 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized word representations Carrying Personalized Semantics Learned from Social Network Posts
Oct 29, 2017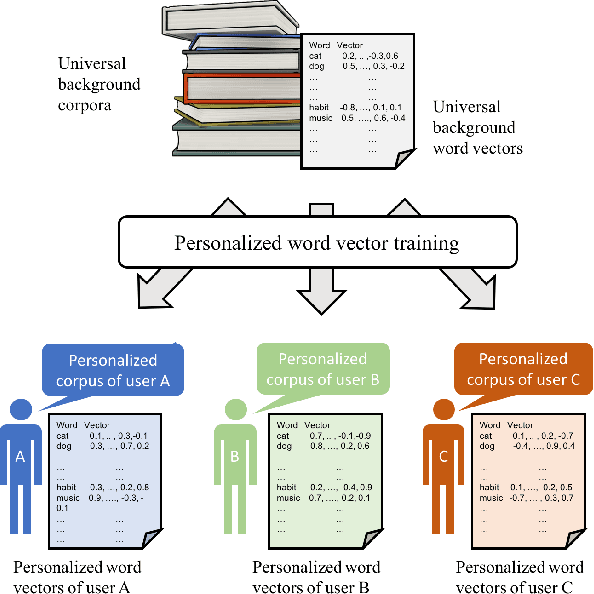
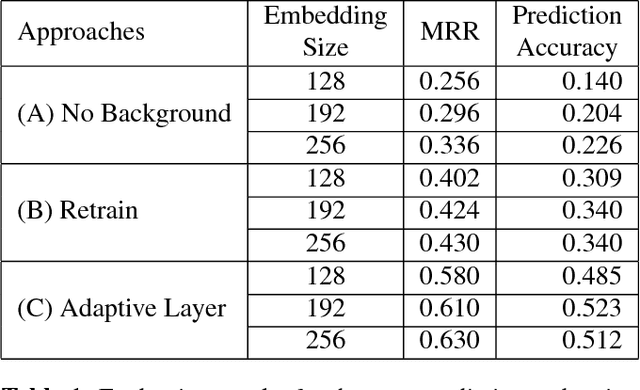
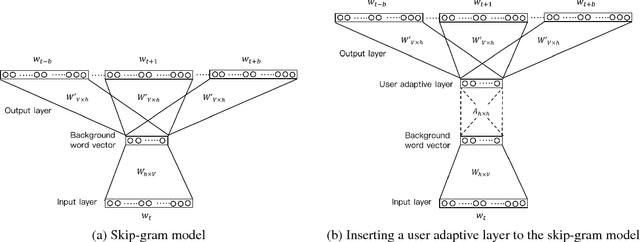
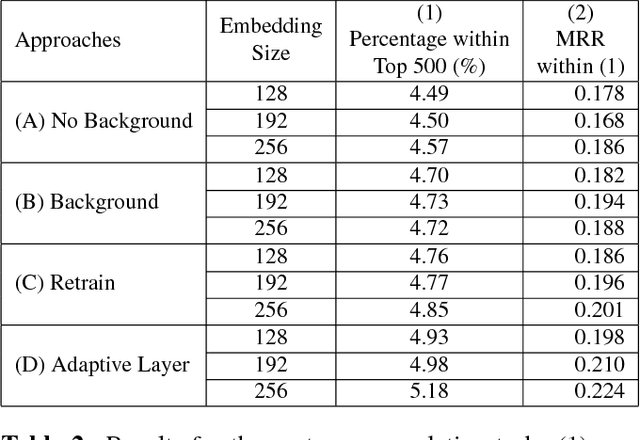
Distributed word representations have been shown to be very useful in various natural language processing (NLP) application tasks. These word vectors learned from huge corpora very often carry both semantic and syntactic information of words. However, it is well known that each individual user has his own language patterns because of different factors such as interested topics, friend groups, social activities, wording habits, etc., which may imply some kind of personalized semantics. With such personalized semantics, the same word may imply slightly differently for different users. For example, the word "Cappuccino" may imply "Leisure", "Joy", "Excellent" for a user enjoying coffee, by only a kind of drink for someone else. Such personalized semantics of course cannot be carried by the standard universal word vectors trained with huge corpora produced by many people. In this paper, we propose a framework to train different personalized word vectors for different users based on the very successful continuous skip-gram model using the social network data posted by many individual users. In this framework, universal background word vectors are first learned from the background corpora, and then adapted by the personalized corpus for each individual user to learn the personalized word vectors. We use two application tasks to evaluate the quality of the personalized word vectors obtained in this way, the user prediction task and the sentence completion task. These personalized word vectors were shown to carry some personalized semantics and offer improved performance on these two evaluation tasks.