scalable crawling algorithm which (i) uses the noisy side information in an optimal way under mild assumptions; (ii) can be deployed without heavy centralized computation; (iii) is able to crawl web pages at a constant total rate without spikes in the total bandwidth usage over any time interval, and automatically adapt to the new optimal solution when the total bandwidth changes without centralized computation. Experiments clearly demonstrate the versatility of our approach.
Worse WER, but Better BLEU? Leveraging Word Embedding as Intermediate in Multitask End-to-End Speech Translation
May 21, 2020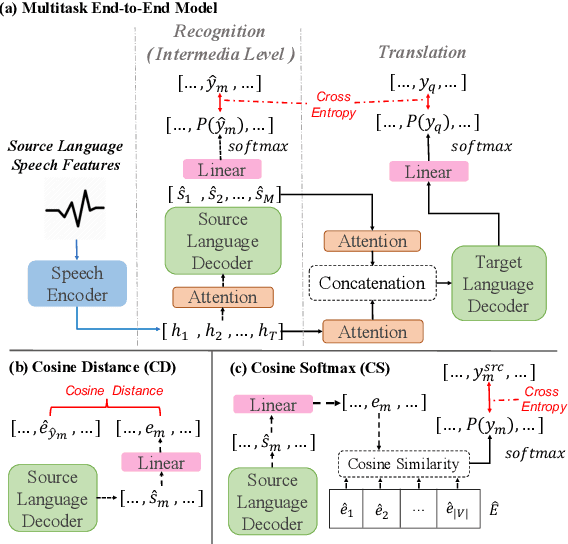

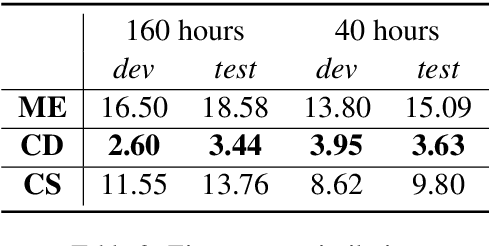
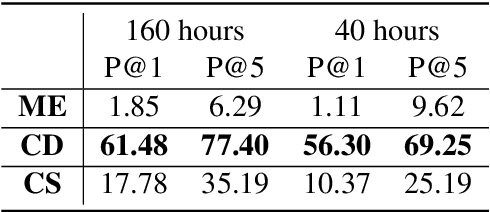
Speech translation (ST) aims to learn transformations from speech in the source language to the text in the target language. Previous works show that multitask learning improves the ST performance, in which the recognition decoder generates the text of the source language, and the translation decoder obtains the final translations based on the output of the recognition decoder. Because whether the output of the recognition decoder has the correct semantics is more critical than its accuracy, we propose to improve the multitask ST model by utilizing word embedding as the intermediate.
Training a code-switching language model with monolingual data
Nov 14, 2019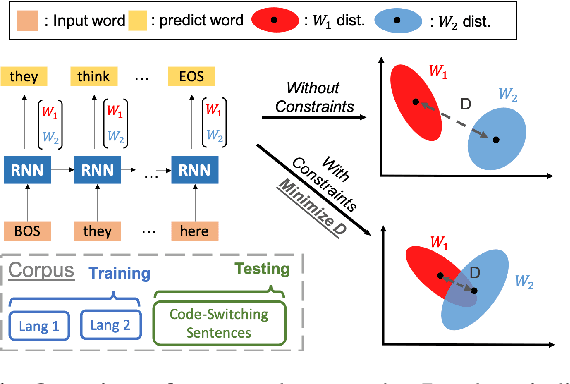
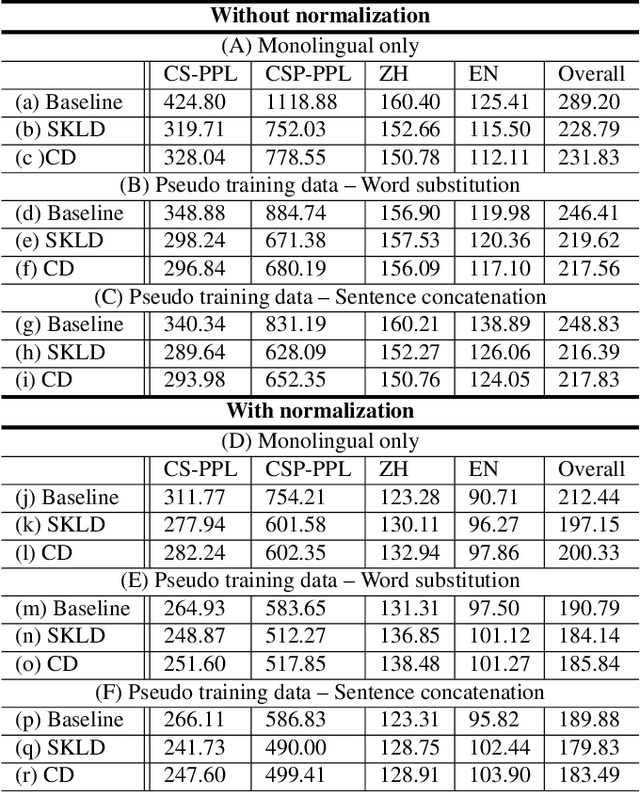
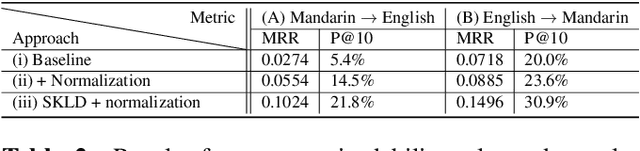
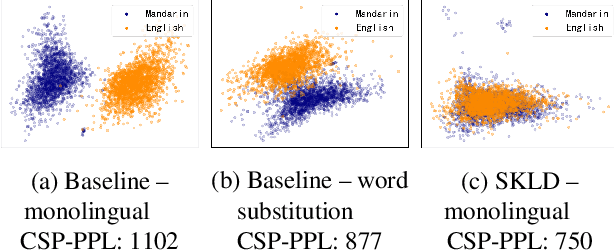
A lack of code-switching data complicates the training of code-switching (CS) language models. We propose an approach to train such CS language models on monolingual data only. By constraining and normalizing the output projection matrix in RNN-based language models, we bring embeddings of different languages closer to each other. Numerical and visualization results show that the proposed approaches remarkably improve the performance of CS language models trained on monolingual data. The proposed approaches are comparable or even better than training CS language models with artificially generated CS data. We additionally use unsupervised bilingual word translation to analyze whether semantically equivalent words in different languages are mapped together.
Sequence-to-sequence Automatic Speech Recognition with Word Embedding Regularization and Fused Decoding
Oct 28, 2019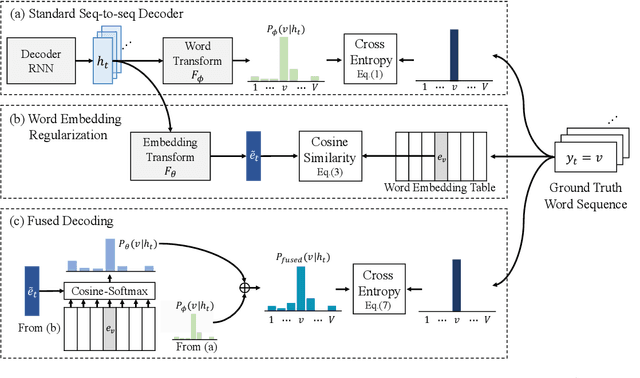

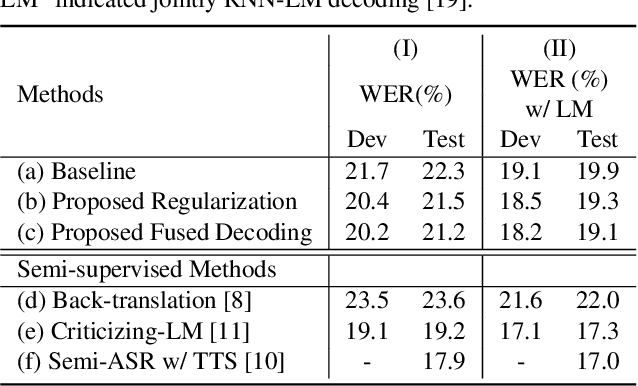
In this paper, we investigate the benefit that off-the-shelf word embedding can bring to the sequence-to-sequence (seq-to-seq) automatic speech recognition (ASR). We first introduced the word embedding regularization by maximizing the cosine similarity between a transformed decoder feature and the target word embedding. Based on the regularized decoder, we further proposed the fused decoding mechanism. This allows the decoder to consider the semantic consistency during decoding by absorbing the information carried by the transformed decoder feature, which is learned to be close to the target word embedding. Initial results on LibriSpeech demonstrated that pre-trained word embedding can significantly lower ASR recognition error with a negligible cost, and the choice of word embedding algorithms among Skip-gram, CBOW and BERT is important.
Personalized word representations Carrying Personalized Semantics Learned from Social Network Posts
Oct 29, 2017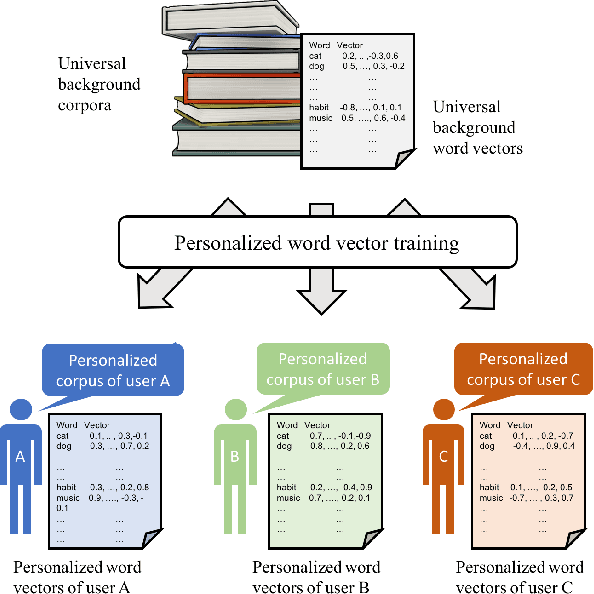
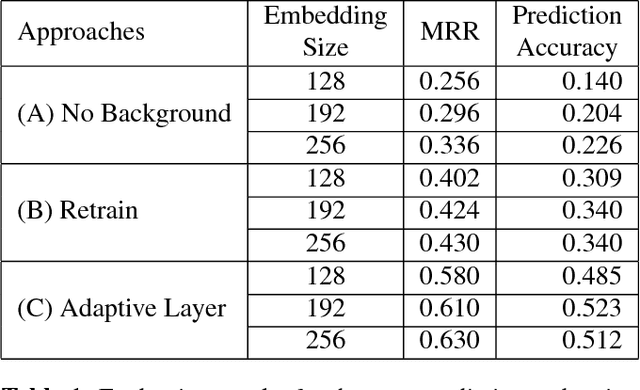
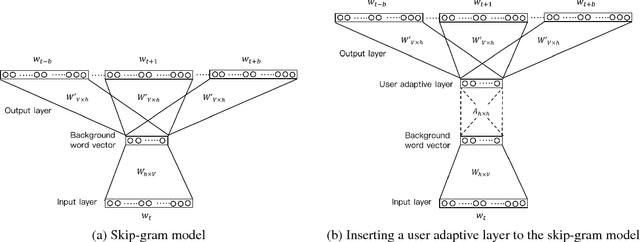
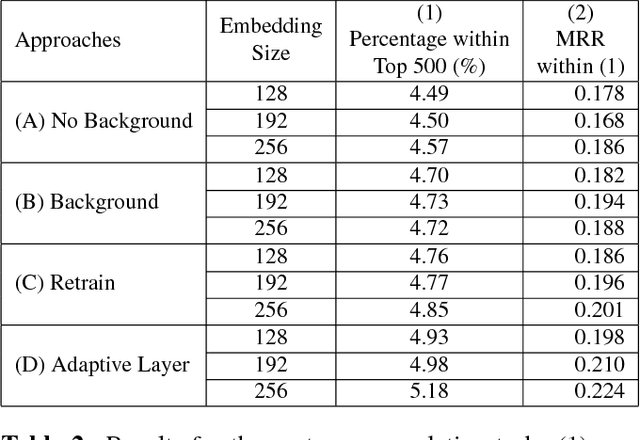
Distributed word representations have been shown to be very useful in various natural language processing (NLP) application tasks. These word vectors learned from huge corpora very often carry both semantic and syntactic information of words. However, it is well known that each individual user has his own language patterns because of different factors such as interested topics, friend groups, social activities, wording habits, etc., which may imply some kind of personalized semantics. With such personalized semantics, the same word may imply slightly differently for different users. For example, the word "Cappuccino" may imply "Leisure", "Joy", "Excellent" for a user enjoying coffee, by only a kind of drink for someone else. Such personalized semantics of course cannot be carried by the standard universal word vectors trained with huge corpora produced by many people. In this paper, we propose a framework to train different personalized word vectors for different users based on the very successful continuous skip-gram model using the social network data posted by many individual users. In this framework, universal background word vectors are first learned from the background corpora, and then adapted by the personalized corpus for each individual user to learn the personalized word vectors. We use two application tasks to evaluate the quality of the personalized word vectors obtained in this way, the user prediction task and the sentence completion task. These personalized word vectors were shown to carry some personalized semantics and offer improved performance on these two evaluation tasks.