 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Discovery of Structured Acoustic Tokens with Applications to Spoken Term Detection
Nov 28, 2017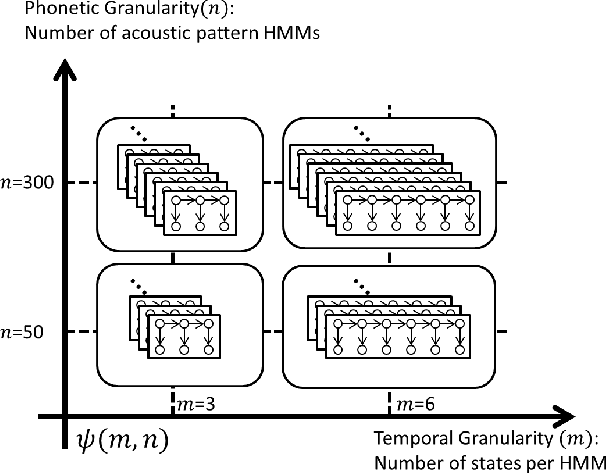
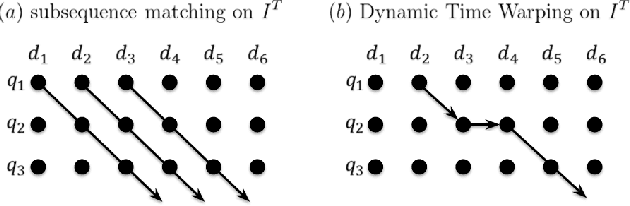
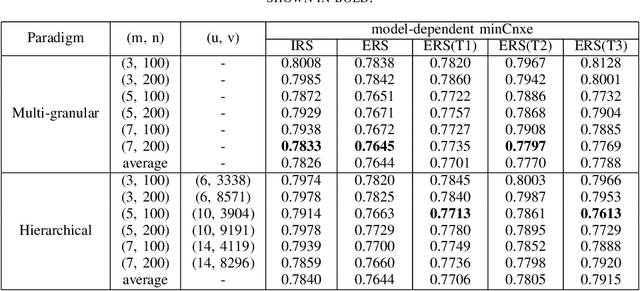
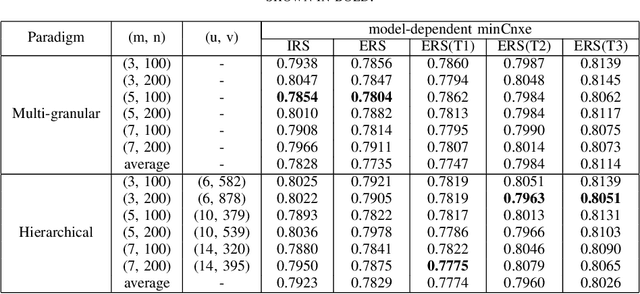
In this paper, we compare two paradigms for unsupervised discovery of structured acoustic tokens directly from speech corpora without any human annotation. The Multigranular Paradigm seeks to capture all available information in the corpora with multiple sets of tokens for different model granularities. The Hierarchical Paradigm attempts to jointly learn several levels of signal representations in a hierarchical structure. The two paradigms are unified within a theoretical framework in this paper. Query-by-Example Spoken Term Detection (QbE-STD) experiments on the QUESST dataset of MediaEval 2015 verifies the competitiveness of the acoustic tokens. The Enhanced Relevance Score (ERS) proposed in this work improves both paradigms for the task of QbE-STD. We also list results on the ABX evaluation task of the Zero Resource Challenge 2015 for comparison of the Paradigms.
Personalized word representations Carrying Personalized Semantics Learned from Social Network Posts
Oct 29, 2017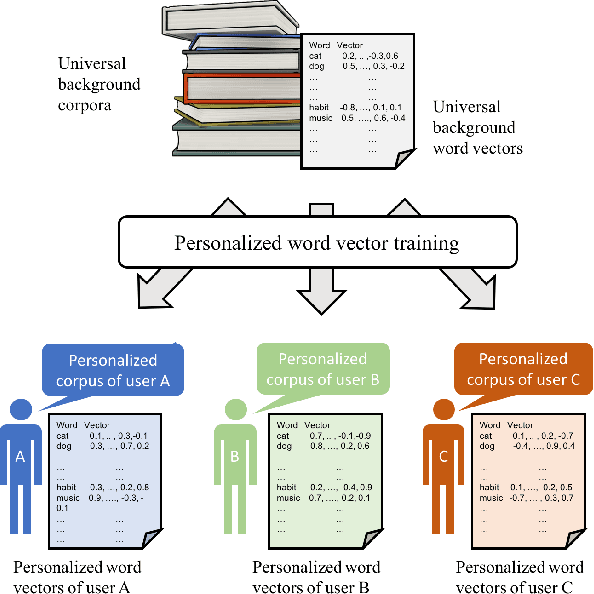
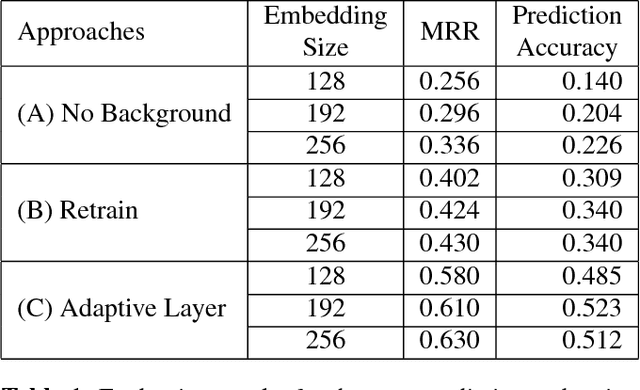
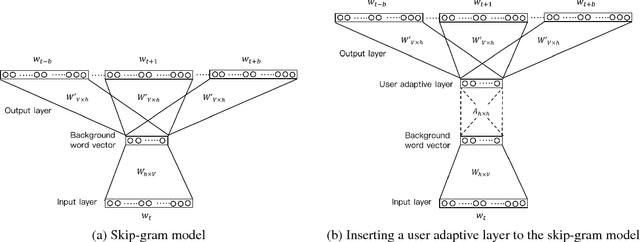
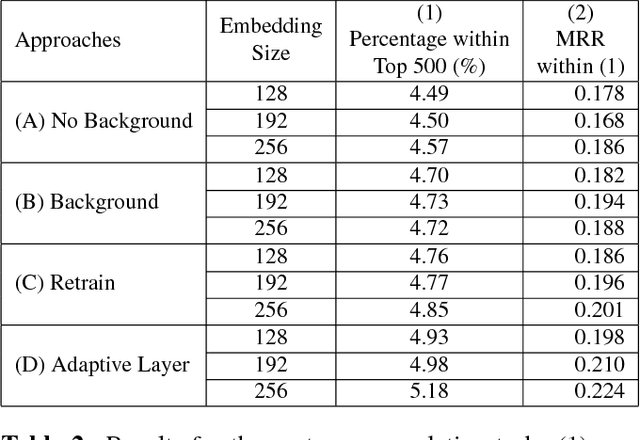
Distributed word representations have been shown to be very useful in various natural language processing (NLP) application tasks. These word vectors learned from huge corpora very often carry both semantic and syntactic information of words. However, it is well known that each individual user has his own language patterns because of different factors such as interested topics, friend groups, social activities, wording habits, etc., which may imply some kind of personalized semantics. With such personalized semantics, the same word may imply slightly differently for different users. For example, the word "Cappuccino" may imply "Leisure", "Joy", "Excellent" for a user enjoying coffee, by only a kind of drink for someone else. Such personalized semantics of course cannot be carried by the standard universal word vectors trained with huge corpora produced by many people. In this paper, we propose a framework to train different personalized word vectors for different users based on the very successful continuous skip-gram model using the social network data posted by many individual users. In this framework, universal background word vectors are first learned from the background corpora, and then adapted by the personalized corpus for each individual user to learn the personalized word vectors. We use two application tasks to evaluate the quality of the personalized word vectors obtained in this way, the user prediction task and the sentence completion task. These personalized word vectors were shown to carry some personalized semantics and offer improved performance on these two evaluation tasks.
Unsupervised Iterative Deep Learning of Speech Features and Acoustic Tokens with Applications to Spoken Term Detection
Jul 17, 2017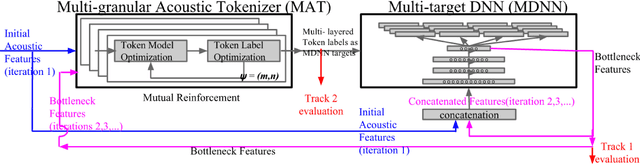
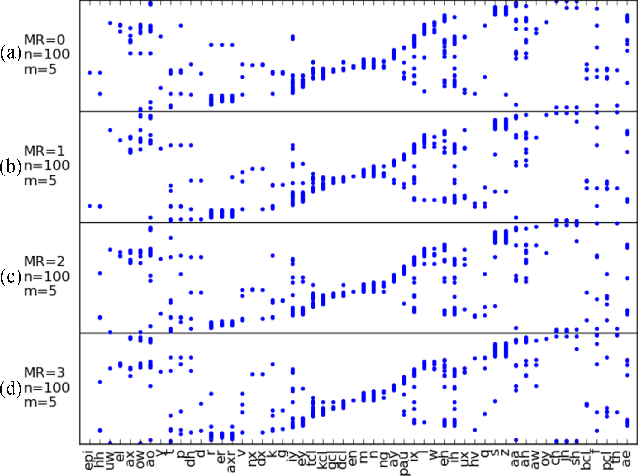
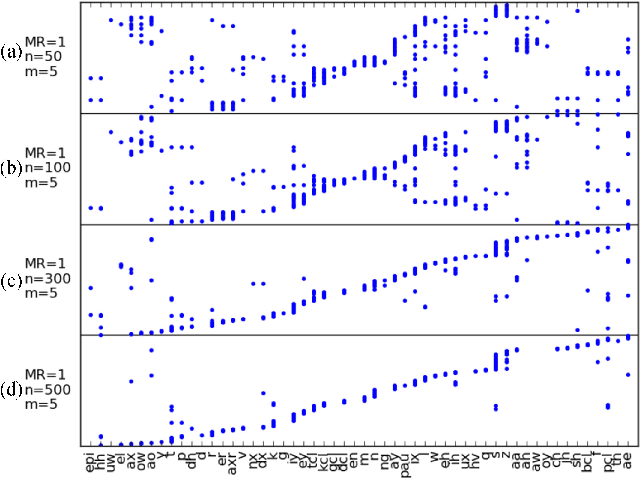
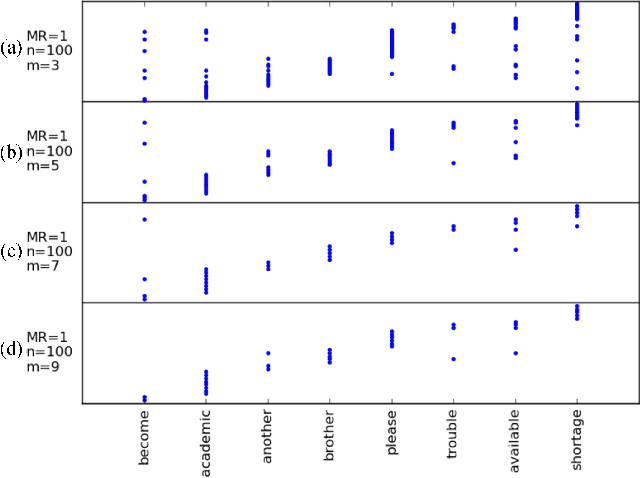
In this paper we aim to automatically discover high quality frame-level speech features and acoustic tokens directly from unlabeled speech data. A Multi-granular Acoustic Tokenizer (MAT) was proposed for automatic discovery of multiple sets of acoustic tokens from the given corpus. Each acoustic token set is specified by a set of hyperparameters describing the model configuration. These different sets of acoustic tokens carry different characteristics for the given corpus and the language behind, thus can be mutually reinforced. The multiple sets of token labels are then used as the targets of a Multi-target Deep Neural Network (MDNN) trained on frame-level acoustic features. Bottleneck features extracted from the MDNN are then used as the feedback input to the MAT and the MDNN itself in the next iteration. The multi-granular acoustic token sets and the frame-level speech features can be iteratively optimized in the iterative deep learning framework. We call this framework the Multi-granular Acoustic Tokenizing Deep Neural Network (MATDNN). The results were evaluated using the metrics and corpora defined in the Zero Resource Speech Challenge organized at Interspeech 2015, and improved performance was obtained with a set of experiments of query-by-example spoken term detection on the same corpora. Visualization for the discovered tokens against the English phonemes was also shown.
Hierarchical Attention Model for Improved Machine Comprehension of Spoken Content
Jan 01, 2017
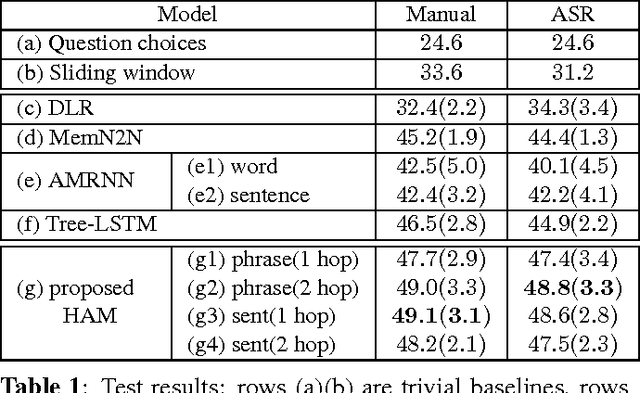
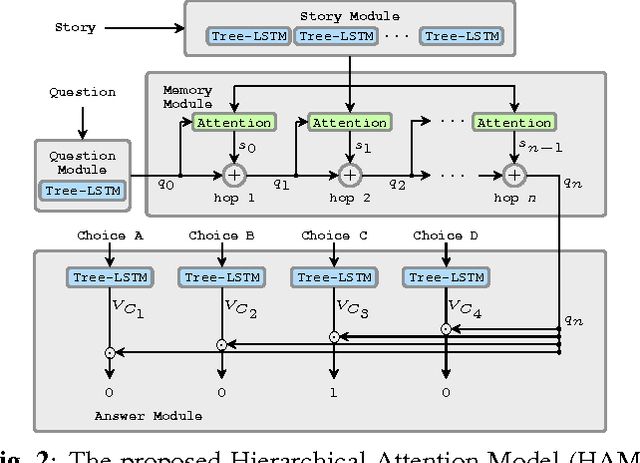
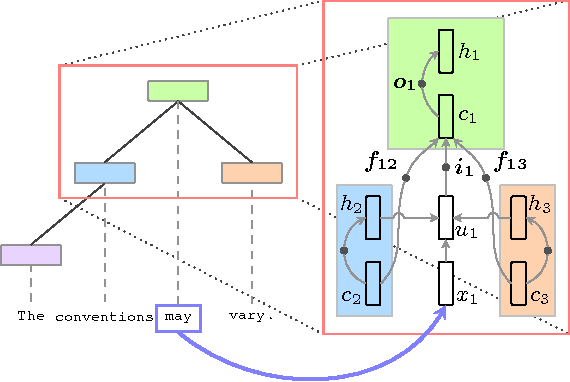
Multimedia or spoken content presents more attractive information than plain text content, but the former is more difficult to display on a screen and be selected by a user. As a result, accessing large collections of the former is much more difficult and time-consuming than the latter for humans. It's therefore highly attractive to develop machines which can automatically understand spoken content and summarize the key information for humans to browse over. In this endeavor, a new task of machine comprehension of spoken content was proposed recently. The initial goal was defined as the listening comprehension test of TOEFL, a challenging academic English examination for English learners whose native languages are not English. An Attention-based Multi-hop Recurrent Neural Network (AMRNN) architecture was also proposed for this task, which considered only the sequential relationship within the speech utterances. In this paper, we propose a new Hierarchical Attention Model (HAM), which constructs multi-hopped attention mechanism over tree-structured rather than sequential representations for the utterances. Improved comprehension performance robust with respect to ASR errors were obtained.
Personalizing Universal Recurrent Neural Network Language Model with User Characteristic Features by Social Network Crowdsouring
Nov 22, 2016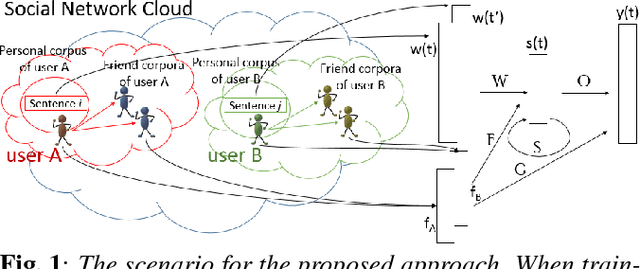

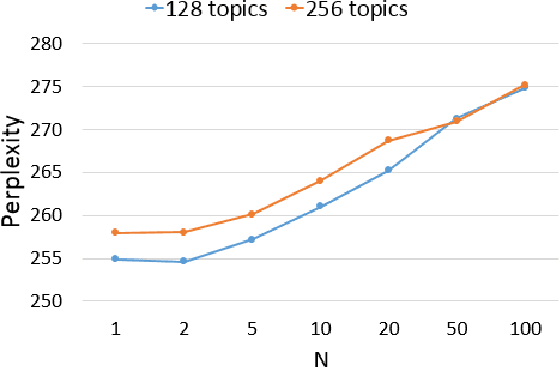
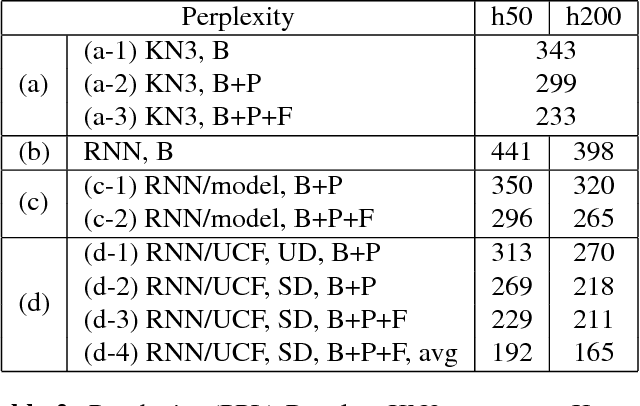
With the popularity of mobile devices, personalized speech recognizer becomes more realizable today and highly attractive. Each mobile device is primarily used by a single user, so it's possible to have a personalized recognizer well matching to the characteristics of individual user. Although acoustic model personalization has been investigated for decades, much less work have been reported on personalizing language model, probably because of the difficulties in collecting enough personalized corpora. Previous work used the corpora collected from social networks to solve the problem, but constructing a personalized model for each user is troublesome. In this paper, we propose a universal recurrent neural network language model with user characteristic features, so all users share the same model, except each with different user characteristic features. These user characteristic features can be obtained by crowdsouring over social networks, which include huge quantity of texts posted by users with known friend relationships, who may share some subject topics and wording patterns. The preliminary experiments on Facebook corpus showed that this proposed approach not only drastically reduced the model perplexity, but offered very good improvement in recognition accuracy in n-best rescoring tests. This approach also mitigated the data sparseness problem for personalized language models.
Interactive Spoken Content Retrieval by Deep Reinforcement Learning
Sep 16, 2016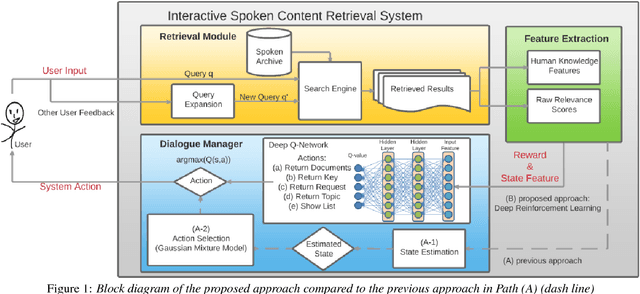
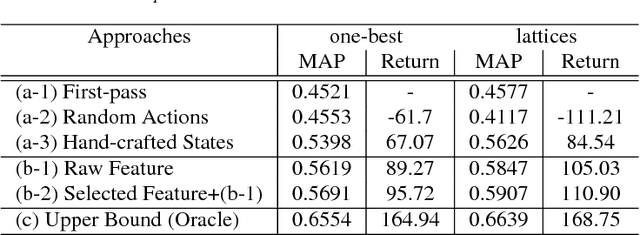
User-machine interaction is important for spoken content retrieval. For text content retrieval, the user can easily scan through and select on a list of retrieved item. This is impossible for spoken content retrieval, because the retrieved items are difficult to show on screen. Besides, due to the high degree of uncertainty for speech recognition, the retrieval results can be very noisy. One way to counter such difficulties is through user-machine interaction. The machine can take different actions to interact with the user to obtain better retrieval results before showing to the user. The suitable actions depend on the retrieval status, for example requesting for extra information from the user, returning a list of topics for user to select, etc. In our previous work, some hand-crafted states estimated from the present retrieval results are used to determine the proper actions. In this paper, we propose to use Deep-Q-Learning techniques instead to determine the machine actions for interactive spoken content retrieval. Deep-Q-Learning bypasses the need for estimation of the hand-crafted states, and directly determine the best action base on the present retrieval status even without any human knowledge. It is shown to achieve significantly better performance compared with the previous hand-crafted states.
Towards Machine Comprehension of Spoken Content: Initial TOEFL Listening Comprehension Test by Machine
Aug 23, 2016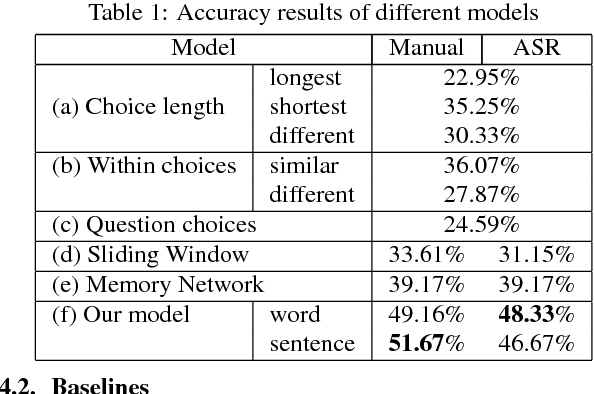
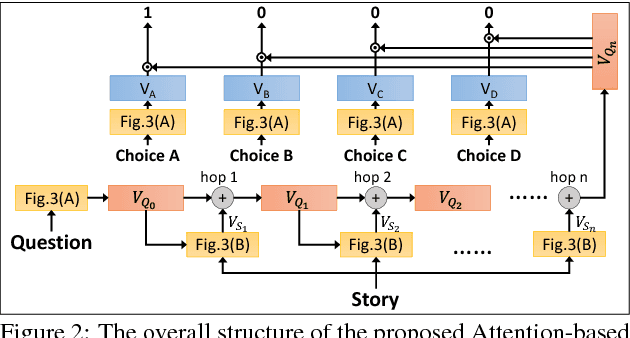
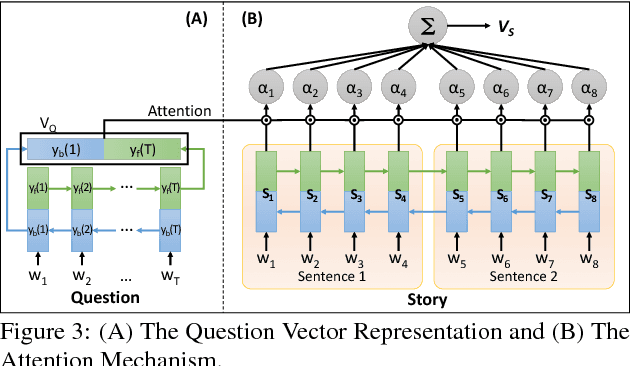

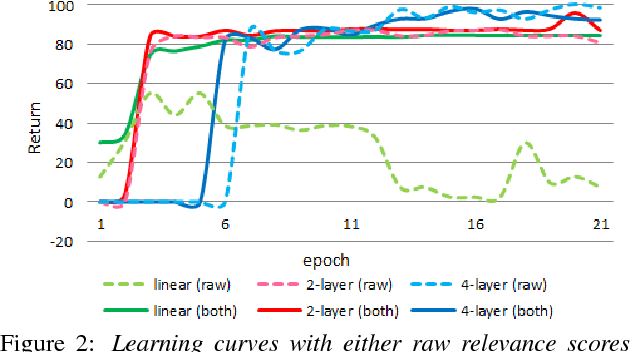
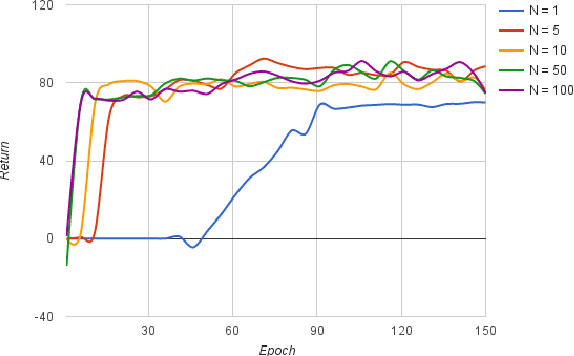
Multimedia or spoken content presents more attractive information than plain text content, but it's more difficult to display on a screen and be selected by a user. As a result, accessing large collections of the former is much more difficult and time-consuming than the latter for humans. It's highly attractive to develop a machine which can automatically understand spoken content and summarize the key information for humans to browse over. In this endeavor, we propose a new task of machine comprehension of spoken content. We define the initial goal as the listening comprehension test of TOEFL, a challenging academic English examination for English learners whose native language is not English. We further propose an Attention-based Multi-hop Recurrent Neural Network (AMRNN) architecture for this task, achieving encouraging results in the initial tests. Initial results also have shown that word-level attention is probably more robust than sentence-level attention for this task with ASR errors.
Audio Word2Vec: Unsupervised Learning of Audio Segment Representations using Sequence-to-sequence Autoencoder
Jun 11, 2016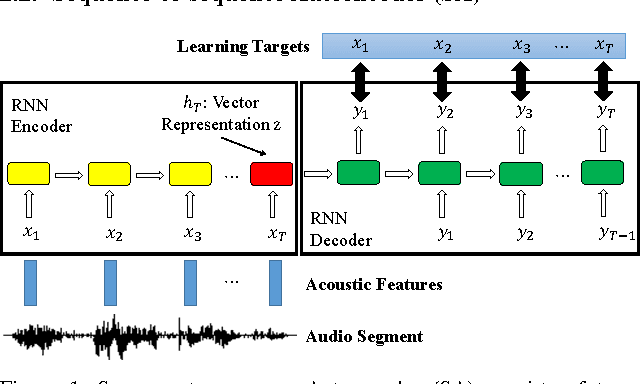
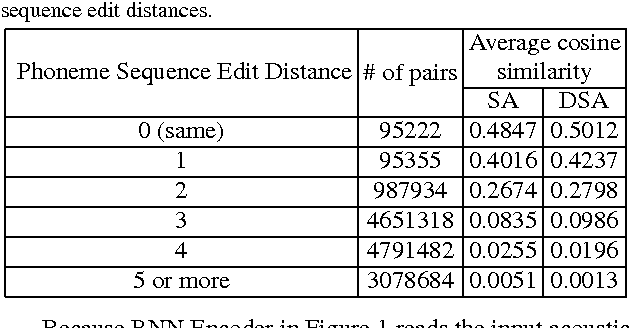
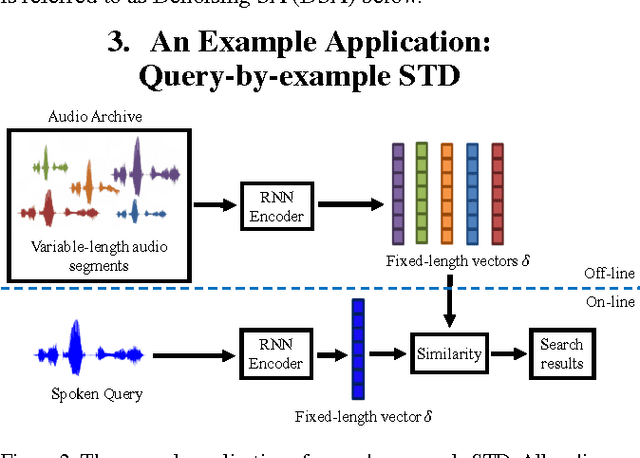
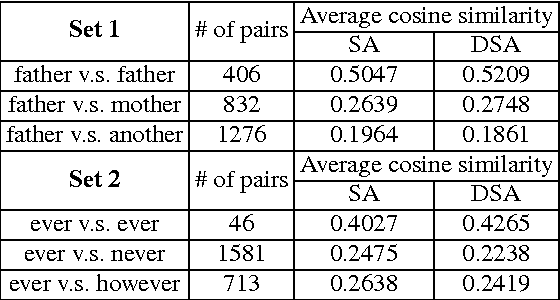
The vector representations of fixed dimensionality for words (in text) offered by Word2Vec have been shown to be very useful in many application scenarios, in particular due to the semantic information they carry. This paper proposes a parallel version, the Audio Word2Vec. It offers the vector representations of fixed dimensionality for variable-length audio segments. These vector representations are shown to describe the sequential phonetic structures of the audio segments to a good degree, with very attractive real world applications such as query-by-example Spoken Term Detection (STD). In this STD application, the proposed approach significantly outperformed the conventional Dynamic Time Warping (DTW) based approaches at significantly lower computation requirements. We propose unsupervised learning of Audio Word2Vec from audio data without human annotation using Sequence-to-sequence Audoencoder (SA). SA consists of two RNNs equipped with Long Short-Term Memory (LSTM) units: the first RNN (encoder) maps the input audio sequence into a vector representation of fixed dimensionality, and the second RNN (decoder) maps the representation back to the input audio sequence. The two RNNs are jointly trained by minimizing the reconstruction error. Denoising Sequence-to-sequence Autoencoder (DSA) is furthered proposed offering more robust learning.
Enhancing Automatically Discovered Multi-level Acoustic Patterns Considering Context Consistency With Applications in Spoken Term Detection
Sep 07, 2015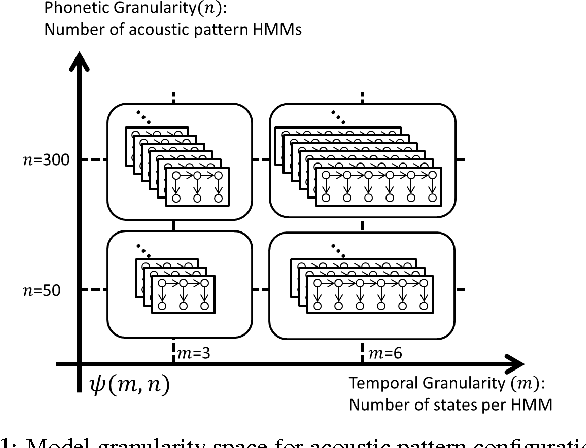
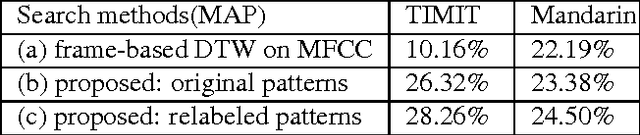
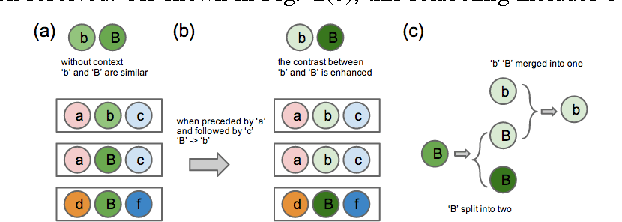
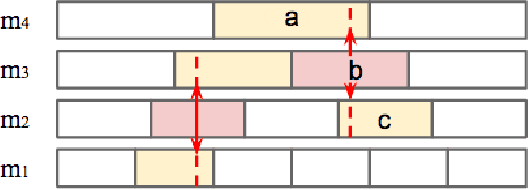
This paper presents a novel approach for enhancing the multiple sets of acoustic patterns automatically discovered from a given corpus. In a previous work it was proposed that different HMM configurations (number of states per model, number of distinct models) for the acoustic patterns form a two-dimensional space. Multiple sets of acoustic patterns automatically discovered with the HMM configurations properly located on different points over this two-dimensional space were shown to be complementary to one another, jointly capturing the characteristics of the given corpus. By representing the given corpus as sequences of acoustic patterns on different HMM sets, the pattern indices in these sequences can be relabeled considering the context consistency across the different sequences. Good improvements were observed in preliminary experiments of pattern spoken term detection (STD) performed on both TIMIT and Mandarin Broadcast News with such enhanced patterns.